rex > fahrToCel([212,32,-40]);
[100,0,-40]
The conversion of individual temperatures is C = (F-32)*(5/9.0).
This problem is not, in spirit, different than
add42List. In this
case, however, you should
use an anonymous function as a first argument
to map. Don't write the conversion function separately and then
use its name.
You can test this function with Tests #1 and #2:
rex hw2.rex < /cs/cs60/as/a2/Test1.in
rex hw2.rex < /cs/cs60/as/a2/Test2.in
You can test this function with Tests #3 and #4. (See Problem 1 for the full test command.)
Appropriate runs include
rex > erdos(42);
21
rex > erdos(109);
328
// Here I'm using the erdos function from the example above. // since the first argument is 1, the desired result is erdos(3), // and erdos(3) equals 10. rex > iterate(1, erdos, 3); 10 // Now I'm iterating twice and computing erdos(erdos(3)): rex > iterate(2, erdos, 3); 5 // And this is finding erdos(erdos(erdos(3))) rex > iterate(3, erdos, 3); 16 // Iterating the add1 function twice is equivalent to adding 2. // Don't forget to define add1 before trying this ! rex > iterate(2, add1, 9); 11
As a bit more explanation, consider collapse([3]). Looking at the previous examples from the iterate specification, we see that
erdos(erdos(erdos(3))) = 16.Continuing in this way,
erdos(erdos(erdos(erdos(erdos(erdos(erdos(3))))))) = 1with erdos iterated 7 times. Thus, collapse([3]) == [7]. Further examples of collapse in action include
rex > collapse([3, 10, 5, 16]); [7, 6, 5, 4] rex > collapse([129, 55, 85]); [121, 112, 9]Will every positive integer collapse to 1? No one knows, though many mathematicians have worked on it. The mathematician Paul Erdos actually felt that "mathematics is not yet ready for such problems," as the "3x+1" problem, as this is called. Check out the site http://www.paulerdos.com/0.html for more on Paul Erdos.
Write a function createScorer(db) that takes one such database as input and returns a function as output. The output function should be a word-scoring function, that is, should take a string as input and output a score for that string based on the database provided to createScorer. The score is the sum of the scores of the letters. For example,
// Include the file with the scoring tables
rex > sys(in,"/cs/cs60/as/a2/letterScoring.rex");
// Let scrabbleScorer be bound to the function created by
// createScorer in this case.
rex > scrabbleScorer = createScorer(scrabbleScores);
1
rex > scrabbleScorer("rex");
10
// In this case the function output by createScorer is used immediately.
rex > createScorer(letterOrder)("ronaldwilsonreagan");
202
// To demonstrate, I'll first define two functions called foo and goo.
rex > foo(X) => 2*X + 1;
foo
rex > goo(X) => 3*X - 2;
goo
// Now, envelope(foo, goo) returns a function and here we let moo
// represent that function.
rex > moo = envelope(foo, goo);
1
// Now, let's evaluate the function moo with input of 5.
rex > moo(5);
13
Create the function biggestFan(G) that takes a graph G (as a binary relation) as input and outputs the node of G that has the biggest fan-in. The fan-in of a node is simply the number of parents of that node, so biggestFan returns the node with the most parents. You may assume that biggestFan will only receive input graphs that do have at least one edge.
If there is a tie for the biggest fan-in, you may return any one of the correct nodes. For example:
rex > biggestFan([ ["A","D"], ["B","D"], ["C","D"], ["A","E"],
["D","E"], ["E","F"], ["F","A"] ]);
D
rex > biggestFan([ ["A","B"], ["B","C"] ]);
B
where the last answer could also have been C. NOTE Your predicate will only be given ACYCLIC graphs as input. Thus, you don't have to worry about "running around in circles" searching for whether there is a path from a to b, because there will be no cycles in the graph. Also, remember the graphs are directed. For example,
rex > reachable("A", "F", [ ["A","D"], ["B","D"], ["C","D"], ["A","E"],
["D","E"], ["E","F"] ]);
1
rex > reachable("C", "A", [ ["A","B"], ["B","C"] ]);
0
rex > reachable("D", "D", [ ["A","B"], ["B","C"] ]);
1
As the last example illustrates, your function should acknowledge
that any node can be reached from itself. What's more the node
does not even need to be in the graph! (This is because the
graph does not have to be connected -- an unlisted node
is one with neither outgoing nor incoming edges.)
[ rootValue, leftSubtree, rightSubtree ]. The
rootValue will always be an integer, and the left and right
subtrees are binary search trees. Write the function delete(X,
T) that takes a value X and a list T representing a
binary search tree and returns a binary search tree with all of the elements
of T except with X removed. You can assume that
X is definitely in the tree T. For example, the list
[10, [3, [], []], [42, [20, [], []], [60, [], []] ] ]represents the tree
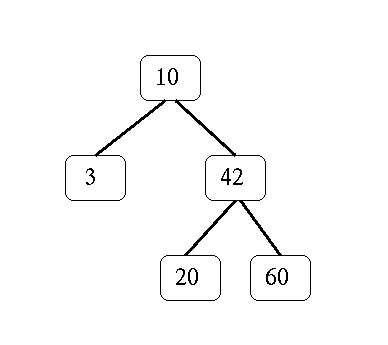
We will go over the algorithm for removing an item from a binary search tree in detail in class. As a brief reminder, first find the element you are looking to remove (traversing left (less) or right (greater)) as necessary. When the element to be removed is at the root of a tree - check if it has an empty subtree. If so, replace it with the other subtree. If, on the other hand, there is no empty subtree, replace the root with the minimum of the right subtree and then remove that minimum from the right subtree.
