Computer Science 60
Principles of Computer Science
Spring 2003
Assignment
02
Kwic
Index
Due Date: Due by
midnight of the morning of your next
lab, Monday 10 February.
No assignments are accepted afterward.
Please submit the problems
marked “in lab” while in the laboratory.
Submissions:
- Submit during lab:.The function
numberand the functionparse. - Submit all functions together in a single file by
the deadline, with proper header and commenting. You may leave test cases
using the built-in 2-argument test function in the file, if you wish. (Do
not re-define function
test; this will confuse the system.) - Use cs60submit as always.
Preparation:
It would be a good idea read Chapter 4 in the course text in conjunction with this assignment, since a fair amount of low-level functional programming is needed.
The
Assignment Proper:
A “kwic” index (KeyWord-In-Context
index) is an index that alphabetizes words in a list of titles, so that titles
can be looked up based on the occurrence of words in them. Thus a given title
may appear multiple times in the index, once for each significant word in the
title. Accompanying each entry in the index is a citation number that enables
the user to find more information about the title.
Suppose, for example, that our list of titles is the following list of aphorisms:
aphorisms = [ "It is easier to fight for one's principles than to live up to them.", "The only normal people are the ones you don't know very well.", "Love thy neighbor as thyself, but choose your neighborhood.", "The covers of this book are too far apart.", "No good deed goes unpunished.", "I either want less corruption, or more chance to participate in it.", "My opinions may have changed, but not the fact that I am right."];
Then a kwic index for this list of titles, might appear as:
anged, but not the fact that I am right. : 6overs of this book are too far apart. : 3 The only normal people are the ones you don't know ve: 1 The covers of this book are too far apart. : 3 Love thy neighbor as thyself, but choose your ne: 2 The covers of this book are too far apart. : 3 Love thy neighbor as thyself, but choose your neighborhood. : 2 My opinions may have changed, but not the fact that I am rig: 6 want less corruption, or more chance to participate in it. : 5 My opinions may have changed, but not the fact that: 6e thy neighbor as thyself, but choose your neighborhood. : 2 I either want less corruption, or more chance to : 5 The covers of this book are too fa: 3 No good deed goes unpunished. : 4normal people are the ones you don't know very well. : 1 It is easier to fight for one's prin: 0 I either want less corruption, o: 5 may have changed, but not the fact that I am right. : 6he covers of this book are too far apart. : 3 It is easier to fight for one's principles tha: 0 It is easier to fight for one's principles than to l: 0 No good deed goes unpunished. : 4 No good deed goes unpunished. : 4 My opinions may have changed, but not the fact: 6changed, but not the fact that I am right. : 6 I either want less corruption,: 5 It is easier to fight for one's p: 0 It is easier to fight for one': 0 more chance to participate in it. : 5 people are the ones you don't know very well. : 1 I either want less corruption, or more chanc: 5t for one's principles than to live up to them. : 0 Love thy neighbor as thyself, : 2 . . . abridged for brevity . . Love thy neighbor as thyself, but choose your neigh: 2 It is easier to fight for one's principles : 0ight for one's principles than to live up to them. : 0ess corruption, or more chance to participate in it. : 5e's principles than to live up to them. : 0 The covers of this book are too far apart. : 3 No good deed goes unpunished. : 4 one's principles than to live up to them. : 0le are the ones you don't know very well. : 1 I either want less corruption, or more : 5e the ones you don't know very well. : 1nly normal people are the ones you don't know very well. : 1eighbor as thyself, but choose your neighborhood. : 2 | | |“gutter” reference
Notice the “gutter” down the middle of the index. The words to the right of the gutter are those on which alphabetization has occurred. Surrounding the word on either side is the context, the rest of the title. On the rightmost end, after ‘:' is the reference number, which in this case is just the position of the title in the original list, counting from 0.
