Harvey Mudd College
Computer Science 60
Assignment 2, Due Sunday, February 1, by 11:59 pm
Link to the CS 60 submission site
Back to the top-level assignments page
Back to the top-level CS 60 page
Functional programming!
This homework more deeply emphasizes two facets of functional programming:
- That functions are first-class objects -- that is, they can be the inputs to other functions, return values from other functions, and, like data, they can be without names, i.e., anonymous.
- That complex problems can be solved by decomposing them into smaller, helper functions. Composing those smaller pieces yields a solution to the overall problem at hand. A great deal of creativity in CS arises in deciding exactly how to break problems up!
The Problems
Getting started
If you created a cs60 directory and then a hw1 directory within it
for the last assignment, you may want to create an analogous hw2 directory for
this one. You can create a new file named part1.rex by copying the old one or
by typing pico part1.rex
//
// part1.rex -- CS 60 homework 2, Spring 2009
//
// Name:
//
// Comments to graders:
//
//
//
// pr: #1 (first part)
// fun: erdos
// in: x, a positive integer
// out: another positive integer
Problem zero is an optional guide to opening windows remotely from knuth; the problems themselves start just below it... .
Built-in functions
You're welcome to use any of Rex's built-in functions for this week's assignment
(with one minor exception, below). Also, you may copy functions from homework #1
or from class
into this week's files to reuse them: for example, rmv1(e,L)
and removeAll(e,L)
are often useful. Here is a list of some of the more common ones:
list(e,f,...) // makes a list from its inputs. [e,f,...] is often easier
cons(f,R) // the same as [f|R]
append(L,M) // concatenates two lists (inputs must be lists!)
member(e,L) // 0 if e is not in L; 1 if e is in L
reverse(L) // reverses L
rmv1(e,L) // not built-in; from class -- removes one e from L
removeAll(e,L) // not built-in; from hw#1 -- removes all e's from L
length(L) // returns the length of L
max(x,y) // returns the max of x and y -- does NOT take the max over a list
min(x,y) // returns the min of x and y -- does NOT take the min over a list
sort(L) // returns a sorted version of L
first(L) // returns the first of L (similarly, second, third...)
map(f,L) // applies f to each element of L. f takes one input.
reduce(f,e,L) // "pushes" the binary operator f "through" L, starting at e
keep(p,L) // retains those elements x in L that make p(x) true
drop(p,L) // drops those elements x from L that make p(x) true
some(p,L) // returns 1 iff there exists an x in L such that p(x) is true
all(p,L) // returns 1 iff p(x) is true for all x in L
Optional Problem 0: Opening a window onto knuths' files
[0 points ~ optional]
You are welcome to obtain any and all help on this problem!
What about the mouse?
One of the things that helps nano and pico earn their names is the fact that they do not accept mouse input. It is possible, however, to open an editor that provides the mouse-based access to text files that is both familiar and convenient. This section describes how to do so using a window-based editor named gedit from knuth.
This is entirely optional -- you're welcome to use nano or pico as in assignment #1. On the other hand, if you feel like you'd be that much more efficient with a more modern editor, give it a try!
Details...
As with the login and file-transfer process, opening windows from a remote server depends on whether you're using Mac OS X or windows. Linux users should be able to follow the Mac OS X instructions:
A reminder about testing your code
Again, these problems will provide some tests to try -- please do be sure your functions pass them! But you may want to add additional tests of your own -- for example, to check base cases or other unusual facets of the desired behavior that the provided tests miss... .
part1.rex Individual problems, #1 through #5
As with the previous assignment, please submit definitions for these functions in a file named part1.rex. Each person should write these first five problems on their own. We encourage you to seek out help from us, from the grutors, or from other students as described in the syllabus.
Problem 1: erdos and countIter
[10 points, individual]
One-fifth of this problem is for creating a function erdos(x), which will take only positive
integers as input. Then, erdos(x) should output half of x in the case that x
is even. When x is odd, erdos(x) should output
one more than three-times-x.
For example,
test( erdos( 3 ), 10 );
test( erdos( 10 ), 5 );
test( erdos( 5 ), 16 );
test( erdos( 16 ), 8 );
test( erdos( 8 ), 4 );
test( erdos( 4 ), 2 );
test( erdos( 2 ), 1 ); // repeated application leads to 1...
