![]()
![]()
Reading: Russell and Norvig, chapter 4 and sections 5.1-5.4.
This lecture quickly reviews some diverse topics related to search: hill-climbing, solving constraint-satisfaction problems, and two-person games. The algorithms all tend to get a bit complex, so this only covers the high-level ideas. If you need to build one, plan on doing some further reading.
Iterative improvement techniques are used when we have found something close to a solution and want to repair its bugs. Or when we have found a solution and want to refine it into a better one. These methods are usually applied in continuous problems (see later in the course) but are occasionally useful in discrete search problems. Be aware that they work poorly without a good starting solution or almost-solution.
Two route planning problems might be candidates for iterative improvement. First, we may have found a route using a coarse-scale road map and wish to search for a similar but faster route using a fine-scale road map. Second, we may have found a path to guide a robot around obstacles, but the path-finding algorithm generates a jagged polygonal path. We might like to shorten the path and/or make it smoother.
The simplest improvement technique is hill climbing. This algorithm considers one or more parameters of our candidate solution. It then generates all "adjacent" values for these parameters (in a discrete problem) or a set of "nearby" values (in a continuous problem). Each of these new states is evaluated. The best state is picked. And we continue this process until we are no longer seeing any improvement in the state and/or run out of time.
For example, in the map-based route finding problem, we might pick a section of our route and use the fine-scale map to generate a new set of paths for this section. We then examine the distance for each new path. If one of them is shorter than our original path, the new section is spliced into the old path.
Gradient descent is a faster version of hill-climbing. It can only be used when the goodness of a state is a continuous and differentiable function of the state's parameters. For example, the length of a polygonal path is a continuous and differentiable function of the positions of the path's vertices. A gradient descent algorithm computes the first partial derivative for each state parameter. From these, it computes the direction in which goodness changes fastest: the gradient direction. It then alters the solution by moving the parameters some amount in that direction.
For example, to refine a robot path, we might compute the derivatives of path length as the positions of the vertices are varied. We can then determine how to move the vertices in a way that shortens the path. When it has computed the new path, the algorithm must check that the new path still avoids all the obstacles. If the new path is ok, it can try to further refine the new path. If the new path hits an obstacle, it can try moving the path less. (Sometimes obstacles are handled by by making the goodness get infinitely bad as the path approaches an obstacle.)
Hill climbing algorithms have two basic problems. First, they refine the solution only to the nearest local optimum. There may be a better solution which is on another peak of the goodness function. But hill-climbing cannot go temporily downhill in order to reach this other peak. Second, hill-climbing algorithms tend to get confused on plateaus, where all evaluations are similar, and on ridges, where the evaluations are similar along the top of the ridge.
Simulated annealing is a modification of hill-climbing that avoids getting stuck in local optima by occasionally moving "downhill," i.e. to states with worse evaluations. It refines the current state as follows:
This method is adapted from techniques used to model the annealing of metals.
In theory, simulated annealing will always find the globally best solution if it is tuned as follows:
This theoretical result, however, does not guarantee that the best solution will be found in an acceptable amount of time. In practice, simulated annealing can bounce the solution across small local dips in the state goodness. But it will take a long time to get from one peak of goodness to another peak that uses very different parameter settings, if they are separated by a large area of low rating. Therefore, like hill climbing, this technique performs well only when you start with a reasonably good initial state.
Deciding when to stop refining the solution is a bit of a black art.
In the first lecture on search, we saw the example of solving cryptarithmetic problems. In these problems, a piece of arithmetic is presented using letters in place of digits. The algorithm must find an assignment of digits to letters, which makes the arithmetic work. This is an example of a "constraint satisfaction problem," i.e. a problem in which a number of variables must be assigned values such that certain constraints are satisfied. Other examples include
The general approach to solving a constraint satisfaction problem is:
When a variable is given a value, constraints are used to
Constraints or other information about the problem are also used to do variable assignments in a "smart" order. The combination of these techniques can speed up search substantially.
For cryptarithmetic, let's consider the case of problems in which two numbers are added together to produce a third. The specific constraints on the letter-digit assignments are as follows:
In cryptarithmetic, each letter starts with a list of the values 0 through 9, except that leading digits are only given the values 1 through 9. When we assign a digit to a letter, we must
Two principles are used to decide which variable to assign a value to. First, we might choose the variable with the fewest possible values. In particular, when a variable has only one value remaining, it's usually best to do that assignment right away. Second, we might choose the variable which most constrains the values of other variables. In cryptarithmetic, this might be a letter found in the rightmost column or a variable in a column in which one other letter has already been given a value.
Having chosen a variable, we can then decide which value to try giving it first. The general principle is to choose the value that leaves the most possible values for other variables, because this maximizes the chances that this approach will yield a solution. However, this idea seems hard to apply in practice, at least to cryptarithmetic.
Another approach to solving constraint satisfaction problems is to use iterative improvement. That is, assign values to all variables. Then tweak the assignments to remove conflicts, e.g. by reassigning each problem variable to a value which causes the fewest conflicts. This is rumored to be very effective on the 8-queens problem.
