Brian Bentow
CS152
Neural Network Based
Predator-Prey Multi-Agent Systems Trained
Using Online Neuro-Evolution
Introduction
In situations where it is not possible
or desirable to use back-propagation for training a neural net, one may resort
to reinforcement learning. For example, if the input to the network is known
and the desired output is unknown, it is not possible to use back-propagation. Fortunately,
there are many other ways to modify the weights of neural networks which is essentially searching a solution space.
Reinforcement
learning trains a network using on a reward system for the resulting behavior
of the neural network over time. One type of reinforcement learning is Neuro-Evolution. Using evolutionary operators such as
mutation and crossovers it is possible to search the solution space exhaustively.
In order to use neuro-evolution, one needs to define
a fitness function for individual neural networks and implement evolutionary
operators as described above. Although this may seem pretty straightforward, the
use of neuro-evolution to search a solution space has
its own difficulties such as finding the optimal parameters that drive the
evolution and finding a metric that can be used to create the input to the
neural network.
From
researching online and offline neuro-evolution, I
came across a paper that was able to successfully train agents to find and
select between two gold mines based on proximity and danger in reaching them.
In this paper, the authors were able to demonstrate that the network learned to
handle a non-trivial task. Also, the authors came up with a reasonable metric
for creating the inputs to the neural network based on the agents’ surroundings.
In my experiment, I will be using that metric and assume it is possible to
train a single agent system to handle some non-trivial task. I want to
demonstrate that it is possible to train competitive neural net based agents
evaluated by different fitness functions simultaneously.
Development
11/17/04
– submitted project proposal
11/23/04
– Started implementation of the infrastructure for the commandline
version of the application called TestArena.
11/26/04
– I began learning how to use JAVA Swing and building applets.
11/28/04
– 12/8/04 – Finished testing and implementation
12/9/04
– 12/14/04 – Documentation and further testing
Experiment
Sheep/Wolves/Grass
In
my experiment, I plan to use two types of agents, sheep and wolves, and a
stationary nutrient, grass. In order to evolve my population of agents, I have
developed the fitness functions below. Every epochLength
iterations, I compute the fitness of each individual and perform one round of
evolution. In order to ensure that a fit agent’s solution is general, I place
agents and grass randomly at the start of each epoch. As a result, the fitness
of the best individual varies between iterations by a significant degree.
However, I did find that the average fitness of the best individual increases
over time.
The
visible arena that the agents inhabit is finite. When the number of agents
changes, I scale the viewable and actual size of the agents appropriately. This
has the effect of normalizing runs with different parameters. I found that
without normalization, increasing the number of agents has inherent problems.
For example, if there is an abundance of sheep, the wolves may not need to
learn to move around because sheep run into them. Also, I found that having too
many or too few sheep in relation to wolves is inhibits agents learning. Using
a ratio of 10 to 2 to 1 sheep to wolves to grass seems to be about right. It is
a good idea to experiment with these parameters and watch the sheep and wolves
behavior before running a long experiment.
The
metric I used for capturing information about an agent’s environment was taken
directly from the “Online Neuro-Evolution” paper. The
paper describes calculating the average distance to entities in each of 4 directions:
east, west, north and south. Each direction takes up 90 degrees of an agent’s
360 degree field of view. Although this metric does not directly inform the
agent of the closest entity in a particular direction, it does contain some
information about the world from the agent’s perspective. More verbose metrics
could be used such as including the number of entities in a specific direction
or also include the minimum distance to an entity of a certain type. Due to the
computationally intensive nature of evolutionary algorithms and using a neural
network for each agent, I chose simple metric for the paper due to its ease of
calculation and amount of information it provides. It is important to note that
the authors of the paper were successful in training agents using that metric.
However, in their experiments, they had only a few entities where as I have
potentially hundreds of entities in relation to an agent. In the future, I may
try using a different metric. Unfortunately, using a more verbose metric will
have significant performance costs to an algorithm that is inherently O(n2) for collision detection
and neural net layer dimensions. When matrices become large enough that they do
not fit in the cache, unless optimizations are used, extremely poor cache
performance results and the program becomes incredibly slow.
Sheep
Fitness Function = f (foodconsumed, number of times bitten, overeating penalty)
Sheep live on a pasture that is periodically attacked
by wolves. If a large herd of sheep gather on an area of grass, individual
sheep consume nutrients at a slower rate. However, if the sheep venture to new
areas alone it is more likely that the wolves will select them for consumption.
Wolves
Fitness function – f(bites of
sheep, overeating penalty)
Wolves attack sheep and for my experiment I will vary
the relative speed of sheep relative to wolves. I plan to place constraints on
the wolves such that cooperation among wolves is necessary in order to kill a
sheep. For example, I may require at least 2 wolves to approach a sheep in
order to kill that sheep. However, the number of wolves that kill a sheep causes
the reward to be split between the individual wolves.
Fitness Smoothing
I average the fitness of a
single individual over multiple epochs in order to prevent agents that have
survived multiple epochs from being replaced prematurely.
Food Consumption
Sheep and wolves can only
eat one morsel of food per time step which I argue makes quite a bit of sense.