The final piece of this problem is to write the function countIter( f, x, goal ), whose first argument f is a function of one input; the second argument x is the initial value for an input to f. The idea is to compute f(x), f(f(x)), f(f(f(x))), and so on until the resulting value is equal to goal. The number of calls-to-f needed to reach goal is what countIter returns.
Put another way, countIter returns the smallest number of times one needs to iterate f, starting at x, until the result is equal to goal. Note that if x and goal are equal, no function applications are necessary, and the output should be 0.
Here is an example. Note that the tests above show that erdos( erdos(10) ) == 16, where
erdos is iterated two times. Thus, countIter( erdos, 10, 16 ) should return 2.
Here are some additional tests to check:
test( countIter( erdos, 3, 1 ), 7 );
test( countIter( erdos, 16, 1 ), 4 );
test( countIter( erdos, 16, 16 ), 0 );
test( countIter( (x)=>x+1, 17, 19 ), 2 ); // using an anonymous function
Problem 2: divBy(n)
[10 points, individual]
Write a function divBy( n ), which takes as input an integer n and which should return a function. This output function itself should take one integer as input and should return 1 if its input is divisible by n. The output function should return 0 if its input integer is not divisible by n. For the sake of this problem, consider it the case that no integer is divisible by zero.
You'll want to use the modulo - or remainder - operator, represented by %. For instance, 19%8 == 3, because the operation of dividing 19 by 8 leaves a remainder of 3.
For testing, you can bind a name to the output of divBy and then use
it. Alternatively, you can use the output function immediately, even though the
syntax looks somewhat odd -- see the last two examples:
f = divBy(7); // let f be the name of the function output by the call divBy(7)
test( f(42), 1 );
test( f(41), 0 );
g = divBy(0);
test( g(42), 0 );
test( g(41), 0 );
test( divBy(3)(15), 1 ); // note the crazy syntax -- see below!
test( divBy(3)(14), 0 );
Hint: Since no integer is divisible by zero and x%0 is an error, your divBy function will need to handle the input of n == 0 as a separate case.
Problem 3: all_pairs(L)
[10 points, individual]
Write a function all_pairs(L,M) that takes two lists as an input and
returns a list whose elements are all the pairs of elements
whose first element is from L and the second element is
from M. You may assume
that there are no duplicate elements in L; nor are there duplicates
in M. Here is some sample input and output illustrating the
order in which the pairs should appear in the output:
test( all_pairs( [],[8,9] ), [] );
test( all_pairs( [1,2,3],[8,9] ), [ [1,8], [1,9], [2,8], [2,9], [3,8], [3,9] ] );
If either input list is empty, the output should be empty.
Problem 4: treemin
[10 points, individual]
Write treemin( T ), whose input is a nonempty binary search tree. Recall that a binary search tree can either be empty, [], or consists of exactly three elements: a data value called the root, a left subtree L, and a right subtree R, e.g., [root, L, R]. Each of the left and right subtrees are, themselves, binary search trees. In addition, all data in a left subtree are always less than the root; all data in a right subtree are always greater than the root. For example, the list
[10, [3, [], []], [42, [20, [], []], [60, [], []] ] ]represents the tree
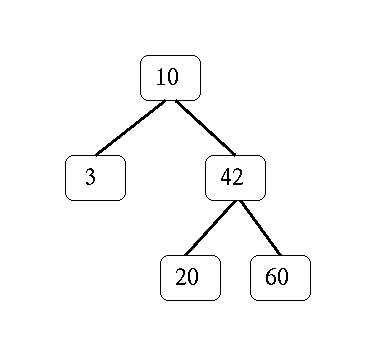
The treemin function should return the smallest data value present in the
binary search tree T.
Here are a few tests to try
test( treemin( [10, [3, [], []], [42, [20, [], []], [60, [], []] ] ] ), 3 );
test( treemin( [10, [], []] ), 10 );
Problem 5: bestWord
[up to 10 points, pair or individual]
This follows up from last week's wordScore function. You should feel free to copy your code for wordScore into this week's file. Any other functions that might be of use are OK to copy, as well. You might also copy the files scrabbleScores.rex and threeLets.rex into your current directory. Both scrabbleScores.rex and threeLets.rex are in the directory /cs/cs60/hwfiles/a2.