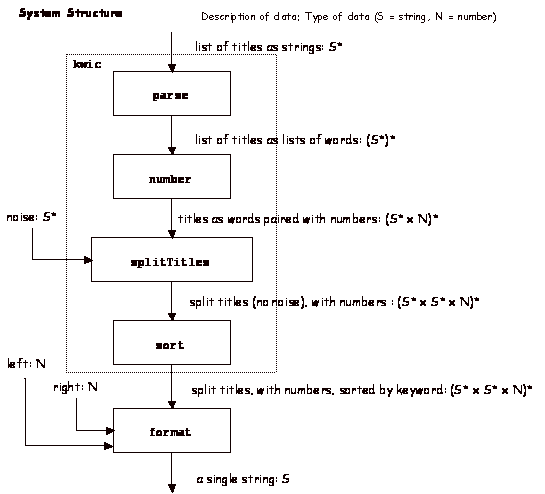
Exploit functional programming concepts by constructing a function that produces a kwic index for any list of titles. Decompose the overall function into a number of parts and implement the parts individually. A design is given in the following.
A required argument to the index-producing function is a list of noise words, words on which we do not want to index. In the current example, the list of noise words was specified as
["a", "A", "from", "From", "in", "In",
"of", "Of", "on", "On", "the", "The"]
Requirements:
Two functions are required:
kwic(Noise, Titles) returns a raw list of triples containing the words
to the left and right of the keyword, and the reference number information as
lists of words, but not otherwise formatted.
format(Left, Right, Triples) formats
this information into a single string which is the printable index.
The reason for the first function is that we might make further use of the index contents in list form rather than string form, for example in developing a larger implementation. This gives us an “API” (Application Programming Interface) for the problem, while the formatting function just gives one possible output form of the information.
kwic(Noise,
Titles) produces a
list of triples in the following form:
[ [ ["My", "opinions", "may", "have", "changed,", "but", "not",
"the", "fact", "that", "I"], ["am", "right."], 6 ], [ ["The", "covers", "of", "this", "book", "are", "too", "far"], ["apart."], 3 ], [ ["The", "only", "normal", "people"], ["are", "the", "ones", "you", "don't", "know", "very", "well."], 1], [ ["The", "covers", "of", "this", "book"], ["are", "too", "far", "apart."], 3 ], [ ["Love", "thy", "neighbor"], ["as", "thyself,", "but", "choose", "your", "neighborhood."], 2], . . .
]
Specifically, each triple contains a list of strings to the left of the keyword, a list of strings to the right of and including the keyword, and the reference number.
format(Left,
Right, Triples) produces a single string in the form of the
index shown earlier, where Left
is the number of spaces to be used to accommodate the part to the left of the
keyword, and Right is the
number of spaces to be used to accommodate the part to the right of and
including the keyword, and Triples
is the list of triples as shown above.
This breakdown separates the concerns of producing the layout in a fixed space vs. those of determining the parts of the title to either side of the keyword.
Of course, these prescribed functions should be further decomposed. Here is the way that we suggest doing it. This particular decomposition is not required, but if you follow it, then you will be able to use some of our test cases:
parse(Titles)
breaks down each title into a list of its words. The blank separator is used to
indicate where one starts and another leaves off. Punctuation should be kept
with the word preceding it, so it is just treated as another character.
number(ParsedTitles)
produces a list of pairs, consisting of a title and the position of the title
in the original list.
splitTitles(Noise,
TitleNumberPairs) converts a list of pairs [Title, Reference] into a list of
triples [LeftTitle, RightTitle,
Reference] keeping only the ones having a RightTitle that does not begin with a
noise word. This function could be implemented using built-in mappend and a
function split1
that splits a single [Title, Reference]
pair into all possible splits that do not involve a noise word. The function split1 may be the most
complicated function in the overall decomposition. The output of splitTitles looks like:
[
[
[], ["It", "is", "easier", "to", "fight", "for", "one's","principles","than", "to", "live", "up", "to", "them."],
0],
[
["It"], ["is", "easier", "to", "fight", "for", "one's", "principles", "than", "to", "live", "up", "to", "them."], 0],
[
["It", "is"], ["easier", "to", "fight", "for", "one's", "principles", "than", "to","live", "up", "to", "them."],
0 ], . . .]
Given the result of splitTitles, all that is left to be done to
implement function kwic
is to sort the resulting triples by keyword. For this purpose, you will want to
use a generalized sorting function that takes a comparison operator as an
argument. At one time this function was built into rex, but it is currently
disabled. I will provide an implementation of this sorting function for you at
no charge.
To implement format,
you would need to count out characters in the words, stopping when you have
reached the specified number of spaces. If there are that many characters, then
padding with blanks will be required. Working with lists of characters after
exploding the words is one way to do this.
The following “data-flow diagram” shows the overall design: