Name _________________________
CS 60
Parsing Worksheet
This worksheet, in essence, takes the place of class on
Monday, March 6. It is worth 25 points and may be worked on individually
or with orthers. Everyone should hand in her/his own copy, however.
This sheet asks you to work through material in Chapter 8 of the text --
especially part 8.3 .
It's due Monday evening (under the door of Olin 1245) by 9:00pm.
A one-word summary of this sheet is parsing. The basic idea in
parsing is to translate from raw input to a data structure
that represents the meaning of that input. We're parsing
things all the time (text, speech, images, etc.) but only in
unusually ambiguous situations does it even become conscious.
For example, for some people the sentence
The cotton clothing is made of grows in Mississippi.
causes them to "reparse," i.e., reconstruct the relative meanings
of the words, part way through reading it. We'll be looking at
how a compiler parses through code, but many of the principles
are the same as with general text.
There are two steps that comprise parsing (though sometimes they're
considered distinct):
Finding tokens:
Individual bits of input with meaning are called tokens. Finding those
bits is sometimes called tokenizing. For instance,
the sentence
The young horse around.
has four tokens: "The", "young", "horse", and "around" . Tokenizing text
is usually not a problem, because intervening spaces do it for us.
However, tokenizing code can be trickier. Consider
result+=left---right;
which is, in fact, legal Java. This gets tokenized into (you might want
to guess...) the following 7 tokens:
result
+=
left
--
-
right
;
Note that a single token can consist of more than one character. If you
haven't seen it before,
the "+=" operator adds the right-hand side's value to the
left-hand side's value and puts the result in the left-hand side's variable.
(Problem 1) Given these tokens for the above code, what are the values of
result, left, and right after running that
line of code? Assume the initial values of the three variables are
result = 100;
left = 50;
right = 7;
________________________________________________________.
(Problem 2) What are the tokens present in the following line of code?
(There are 9, including the semicolon.)
result*=x*/**/++y;
________________________________________________________.
Parsing:
Once the tokens of an expression are known, the next step
is to arrange them in a structure that groups together those that
are directly related. With code, this leads to constructing
a tree data structure known as the parse tree or
derivation tree.
For example, the above line of code
result+=left---right;
leads to the following parse tree:
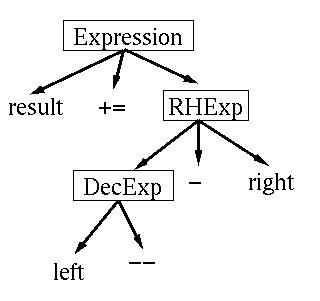
Here, the root of the tree indicates that
the whole line of code is an expression. The first
layer of children indicates that the whole expression consists
of an assignment (with "+=") of the right-hand expression
to the variable "result" . The second layer of children
indicates that the right-hand expression consists of
a Decrement Expression minus the variable "right" .
Finally, the Decrement Expression consists of the
variable "left" and the decrement operator, "--" .
One way to consider generating such a tree structure is
through a set of rules that tells you how each kind of
expression can be rewritten. This set of rules is called a
grammar.
A grammar that generates additive expressions with
single-letter variables is the following:
E -> V
E -> E + V
V -> a | b | c | ... | z
These rules are similar to rex's rewrite rules (sometimes they're
called "productions," because they produce legal expressions). The
capital letters are called "nonterminals" -- they can be rewritten
as indicated by the arrow "->" . So, E can be rewritten
in one of two ways: as a V or as E + V.
The lowercase letters and the plus sign are called "terminals,"
because they never get rewritten. The vertical bar "|" indicates
"or" . Put another way, V can be rewritten to any one of 26 different things:
the lowercase letters of the alphabet.
A grammar tells us (indirectly) how to build a parse tree
for a particular expression. Here's an example parse tree generated by the above grammar
for the expression
x + y
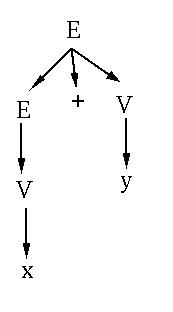
The idea is this: you start with the root of the tree being
the upper left-hand symbol of the grammar (called the "start
symbol"). You then choose rules (productions) that expand
each nonterminal symbol until you end up with the expression
you're interested in, which in this case is x + y.
