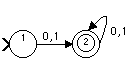
CS 131 - Programming Languages (Lecture 10a: Lexical Analysis & Finite Automata)
LOW LEVEL PARSING: LEXICAL ANALYSIS (PART II)
Last lecture I introduced Regular Expressions which are a system for specifying a language of tokens of a particular class. I did not say anything, though, about how you generate or recognize tokens belonging to the language described by a given regular expression.
Theoreticians long ago distinguished different classes of languages by how complex a computer is needed to determine whether a given string is in the language. Regular languages (the kind described by regular expressions) are the simplest class of languages and need the least machinery to recognize. They are recognized by a simple class of computers called finite automata.
As its name implies, a finite automaton can only ever be in one of a finite set of states. (They are a member of a class of machines called finite state machines.) When it is in a given state, based on the next input symbol it sees, it transitions to a different state. Which state it ends up in is dependent on which state it was in and what input symbol it saw. This information is given in the state transition function for the automaton.
The machine always begins a computation in some uniquely determined start state. It then performs a series of transitions determined by the input string it is analyzing and its state transition function. If, when it reaches the end of the input, it is in one of a set of predetermined final, or accepting states then the string is accepted as belonging to the language. If it is in some other state not among the final states, then the string is rejected. Finally, if at any point the state transition function does not specify a transition for the next input symbol, then the string is rejected.
A finite automaton is so simple you can draw a complete
depiction of it. States are represented by circles (with a ">" marking
the start state and double circles used for the final states) and labelled
arrows for the transitions. For example, here is the machine which
recognizes the language of strings of binary digits from the last
lecture:
('0' | '1')+
SOME EXAMPLE FINITE AUTOMATA
Here are finite automata for the other regular languages we described at the end of last class (I will adopt the common convention of leaving out the concatenation operator and representing concatenation by juxtaposition):
Real numbers requiring at least one digit on each side of the decimal point, with optional sign and optional optionally-signed exponent (I use d for regular expression for the set of digits):
('+' | '-' | ![]() )
(d+) '.' (d+) (
)
(d+) '.' (d+) (![]() | ('E' ('+' | '-' |
| ('E' ('+' | '-' | ![]() )
(d+)))
)
(d+)))
SML identifiers, which must begin with a letter, and then may have any string of letters, digits, underscores, and primes (I will use l for the set of letters and d for the set of digits):
l (l | d | '_' | ''')*
Ada identifiers, which must begin with a letter and then may have any string of letters, digits and underscores, with the proviso that underscores may only occur one at a time and cannot be the last character:
l (l | d)* ('_' (l | d)+)*
The thing to understand about finite automata is that
they have a strictly finite and predetermined amount of memory. The history
of a computation is represented purely by what state the machine is now
in, and since there are finitely many states, there are finitely many kinds
of histories a machine can remember. So for example, an FA can be used to
recognize ML comments. All it has to remember is whether it has seen the
end of the comment yet. I.e.:
It is common to say that FA's cannot recognize nested structures, but this is not quite right. For example, the last FA can easily be extended to allow a comment nested withing a comment:
However, we can only extend this to an arbitrary pre-determined nesting depth. FA's cannot recognize arbitrarily deeply nested structures. That is one reason why they are insufficient for programming languages (where you would not want to put a bound on how deeply you could nest if's, for instance). One way of putting it is that FA's cannot do recursive computations. Each recursion requires a new copy of the machine.
DETERMINISTIC VS. NON-DETERMINISTIC FINITE AUTOMATA
The FA's that I have shown you so far are what are known as Deterministic Finite Automata, or DFAs, because their behavior is entirely determined by their design. From each state their is only a single transition option for a given input, and the machine never makes a transition without consuming some input. There is another form of FA called a Non-deterministic Finite Automata, or NFAs.
In an NFA, it is possible to have several options
of where to go for a given input, and it is sometimes possible to transition
from one state to another without consuming any input. The latter transition
options are marked by edges labelled with ![]() ,
and are called
,
and are called ![]() -transitions.