When playing a game, a computer algorithm typically uses search to select its next move. Game search algorithms tend to be specialized and, for non-trivial games, complex. However, it's worth understanding the basic ideas used in a simple two-person game and the relatively general technique of alpha-beta pruning. Some of these ideas are occasionally used to make decisions for other sorts of applications, e.g. image understanding.
When analyzing game search algorithms, it is easier to keep everything straight if you consistently view the situation from the point of view of the player who is about to move.
A game search algorithm is given a set of states (e.g. board positions), an initial state and final states, a description of the possible moves, and a payoff for each final state. In a game like Tick-Tack-Toe, only three values are used for the payoff: 1 (I win), 0 (draw), and -1 (you win). In a more complex game such as bridge, the payoff will be the score: positive if I win and negative if you win.
Examples for simple game search tend to be artificial. If the game is simple enough that search can proceed all the way to the final states, then it almost always has only a three-valued payoff. Therefore, think of this model as a mathematical abstraction, which may not correspond to any actual game but can be elaborated into explanations for many types of games.
A tree representation of a typical game looks like this.
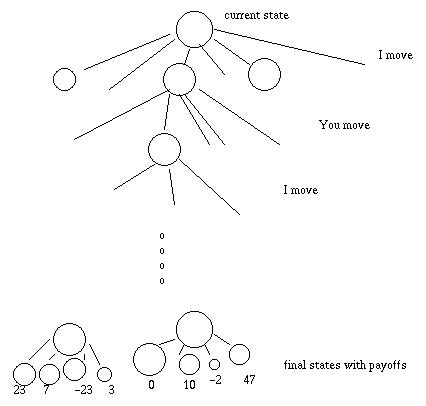
The minimax algorithm examines all states in the game tree e.g. using depth-first search. Assume for the moment that the tree is small enough that we can explore each branch all the way down to a final state. The final states have ratings: their payoffs. The algorithm then computes ratings for all the other states in the tree:
Eventually, ratings are computed for the states that are children of the top-most state (i.e. the current state). The algorithm then picks the move corresponding to the best-ranked child.
In real game-playing applications there is always a limit on how long the computer can think before making the next move in a game. In this amount of time, it is typically impossible to generate the tree all the way down to final states, because each state has so many children. Therefore, the search only generates the first k levels of the tree.
To rate non-final states at the bottom level of the search tree, game playing programs use various heuristics that are specific to the particular game. For example, a simple heuristic for chess involves assigning a weight to each piece (e.g. a pawn is 1 and a queen is 9), adding the weights for all pieces each player has left, and subtracting the counts for the two players. Realistic heuristics also incorporate facts about the positions of the pieces, specific configurations of pieces known to result in a win or loss, etc. Designing such heuristics is a black art.
In many cases, it is not necessary to search every branch in a game tree. When we are part-way through a search, it is often possible to determine that various other branches cannot lead to a better solution. By not exploring these branches, we speed up the search. This allows game playing algorithms to search more levels down the tree. This technique is called alpha-beta pruning.
We can prune (avoid searching) branches in the following situation, as well as in a similar situation where the roles of the two players are reversed.
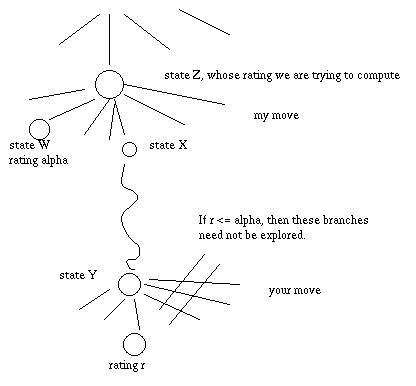
Specifically, suppose that we are trying to compute the rating of state Z. We have explored all the branches to the left of X and the best rating so far is alpha, found in some child of state W. In the course of exploring children of X, we find ourselves trying to compute the rating of state Y. One of the children of Y is discovered to have rating r, which is less than or equal to alpha.
Notice that in state Y, it is your turn to move. You always pick the move with lowest rating. So the rating of state Y can be no larger than r, which is no larger than alpha.
At state Z, it is my turn to move. I always pick the move with highest rating. So there are two cases:
In either case, I would not let the game end up in state Y, because its rating is worse than what I could achieve by picking move W. Since we have already established that state Y will not be selected in the actual game, we don't need to continue exploring its children.
To use alpha-beta pruning, we search the game tree using DFS. Each recursive call is given two values: the best value for one of my moves in any ancestor up the tree (alpha) and the worse value for one of your moves in any ancestor up the tree (beta). These values summarize the results for the parts of the tree to our left, which have already been explored.
Then, if it's my move, I give up and return immediately if the rating of the current node is >= beta. If it's your move, I give up and return immediately if the rating of the current node is <= alpha.
The performance of alpha-beta pruning depends on the order in which moves are considered. If we had perfect control, so that we always tried the best move first, then alpha-beta pruning would allow us to look twice as far down the game tree in the same amount of time. If we choose moves in random order, it allows us to increase the depth by a factor of 4/3. In practice, good heuristics which try to select the best moves first can achieve almost twice the depth. This is a Big Win.
This page is maintained by Margaret Fleck.