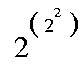
Assume that superpower(x,0) = 1 for any x.
Your name __________________________
Harvey Mudd College CS 60 Mid-Term Exam
Fall semester, 1999
Five Problems, 100 points
Closed book
Solutions
1. (Breadth-first and Depth-first search) [30 points total]
Suppose that an open list structure is used to represent a tree in such a way that the root is the first element of the list and the children of the root are the remaining elements of the list. For example, the following S expression (Polylist):(8 2 (1 9 -4 0) (6 11))or R expression (Rex list):
[8, 2, [1, 9, -4, 0], [6, 11]]represents the tree in the following diagram:
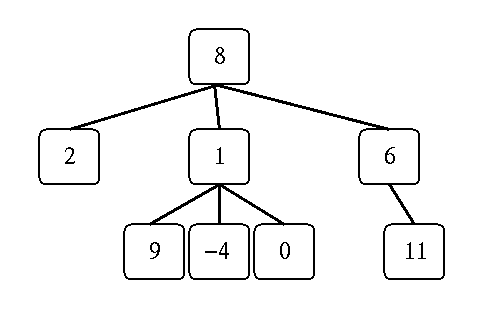
(A) (5 points) List the nodes of this tree in the order they would be encountered in (a) a breadth-first search and (b) a depth-first search.
Answer:(a) BFS: 8, 2, 1, 6, 9, -4, 0, 11
(b) DFS: 8, 2, 1, 9, -4, 0, 6, 11
(B) (20 points) Write a rex function bforder that takes a list representing a tree (such as the one above) as input and produces a list of the nodes of that tree in the order they would be encountered in a breadth-first search. The output of bforder is a "flat" list: all of its nodes are at depth 1.
Answer:bforder([]) => []; bforder([ [f|r]|R ]) => [f | bforder(append(R,r))]; bforder([ F|R ]) => [F | bforder(R)];An alternate answer using higher-order functions is the following. This version works by doing a breadth-first search on a "forest", i.e. a list of trees. The original tree is then viewed as a forest of one.
To breadth-first search a forest, we "slice off" the roots of the trees to form the first "layer" of the search. The remainder after slicing off the roots is itself a forest, and the relative depths of nodes in the original forest is preserved in the new one.
The roots are obtained as map(xfirst, Trees) where Trees designates the forest and xfirst is like first, except that it returns an atomic argument as itself (to account for the fact that the leaves of the tree are atoms in this model).
The remainder is obtained as map(xrest, Trees), where xrest is like rest, except that it returns [] if the argument is atomic. However, we want to discard any empty trees in the result, because there is no further searching there. So instead of map we use mappend to append the results of mapping together, which will also have the effect of absorbing any empty trees.
Having obtained the appended trees, we just breadth-first search the result, continuing this way until the base case, that the forest is empty.
For the example given, it works like this:
bforder([8, 2, [1, 9, -4, 0], [6, 11]]) => bforderTrees([[8, 2, [1, 9, -4, 0], [6, 11]]]) => append([8], bforderTrees([2, [1, 9, -4, 0], [6, 11]])) => append([8], append([2, 1, 6], bforderTrees([9, -4, 0, 11]))) => append([8], append([2, 1, 6], append([9, -4, 0, 11], bforderTrees([])))) => [8, 2, 1, 6, 9, -4, 0, 11]
The definitions are:
bforder(Tree) = bforderTrees([Tree]); bforderTrees([]) => []; bforderTrees(Trees) => append(map(xfirst, Trees), bforderTrees(mappend(xrest, Trees))); // xfirst and xrest permit the treatment of atoms as if lists of that atom xfirst(X) = atomic(X) ? X : first(X); xrest(X) = atomic(X) ? [] : rest(X);
(C) (5 points) Cite a difference between the functional approach to bforder and the natural approach to breadth-first-search in Java, as used, for example, in Assignments 5 and 6.
Answer:The functional approach uses a queue implicitly by appending remaining subtrees to the list under consideration; the imperative approach uses an explicit queue that is not part of the data structure being searched. (Other answers are also possible.)
2. (Data structures) [10 points]
Consider the hashtable and binary search tree data structures. What is the basic purpose of each? Describe an advantage of using each over the other. Keep your answer concise.Answer: Hashtables and BSTs are used to store and retrieve data. BSTs maintain the data in sorted order, so that operations such as finding the minimum or maximum are much faster than in a hashtable (log(n) time vs. nlog(n) time). General search for a specific element is faster in a hashtable, however (constant time vs. log(n) time). So BSTs require that there be a notion of order for the data, whereas hashtables do not.
This comparision is based on the typical cases where the buckets in the hashtable have a small number of elements in each and the BST is well-balanced. There is no guarantee, however, that these conditions hold, and in the worst case, both hashtable and BST can take an amount of time to search that is linear in the number of elements.
Another point of comparison is implementation. Implementation of insertion and deletion for hashtables is a relatively simple matter, requiring inserting or removal from a linked list. Insertion or deletion from trees is more complicated, since ordering must be preserved.