I found that if sheep can eat more than 1 morsel of grass per time step, in
cases where grass patches overlap, sheep have an unfair advantage in comparison
to other configurations. Also, sometimes sheep tend to clump in one area and
wolves in that area have an unfair advantage. It is important to note that I
relocate sheep after they have been bitten once.
Hypothesis
Over time, the two
populations of agents will elicit different strategies. I conjecture that given
a set of run parameters, the agents in populations will converge to optimal
strategies to each other. I do expect that initially the populations will have
quite varied behavior. Also, I expect to find the animals to develop different
strategies based on their innate abilities (i.e. speed).
Applet
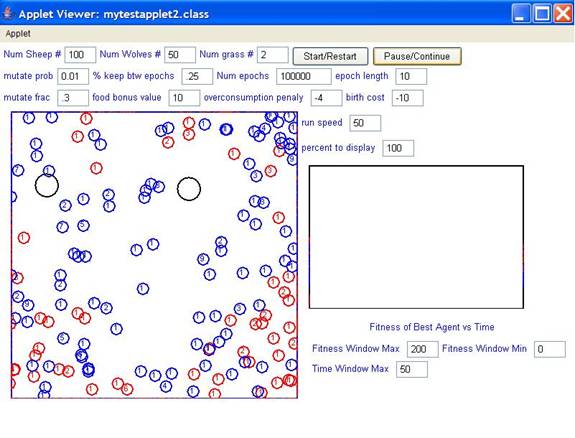
Figure 1: Screen shot of SheepVWolves Applet
Sheep
– blue
Wolves
– red
Grass
– black
Numbers
correspond to the age of the agent. Agents move across the screen autonomously.
In
order to try the applet go to:
www.cs.hmc.edu/~bbentow/sheepvwolves.html
Applet
User Guide
The parameters below can be
tweaked. One of the nice features of the applet is the ability to speed up or
slow down a run in the middle of that run. This can be done by pausing the run, changing the run speed or percent to
display and continuing the run. One can also tweak other parameters during the
run. However, the num of the respective agents will only be modified when the
run is restarted.
All parameters
These parameters will only
take effect after Start/Restart is pressed.
Num Sheep - blue circles,
number of sheep in run
Num Wolves - red circles, number of wolves in a run
Num Grass - black circles, number of grass units in run
Online Neuro
– Evolution Parameters
These parameters will take
effect after either Start/Restart or Pause/Continue is pressed when the run
resumes.
Epoch Length – number of
iterations in an epoch
Birth Cost – penalty for
each time a sheep is bitten
Food Bonus Value – reward
for each time a sheep eats grass for 1 time step
OverConsumption Penalty – not currently used
Mutate frac
– % to mutate rather than replace using crossover
% keep
btw epochs – % of individuals to keep for each run
Num epochs – number of
epochs for the run
Mutate prob
– not currently used
Run speed – controls the
rate of painting
Percent to display –
controls the number of epochs that are display
Graphing Fitness of Best
Individuals over Time Parameters
Time Window Max – number of
time steps displayed at a time
Fitness Window Max – maximum
viewable fitness graphed
Fitness Window Min – minimum
viewable fitness graphed
User Interaction
The applet is multi-threaded
in order to allow the user to make changes in the user interface while the
computationally intensive portion of the applet runs. One may find it agreeable
to pause a run when one needs the cpu
to complete a high priority task and then resume the run when that task is
completed. Although it is possible to suspend a thread when the applet is
minimized, I prefer to be able to let the applet run even if it is minimized.
Configurable Parameters
Parameters can be modified
during a run. For example, one can simply pause the
current run, tweak some parameters, and then continue a run which will use the
new parameters. This can be extremely useful if one wants to evolve a
population while not watching the applet. In this case, evolution may proceed
much more quickly because the time consuming drawing phase is skipped.
Additionally, one can increase or decrease the speed of the drawing phase so
that users can watch the action at a pace that is agreeable to them.
Results
Quantitative
Analysis
Graphs
The
numerical values that are output next to the lines are the respective ages of
the best sheep (blue) or wolf (red) in a specific epoch.
Fitness of Individuals Over Time
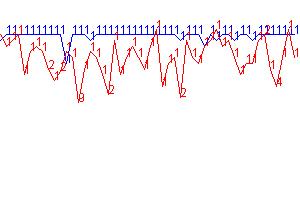
Figure 2: y axis - fitness max = 350, fitness min = 0,
x axis
– epoch 6158 to 6208, Run parameters were - Num wolves =100 Num sheep = 250 Num
grass = 210 mutateFrac = 0.3 mutateRate
= 0.01 epochLength = 30 foodBonus
= 10.0 overconsumptionPenalty = -4.0
In
this run, there is quite a bit of grass so the sheep are able to achieve
maximal fitness for this configuration in many runs. I have found that the
wolves are only able to reach maximal fitness routinely when there are
approximately 5 sheep to every wolf.