Since one input string can lead to many different computations, an NFA is
said to accept a given string if there is some sequence of legal
transitions that the machine can go through for that string that will end
in a final state.
-transitions.
Since one input string can lead to many different computations, an NFA is
said to accept a given string if there is some sequence of legal
transitions that the machine can go through for that string that will end
in a final state.
One advantage of NFAs is that it is often easier to
see how to design an NFA for a given regular expression that a DFA, and
the NFA is also often smaller or simpler. In particular, any use of ![]() in a regular expression is easily modeled by and
in a regular expression is easily modeled by and ![]() -transition
in the NFA. So, for example, the real-number token language from above:
-transition
in the NFA. So, for example, the real-number token language from above:
('+' | '-' | ![]() )
(d+) '.' (d+) (
)
(d+) '.' (d+) (![]() | ('E' ('+' | '-' |
| ('E' ('+' | '-' | ![]() )
(d+)))
)
(d+)))
is accepted by the NFA:
In fact, there is a straightforward algorithm for tranlating from a regular expression to an NFA accepting the language described by that expression:
Algorithm to produce an NFA N accepting the language represented by a regular expression R:
If R = a, where a is either ![]() or an element of
or an element of ![]() ,
then N =
,
then N =
![]()
If R = (R1 | R2), and N1 and N2 accept the languages represented by R1 and R2 respectively, then N=
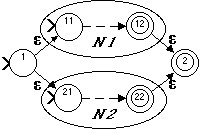
Note that here, and in the following cases, the start and final states of N1 and N2 are ordinary states in N.
If R = (R1 . R2), and N1 and N2 accept the languages represented by R1 and R2 respectively, then N=

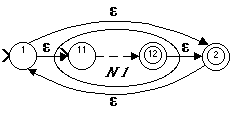
If R = (R1*), and N1 accepts the language represented by R1, then N =
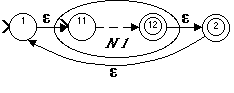
If R = (R1+), and N1 accepts the language represented by R1, then N =
So, for example, given the regular expression:
((a* c) | (b* d))
the algorithm constructs the NFA:
Notice that the last three cases of the algorithm
assume that the NFA's being built upon have only a single final state. This
is not a problem, since the algorithm produces only such NFAs. Even so,
it is always possible to convert an FA to an equivalent NFA with just a
single final state. Just add a new final state, ![]() -transitions
from the old final states to it, and convert the old final states to ordinary
states.
-transitions
from the old final states to it, and convert the old final states to ordinary
states.
While NFAs are easy to come up with mechanically, clearly, DFA's are easier to implement. It should be fairly easy to see how you could write a generic DFA simulator which could take a description of a DFA and a string and tell you whether the DFA accepts or rejects that string.
It turns out, though, that while NFA's may look like a slightly stronger formalism, they can recognize exactly the same set of languages that DFA's can. In addition, there is an a algorithm for converting a given NFA to an equivalent DFA, which runs as follows:
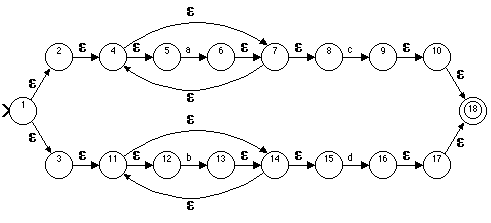
Given the NFA just constructed above the algorithm produces the DFA:
So, the standard way of building a lexer for a token language is to specify the regular expression for the language, convert that to an NFA, and then convert the NFA to a DFA. This process is so mechanical that there are programs, called lexical analyzer generators that will take a file of recular expressions describing the tokens of a language and execute these two algorithms in turn and produce code for a lexer for the language. The result is usually in the form of a generic DFA simulator instantiated to the description of the DFA for the language of interest. The most well known such generator is the one that came with AT&T unix, called lex, which generates C code. The GNU version of this is called flex. The SML-NJ distribution includes a lexical analyzer generator, called ml-lex, which functions very similarly to lex, but generates ML code.
![]() This page copyright ©1996 by Joshua
S. Hodas.
This page copyright ©1996 by Joshua
S. Hodas.