3. (Functional vs. Imperative Programming) [15 points]
Use McCarthy's transformation to create a recursive functional program (e.g., rex program) from the following piece of Java code. Your solution will consist of a number of mutually recursive functions. Describe in English what aspect (propoerty) of the input n is computed by this function.
int f(int n)
{
int i; int d; int c=0;
for ( i=n ; i >= 1 ; --i )
{
d = n/i;
if (d*i == n)
{
++c;
}
}
return c;
}
Answer:
f(n) = f2(n,0,0,n);This computes the number of (positive integral) factors of n.
f2(i,d,c,n) = i > =1 ? f3(i,n/i,c,n) : c;
f3(i,d,c,n) = d*i == n ? f2(i-1,d,c+1,n) : f2(i-1,d,c,n);
A compressed version of the function is:
f(n) = factors(n, n, 0);
factors(n, i, c) =
i >= 1 ?
((n/i)*i == n) ?
factors(n, i-1, c+1)
: factors(n, i-1, c)
: c;
4. (Recursion) [15 points total]
In the same way that multiplication can be considered repeated addition and raising to a power can be seen as repeated multiplication, we can define a function of two arguments, superpower(x,n), which is repeated "self-powering." The second argument, n, is an integer that indicates the number of times the first argument, x is to be "self-powered."
As an example,
superpower(2,3) is 16, or "2 to the power of (2 to the power of 2)" as shown in this diagram:
Assume that superpower(x,0) = 1 for any x.
(A) (5 points) Give a recursive definition of the superpower function. You may use java or rex syntax.
(B) (10 points) Write a function tailSuper which computes the same function as superpower, but is also tail recursive. You may use auxiliary functions as needed to write tailSuper.
Answer:
superpower(x,0) => 1; superpower(x,n) => pow(x,superpower(x,n-1));
tailSuper(x,n) => tailSuper(x,n,1); tailSuper(x,0,A) => A; tailSuper(x,n,A) => tailSuper(x,n-1,pow(x,A));
5. (Linked Lists and Inheritance) [30 points total]
A double-ended queue, or Deque (pronounced "deck"), is a list in which elements may be added or removed from both the head and the tail. Consider the implementation of a Deque in the form of a doubly-linked list, depicted in the following diagram, which shows a Deque consisting of three DCells. Note that the "prev" member of the DCell that is the head of the Deque is null, and the "next" member of the DCell that is the tail of the Deque is also null. Note that an arrow pointing to an X indicates a null reference.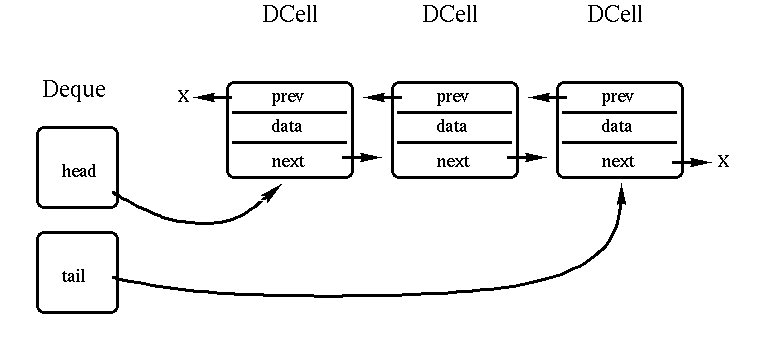
Suppose the implementation of the Deque is in terms of DCells, defined in the following class:
class DCell
{
Object data;
DCell prev;
DCell next;
}
Suppose, too, that the Deque class has the following data members:
class Deque
{
DCell head;
DCell tail;
void addToHead(Object data_in)
{
...
}
/* other class methods here */
}
(A) (20 points) Fill in the "..." in the Deque class. That is, write an addToHead method for the Deque class that takes a single argument of type Object that will be stored as data at the head of the Deque's list of DCells. Assume that the data within a DCell are accessible in the body of your addToHead method. Write the constructor of class DCell that you use.
Make sure you handle the case where the Deque mght be empty.
Answer:
/* DCell constructor (one possibility) */
DCell(Object data, DCell prev, DCell head)
{
this.data = data;
this.prev = prev;
this.next = next;
}
/* addToHead */
void addToHead(Object data_in)
{
if (head == null) { // case in which the Deque is empty
head = tail = new DCell(data_in, null, null);
} else { // when the Deque is not empty
head = head.prev = new DCell(data_in, null, head);
}
}
(B) (10 points) The above implementations of DCell and Deque did not use inheritance. However, suppose that the programmer creating a Deque implementation had access to the QCell and Queue classes (consider them separately, instead of considering QCell as an inner class of Queue). Discuss how one might use inheritance to create DCell and Deque from QCell and Queue and whether inheritance would do a good job of modeling the relationships involved.
Your answer need not be long -- three or four sentences is sufficient. You may include code, but do not have to.
Answer:It would certainly be possible to derive DCell from QCell: an additional reference, "prev" is needed, as well as a new constructor. Also, Deque could be derived from Queue. In this case, however, the addToTail (or equivalent name) already in the Queue class would have to be changed to handle the extra "prev" reference correctly. This could be done by calling Queue's (i.e., super's) addToTail method and then handling the "prev" reference in the balance of Deque's overriding addToTail implementation. It is interesting that the Deque could use the Queue's "next" reference, even though "next" is a QCell, not a DCell. With DCell a derived class of QCell, Deque can assign its inherited "next" reference to a DCell.