There may be more than one rule to choose at any point --
in that case, you need to let the expression you're trying
to achieve guide the choice. Notice that the leaves of the tree are the individual
tokens in the expression we were trying to generate.
Another name for parse trees is "derivation trees" .
Problem 3
Using this idea of generation expressions according to a set
of "grammar" rules, create the parse tree for the following
expression:
a + b + c;
Again, start with the start symbol, E and use the rewrite
rule to obtain a tree whose leaves are the tokens in the above expression.
________________________________________________________.
A couple of notes about grammars:
(Problem 4)
Create the parse tree for the expression
(())()
according to the last grammar mentioned above (the one that generates
expressions with well-balanced parentheses). Again, start with
the start symbol S and apply rewrite rules until
the leaves of the tree are the above expression.
________________________________________________________.
(Problem 5)
Consider the following grammar for additive and multiplicative
expressions:
E -> T { + T }
T -> V { * V }
V -> a | b | c | ... | z
Write the parse tree corresponding to the expression
a + b * c
that the above grammar generates.
________________________________________________________.
Writing Grammars:
The following problems ask you to write a grammar that will generate
a specified set of legal expressions. (In general there is more than
way to do so.) Use capital letters as nonterminal symbols and
lowercase letters as terminal symbols.
As an example, suppose that the set of legal expressions
consist of any number of a's, followed by any number of b's.
Then these expressions are legal:
aaaabbbbbbbb
abbbbb
a
bb
(any number can mean zero in this case). These expressions are
not legal:
aaaaaba
aaaacbbbbbb
aabb
There are lots of ways to write a grammar that generates all and
only the legal expressions by this definition. Here is one --
S -> A B
A -> A a
A -> 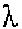 B -> B b
B ->
B -> B b
B ->
(Notice that we're ignoring spaces in the grammar -- this is
typical and makes the rules easier to read.)
A second, equivalent, grammar is
S -> { a } { b }
(Problem 6) Write a grammar that generates all and only those expressions
consisting of any number of a's with (possibly) a single b included anywhere. Thus,
these are legal expressions:
aaaaaa
baaaa
aaabaaaa
b
aaaaaab
(Notice the empty expression is legal in this case.)
These expressions are not legal:
aabaaaaab
bb
aaacaaaa
________________________________________________________.
(Problem 7) Write a grammar that generates all and only those expressions
consisting of any number of a's followed by the same number of b's.
These are legal expressions:
aaabbb
ab
aaaaaaabbbbbbb
(Notice the empty expression is legal in this case.)
These expressions are not legal:
bbbbaaaa
aab
b
________________________________________________________.
(Problem 8) Write a grammar that generates all and only those expressions
consisting of single-letter variable names with three possible operators:
addition (+), multiplication (*), and exponentiation (^). Thus,
a ^ b
is a legal expression meaning "a to the b power" . (Note that this isn't
legal in Java.) Use the additive/multiplicative grammar above as a guide.
All of these are legal expressions:
a + b * c ^ d
x ^ y ^ z
f + g + h ^ j
(Notice the empty expression is not legal in this case.)
These expressions are not legal:
^ h * g
a b c + d
________________________________________________________.
(9) Rewrite the above grammar to allow arbitrary parenthesization
of subexpressions. Hint: use recursion!
These are some examples of legal expressions:
a + (b + c + f * r)
a + (b + (c + f) * r)
d * e
(t + l) ^ (w ^ x)
These expressions are not legal:
( )
(s + h
) f + e (
________________________________________________________.
On Wed. (and for this week's assignment), we will be
running such grammars in reverse, i.e., going from expressions to the parse trees
that determine their meaning.
(Extra credit) (+5) Write a grammar that generates all and only
expressions consisting of some number of a's followed by the same number of
b's followed by the same number of c's. (This is possible, but tricky.
Hint: you can be flexible with the left-hand side of your rewrite rules.)