For this problem, you'll write bestWord( rack, Words ), where rack is a string representing one's available scrabble tiles and Words is a list of legal words. Then, bestWord should output a [word, score] pair, where word is the highest-scoring member of Words such that word can be formed from the letters in rack. If Words has no elements that can formed from rack, your function should return ["no word", -1]. You may break ties however you like, but should return only one [word, score] pair.
Here are some examples:
test( bestWord( "abcdefg", [ "bbb", "bag" ] ), [ "bag", 6 ] );
test( bestWord( "abcdbbg", [ "bbb", "bag" ] ), [ "bbb", 9 ] );
test( bestWord( "a", [ "bbb", "bag" ] ), [ "no word", -1 ] );
test( second(bestWord( "abcdefg", ospd3 )), 7 );
test( bestWord( "zabcdefg", ospd3 ), [ "fez", 15 ] );
The file threeLets.rex contains
a list of words named ospd3:
these are all of the three-letter words from the Official Scrabble
Players' Dictionary. Remember that, to use it, you'll need
*i threeLets.rex
Planning out a strategy for this problem before diving in to the coding is a good thing! You will want to define and use one or more helper-functions to keep your definition of bestWord simple and elegant. Our solution's functions use a total of six rules, not including wordScore and rmv1 (from last week), which we needed. If you're getting toward 15 or more rules, you might consider redesigning your solution...
part2.rex Pair or individual problems, #6 through #10 and ex. cr.
You're welcome to work on the second half of this week's problems on your own, but we'd encourage you to do so with a partner, if you'd like. If you do work in a pair, be sure to work at the same physical place and to trade off at the keyboard/debugging roles, as described in the syllabus.
Whether you work on your own or with a partner, you should submit your definitions for these functions in a file named part2.rex.
Problem 6: lg2_tail, fib_tail
[10 points, pair or individual]
The first half of this problem is to write a tail-recursive version of the lg2(x) function you wrote as problem 2 of hw1. Name this function lg2_tail(x).
Remember that tail-recursive functions do no computation after their recursive
calls -- though they almost certainly need to do some computation before
making their recursive calls. In addition, you will need to write a helper
function that uses at least one additional argument (the accumulator).
The behvaior will be the same as lg2:
test( lg2_tail( 7 ), 3 );
test( lg2_tail( 8 ), 3 );
test( lg2_tail( 9 ), 4 );
For the second half of this problem, write fib_tail(n), a tail-recursive
function that takes in a nonnegative integer n and outputs the first
n elements of the Fibonacci sequence: 1, 1, 2, 3, 5, 8, 13, 21, 34, ....
Here are some tests:
test( fib_tail( 0 ), [] );
test( fib_tail( 5 ), [1,1,2,3,5] );
Hint: You may want more than one base case for fib_tail. You also may find it easier to accumulate the terms of the Fibonacci sequence in reverse order and then reverse the result at the very end. Additional arguments will help!
Problem 7: indivisibles
[10 points, pair or individual]
Write indivisibles( d, L ), whose first input is a nonnegative integer d
and whose second input is a list of integers L. Then, indivisibles
should return a list of the elements from L that are not divisible
by n. No integer is divisible by zero. For instance,
test( indivisibles( 2, [0,1,2,3,4] ), [1,3] );
test( indivisibles( 3, [0,1,2,3,4] ), [1,2,4] );
test( indivisibles( 0, [0,1,2,3,4] ), [0,1,2,3,4] );
SEED warning! Rex has an odd way of outputting some of the above tests: depending on how you implement indivisibles you may see an expression beginning with [1 | (seed (x) => . Don't worry about this! If the first word of the test output is ok, your function has gotten it correct.
Problem 8: reachable
[10 points, pair or individual]
This problem asks you to write a Rex function that operates on another data structure -- directed graphs -- and, in particular, graphs that are represented as a list of [parent, child] pairs. The graphs are called directed, because each pair is an edge in only one direction: it represents an edge from parent to child, but does not mean there is necessarily an edge from child to parent.
Terminology reminder: a predicate is simply a boolean-output function, i.e., one whose output is 0 or 1.
For this problem, write a predicate named reachable(a,b,G) that answers the question of whether or not you can get from "point a" to "point b" in the directed graph G. Specifically, the first two inputs to reachable are nodes in the graph G, and the graph itself is the third input.
Then, reachable returns 0 if there is no path from a to b, and it returns 1 if there is a path from a to b (possibly through other nodes). Any node is always reachable from itself.