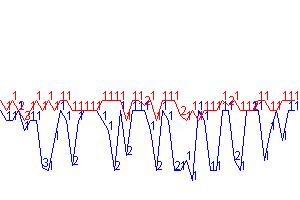
Figure 3:
y axis - fitness max
= 200, fitness min = 0,
x axis
– epoch 1224 to 1274, Run parameters were - Num wolves =50 Num sheep = 100 Num
grass = 22 mutateFrac = 0.3 mutateRate
= 0.01 epochLength = 10 foodBonus
= 10.0 overconsumptionPenalty = -4.0
In
this run, grass is relatively sparse. The sheep have much more difficulty
finding the grass. One might expect that the fitness of wolves and sheep would
have some sort of inverse relationship because when a wolf bites a sheep, the
sheep loses birthCost fitness points and the wolf
gains foodBonus points. It’s not clear from this
graph whether the best sheep are unable to find the grass or are being bitten
repeatedly to account for low fitness in some cases.
It
is important to note that there are definitely solutions that survive multiple
epochs. However, I have found that those solutions’ fitness decrease over time.
On average, best individuals with age 1 have higher
fitness than individuals with age 1+.
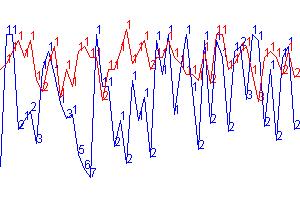
Figure 4
y axis - fitness max = 350, fitness min = 0,
x axis
– epoch 1224 to 1274, Run parameters were - Num wolves =100 Num sheep = 80 Num
grass = 22 mutateFrac = 0.3 mutateRate
= 0.01 epochLength = 30 foodBonus
= 10.0 overconsumptionPenalty = -4.0
Qualitative
Analysis
Both
the wolves and sheep exhibit varying behavior as new solutions are generated.
Unfortunately, solutions survive usually in just a few configurations (<
10). Some individuals last a few generations which lends credibility to the
assertion that somewhat general solutions are being generated. However, there
is still quite a bit of room for improvement. One would hope that functions
would be successful and general enough to survive many epochs. It is currently
my belief that the runs need to be made more difficult by increasing the number
of iterations per epoch and increasing the number of sheep and wolves while
decreasing the number of grass entities. Due to the computationally intensive
nature of the applet, runs of this nature could take days to complete.
Because
I use a fairly concise metric for the current arena configuration with respect
to a sheep or wolf, I would not expect any function to be generated that
performs perfectly in the arena. By watching the behavior of the sheep and
wolves over generations, one can see that they are doing sensible things. For
example, the wolves will approach and mow down a series of sheep. In addition,
some sheep move toward grass and stop as expected. In this way, the results are
encouraging.
Original
Research Goals
- Develop a neural net
based simulation of co-evolving populations and demonstrate its
functionality in an applet.
- Allow the user to set
the start and vary a large number of parameters for instructive and
experimental purposes.
Features
- Debug Mode using log4j
- Multi-threading
- Pausing current run
- Configuring parameters during a run
- Using a debug version, I output the fitness
window as a jpeg at regular intervals for passive run watch
Issues
Logging
Logging must be turned off
when running the applet outside of eclipse. Because applets are not allowed to
read files on the local disk, logging using log4j is not possible in the
production environment.
Multi-threading issues
Sometimes when a thread is
suspended or the user quits the applet, the applet crashes. This is not a major
issue because the user can kill the browser or appletviewer
as necessary. This bug is due to the fact that thread operations are inherently
not safe in the as described in the java API.
Tools
- Log4j
- Eclipse
- Online tutorials and resources
Time Spent – 40 – 60 hours
Code
Eclipse project with source code
Conclusion
Initially, I developed an
extremely complicated design that involved a particle engine and agent
collisions, interaction between agents of the same species, and complicated
fitness functions based on additional parameters such as health and distance
traveled by the agent. However, due to time constraints, I was forced to
simplify my design. I was able to develop a pretty decent applet in a moderate
amount of time.
Feasibility,
Future Enhancements
- Add additional evolutionary operators
- Turn off drawing when the applet is minimized
automatically
- Find a way to display relevant data such as best
fitness so far
Research
Achievements
- Developed a versatile applet that allows users
to explore and learn about neuro-evolution.
- Determined the feasibility of co-evolution of
multi-agent systems.
References
Agogino, Adrian & Miikkulainen,
Risto & Stanley, Kenneth. (1999) “Online Interactive Neuro-evolution.” (available
online)
http://www.aiathome.com/articles/online_neuro_evolution.pdf
Perez, Andres. “Introduction
to Reinforcement learning.” http://lslwww.epfl.ch/~anperez/RL/RL.html
Briggs,
Code resources
A Visual Guide to Layout
Managers http://java.sun.com/docs/books/tutorial/uiswing/layout/visual.html
Java2D: An
Introduction and Tutorial
http://javaboutique.internet.com/tutorials/Java2D/page06.html
Validating
Numerical Input in a JTextField
http://java.sun.com/developer/JDCTechTips/2001/tt1120.html
http://www.apl.jhu.edu/~hall/java/Swing-Tutorial/
Swing: A Quick Tutorial for
AWT Programmers
Creating a GUI with
JFC/Swing
http://www.redbrick.dcu.ie/help/reference/java/uiswing/