The world wide web is a huge, grossly disorganized, information and entertainment resource. Early efforts to manage the whole mess, such as Yahoo, a searchable, hierarchical directory of existing web sites, and AltaVista, a huge, searchable database of pages, have proved themselves invaluable. Without some sort of organization, the usefulness of the World Wide Web would have been quickly overwhelmed by the sheer bulk of information available. The problem (as well as much of the power) with existing organizational techniques, however, is their simplicity. Queries must generally be entered in a logical form that is often confusing to many people, and the results returned are not generally just quite what you are looking for, especially for more complex searches.
This is where this system comes in. Wouldn't it be neat if you could go to some web site, type in a question (as broad or as specific as you choose), and get an answer back, both the answer and the question in common English? That's what GHuRU will attempt to do. I will outline the basic design for GHuRU, including a couple of alternative methodologies. I'll also go into some detail about the components involved in the system and outline some problems that would come up during implementation.
General Overview
In this design, I will assume the existence of a perfect Natural
Language Processer compatible with RCF, but I will make some attempt
to outline the requirements for a strict definition of RCF. I will
use AltaVista as an example search engine while describing the issues
involved with the generation of reliability weights. Finally, I will
discuss the HRU in some detail and try to describe how it might
function.
I can currently envision two different forms that GHuRU could take,
one having an integrated search engine that was constantly looking for
new information and higher concepts (by resolving independent lower
concepts with each other), and building its knowledge base. The other
would be more of a research tool that would try to answer questions
that you pose to it by searching available engines, but never trying
to go beyond that. With the
first model, GHuRU would try to answer new questions. Following the
old idea that every answer opens five new questions, GHuRU would in
time, learn everything that was available to be learned. With the
web as the source, this learning process could go on for quite some time.
Implementation Concerns
The biggest concern with any implementation is feasibility. Given the
current state of computer technology, is this a worthwhile project? I
think that the potential for a system like this makes its pursuit worthwhile
even if a full large-scale implementation might not be at this time.
I think that a largeish system (something akin to what AltaVista uses)
could handle queries at an acceptable pace. If the search engine
component were not integrated into the system, as would almost surely
be the case in an early prototype, the network lag would necessitate a
relatively large amount of time to answer a query. I would envision a
scenario where you would ask a question and then have the answer
emailed to you in an hour or so. Of course, this wouldn't suit the
needs of the average web surfer, but once a prototype is available,
all the pieces would be in place for further development.
Possible Offshoots
Any good idea makes you think of several more good ideas that are
slight variations. A intranet version of this system could certainly
be used to great effect, operating on a finite (is the web
finite?) supply of organized (hopefully) information. In a case
such as that, the real win over traditional database systems would be
the easy to use interface, as well as the concept search idea as
opposed to a simple keyword search.
If coupled with a translation system, GHuRU could also accept and
answer questions in any language, drawing its information from data
sources all over the world in multiple languages.
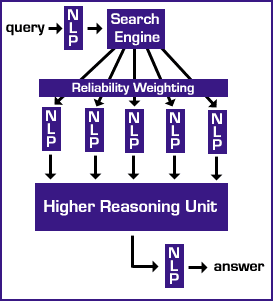 The basic system is pretty simple. It consists of a search engine
(multiple search engines can also be supported), a natural language
processing unit to convert between natural language (English in this
case) and a logical language form that I am calling Reduced Conceptual
Form (RCF), and a Higher Reasoning Unit (HRU)
that can accept RCF as
input and create Highly Reduced Conceptual Form (HRCF) as output which
is then converted back into our language of choice. There is also an
intermediate step bridging the Search Engine's output to the rest of
the system. This step is where information is weighted based on its
reliability and also actually retrieved from the World Wide Web.
The basic system is pretty simple. It consists of a search engine
(multiple search engines can also be supported), a natural language
processing unit to convert between natural language (English in this
case) and a logical language form that I am calling Reduced Conceptual
Form (RCF), and a Higher Reasoning Unit (HRU)
that can accept RCF as
input and create Highly Reduced Conceptual Form (HRCF) as output which
is then converted back into our language of choice. There is also an
intermediate step bridging the Search Engine's output to the rest of
the system. This step is where information is weighted based on its
reliability and also actually retrieved from the World Wide Web.
questions or comments should be sent to dbethune@hmc.edu