The reachable predicate will only be given ACYCLIC graphs as input. Thus, you don't have to worry about "running around in circles" searching for whether there is a path from a to b: there will be no cycles in the graph. Also, remember the graphs are directed. For example,
test( reachable("A", "F", [ ["A","D"], ["B","D"], ["C","D"],
["A","E"], ["D","E"], ["E","F"] ]), 1 );
test( reachable("C", "A", [ ["A","B"], ["B","C"] ]), 0 );
test( reachable("D", "D", [ ["A","B"], ["B","C"] ]), 1 );
Problem 9: mostKids
[10 points, pair or individual]
The function mostKids( G ) takes in a directed graph G. It should return the
node in G that has the largest number of children. There may be more than one
such node -- in that case, your mostKids function may return any one of them.
Also, you may assume that mostKids will only receive input graphs that have
at least one edge. For example,
test( mostKids([ ["D","A"], ["D","B"], ["D","C"], ["E","A"],
["E","D"], ["F","E"], ["A","F"] ]), "D" );
test( member( mostKids([ ["C","B"], ["B","A"] ]), ["C","B"] ), 1 );
Hint: you may want to use some of the graph functions we wrote in class to help with this problem -- or write new ones of your own.
Problem 10: delete
[10 points, pair or individual]
For this problem, you'll write a function delete( x, T ) that takes in a piece of data x and a binary search tree T. The function delete should return a new binary search tree, identical to T, but with x removed. If x is not present in T, then delete should return a BST identical to T.
We will cover/have covered this algorithm in class, but here is a quick recap. If x has only empty subtrees, then its branch is straightforward to delete. Similarly, if x has only one nonempty subtree, that subtree replaces the BST rooted at x. The trickiest case is when x has both a nonempty left and right subtree: in that case, you should replace x with the smallest value in the tree that is larger than x.
Here are two tests to try, along with four tree definitions to
make them easier to work with:
// example trees
T1 = [10, [3, [], []], [42, [20, [], []], [60, [], []] ] ];
T2 = [20, [3, [], []], [42, [], [60, [], []] ] ];
T3 = [42, [21, [12, [], []],
[41, [27, [], []], []] ], // end of left subtree
[60, [47, [44, [], [46, [], []]], [58, [], []]],
[77, [], [100, [], []]] ] ]; // end of right subtree
T4 = [44, [21, [12, [], []],
[41, [27, [], []], []] ], // end of left subtree
[60, [47, [46, [], []], [58, [], []]],
[77, [], [100, [], []]] ] ]; // end of right subtree
test( delete( 42, T3 ), T4 );
test( delete( 10, T1 ), T2 );
Totally optional extra credit...
You're welcome to try these on your own or in a pair. These problems have been described as "challenging, fun, and important" by unbiased reviewers (Prof. Ran).
In addition, the first problem below, #11, will be on the HW next week. If you succeed at it this week, you earn credit for it both times... .
Optional extra credit ~ problem #11: shortestPath
[up to +10 points, pair or individual]
The shortest-path problem asks how to most efficiently get from "point A" to "point B" in a graph -- it is thus a generalization of the reachable function. Since many problems in computer science boil down to questions about graphs, the shortest-path problem has many applications: providing the best map-directions, minimizing the cost of manufacturing procedures, and finding the most efficient layout of components on a microprocessor board, as just a few examples.
For example, in the directed graph
G1 = [ ["A","B"], ["B","C"], ["C","D"], ["D","E"], ["B","E"] ];
For this problem, write shortestPath( a, b, G ) that
returns a list of nodes visited along a shortest path from a to
b in G. There may be more than one shortest path --
in that case returning any one of them would be OK. For example,
provided G1 was defined as above:
test( shortestPath( "A", "E", G1 ), ["A", "B", "E"] );
test( shortestPath( "E", "E", G1 ), ["E"];
test( shortestPath( "E", "A", G1 ), [] );
As in the reachable function, you may assume that G is acyclic.
Submitting your work
Be sure to submit both your part1.rex and part2.rex files at the CS 60 submission site under "Week 2."
Submitting pair programs: Partners who have created one file together should each submit that file, under their own names. You may have to close the browser and then re-open it, in order to log in as the other person.
Problems with submission? Drop me an email at dodds - AT - cs.hmc.edu.
Link to the CS 60 submission site
Back to the top-level assignments page
Back to the top-level CS 60 page