For example, here are some input and output:
rex > mytree = [10, [3, [], []], [42, [20, [], []], [60, [], []] ] ]; 1 rex > delete(10, mytree); [20, [3, [], []], [42, [], [60, [], []]]]
Hint: you will need to write a function that finds the minimum element in a binary search tree. (Code for findMin will be written in class.)
The Unicalc Application
The last three problems are related to the "Unicalc" unit-conversion application.
The Unicalc application converts quantities expressed in one type of unit to those of another. The end result (not this week's assignment) will be able to do conversions like the following:
rex > convert( [1, ["mile"], ["hour"]], [1, ["meter"], ["second"]], db);
multiply by 0.447032 or divide by 2.23698
Unicalc works on multiplicative conversions only, so it does not
perform conversions such as Fahrenheit to Celsius.
Functional programming provides a natural way to implement the
kernel of Unicalc. In this assignment, we walk through some of the data
representations and issues, and ask you to write the first half of the code
in rex. Here are the key representations used in Unicalc:
- A Quantity List is a list of three elements representing
some quantity of a designated unit. For example,
[1.0, ["mile"], ["hour"] ] represents 1 mile per hour [2.5, ["meter"], ["second", "second"] ] represents 1 meter per second^2 [60.0, [ ], ["second"] ] represents 60 hertz [3.14, [ ], [ ] ] represents about pi radiansTo summarize, a Quantity List is a list of three elements: the first is the quantity (floating point), the second is a list of units in the numerator, and the third is the list of units in the denominator. Note You can assume that the lists of units (within the numerator and within the denominator) are initially in alphabetical order. Your code will need to make sure this property is maintained!
- A Conversion Database is a list of relationships between
units. For example,
db = [ ["foot", [12.0, ["inch"], []]], ["mile", [5280.0, ["foot"], []]], ["coulomb", [1.0, ["ampere", "second"], []]], ];Each line in the database is a list of two elements -- the first element is a string that names some unit and the second element is a Quantity List that is equivalent to that named unit.Not every unit is defined in terms of others in the database. Some are intentionally left undefined. We'll call the latter basic units. In the above example, inch, ampere, and second are basic units. A database does not need to contain conversions for everything to everything; that would tend to make it very large and maintenance would be error-prone. Instead, all conversions done by Unicalc are derived from basic ones in the database.
Some example uses of simplify include
rex > simplify([3, ["kg", "meter", "second", "second"],
["kg", "kg", "second"]]);
[3, ["meter", "second"], ["kg"]]
rex > simplify([3.14, ["meter", "second"],
["meter", "second", "second"]]);
[3.14, [], ["second"]]
Some example runs include
rex > multiply([2.0, ["kg"], ["second"]],
[3.0, ["meter"], ["second"]]);
[6.0, ["kg", "meter"], ["second", "second"]]
rex > divide([12.5, ["meter"], ["second"]],
[0.5, ["meter"], []]);
[25.0, [], ["second"]]
(Hint: don't rewrite simplify!)
db =
[
["foot", [12., ["inch"], []]],
["mile", [5280., ["foot"], []]],
["inch", [0.0253995, ["meter"], []]],
["hour", [60., ["minute"], []]],
["minute", [60., ["second"], []]],
["mph", [1., ["mile"], ["hour"]]],
["coulomb", [1, ["ampere", "second"], []]],
["joule", [1, ["kg", "meter", "meter"],
["second", "second"]]],
["ohm", [1, ["volt"], ["ampere"]]],
["volt", [1, ["joule"], ["coulomb"]]],
["watt", [1, ["joule"], ["second"]]]
];
which happens to be the current contents of
/cs/cs60/as/a2/unicalc_mini_db.rex.
There is a substantial database of elements that you are
also welcome to try out in the file /cs/cs60/as/a2/unicalc_db.rex .
If this were the entire database under consideration, note that "ampere", "meter", and "second" are all basic quantities, since they are not the LHS of any definition.
Write a rex function conv_unit(u, DB) that takes a string representing a unit and the database association list as arguments. If the unit is defined in the database, it returns that unit's equivalent quantity list, otherwise it returns a standard quantity list representing the unit: [1.0, [u], []]. For example, if db is the database consisting of the list of the pairs above, then:
rex > conv_unit("hour", db);
[60, [minute], [] ]
rex > conv_unit("meter", db);
[1, [meter], [] ]
Hint: when you use assoc to look up an element that's not in a database, it returns "false" (actually, it returns [], which is interpreted as false).
Assignment 3 will use these functions in order to complete the unit-conversion application.
This function would allow a more efficient solution to the bestThree problem on the previous assignment, as there are at most 140 different three-letter substrings formable from seven characters. (You do not have to redo that problem!)
For instance,
rex > subsets(2,"abcd");
[ [a, b], [a, c], [a, d], [b, c], [b, d], [c, d] ]
rex > subsets(2,"aacd")
[ [a, a], [a, c], [a, d], [c, d] ]
rex > subsets(2,"aaad")
[ [a, a], [a, d] ]
rex > subsets(5,"aacd")
[ ]
For instance,
rex > readInteger(111221);
312211
rex > readInteger(8777511);
18371521