In this homework you will have the chance to familiarize yourself with the Scheme programming language. Scheme is considered a very "clean" language, with a minimal syntax: few punctuation and formatting rules. In fact some might argue it's too minimal! As a result, Scheme is one of the best examples of a language whose focus is supporting computation itself, as opposed to intricate data structuring. In this assignment you'll implement some useful and some silly but fun functions to familiarize yourself with Scheme and to re-familiarize yourself with recursion.
Design and formatting account for roughly a quarter of the credit
for each function or program you complete.
Design, here, means algorithm design, that is, how you break a problem
down into smaller pieces and then compose those pieces into an overall solution.
Large, convoluted functions are difficult to understand (and debug!). Use
small, clear functions with lots of small helper functions, as necessary.
Formatting includes coding style: clean and clear structure, meaningful
variable and function names, ample use of spacing, and indenting that reflects
code structure.
As for commenting,
in each assignment we ask you to include
Important warning about function names! Be sure to name your functions as indicated in the problem statements below -- including capitalization and punctuation! This helps our graders, who can automate the running of many tests using those function names. Helper functions may have any name you like, but they should be descriptive and appropriate. When graders have to manually change your function names to match the ones in the homework problem descriptions, it angers them -- and a key guideline for CS 60 is not to anger the graders!
Computation in the form of software is useful to the extent that it works. But it only works to the extent that it has been tested! Testing your own software thoroughly is important -- we use test cases to check how well your functions work, and you will certainly want to do the same!
Some test cases are indicated for each of the problems. These can be copied from this assignment site into your code. When you use auxiliary functions, it is good practice (and will save time in the long run) to include tests for them as well. A small but non-trivial part of your grade each week may be based on how well you test your programs, so you should create at least one (more where appropriate) additional test for the primary functions, too!Obtain access to the PLT Scheme/Dr. Scheme programming environment, either by downloading it to your personal computer or by using the CS lab. On the lab Macs, Scheme is located as follows:
For this problem
define a function, named erdos, with one argument, N. Thus, your definition will begin as follows:
(define (erdos N)This function should compute the following:
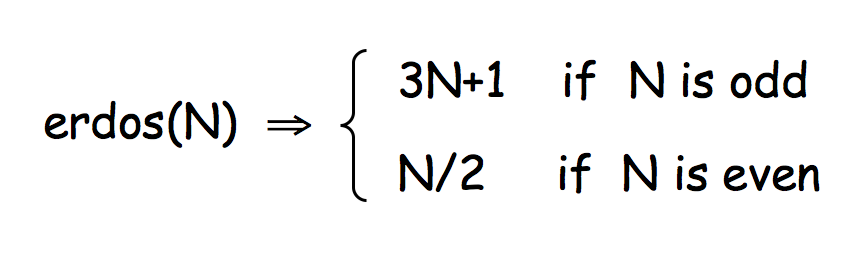
(test (erdos 3) 10)Iterating this simple function leads to surprisingly difficult mathematical challenges, as this link (and the next function) suggests. The name erdos is from the mathematician Paul Erdos and is (very roughly) pronounced air-dish.
(test (erdos 10) 5)
Write erdosCount, a function of one postitive integer argument:
(define (erdosCount N)where erdosCount should return the smallest number of times erdos must be iterated, when started with an input of N, in order to arrive at a value of 1. Let's use the symbol ==> to mean "evaluates to." Then, (erdosCount 3) ==> 7, because
(erdos (erdos (erdos (erdos (erdos (erdos (erdos 3))))))) ==> 1and there are 7 applications of erdos above. Here are two more tests:
(test (erdosCount 26) 10)Be sure to use recursion when writing erdosCount. As a starting point, consider how we wrote length in class.
(test (erdosCount 27) 111)
Aside It is an open question in mathematics whether or not (erdosCount N) halts for every positive integer N. It does halt for all of the values of N for which it has been tried; it is conjectured always to halt, but no one has proven it one way or the other. Paul Erdos famously quipped that "mathematics is not ready for such problems." The fact that a general-purpose "haltchecking" program would be powerful enough to answer this century-old conjecture hints at how strong a capability "haltchecking" actually is... . The state-of-the-art understanding of this 3x + 1 problem is available at this link.
In class, you saw how (remove e L) works: it returns a list identical to L, except with the first top-level instance of e removed.
For this problem, write (removeAll e L), which should return a list identical to L, except that all
top-level instances of e have been removed. For example,
(test (removeAll "i" '("a" "l" "i" "i" "i" "e" "n")) '("a" "l" "e" "n"))
(test (removeAll "i" '( ("a" "l" "i") "i" "i" "e" "n" )) '(("a" "l" "i") "e" "n"))
(test (removeAll 0 '(1 0 1 0 1 0)) '(1 1 1))
This problem does not ask you to write any code; instead it asks you to reason about two provided function definitions.
Consider the following two definitions of a removeLast function. removeLast is like remove, except that it removes the last top-level instance of e (the first argument) from L (the second argument). As usual, in fact, L is not changed at all; rather, removeLast returns a new list.
Definition 1:
(define (removeLast1 e L)
(let ((c (count e L)))
(removeLast1-help e L c)) )
(define (removeLast1-help e L c)
(cond
[ (and (= c 1) (equal? e (first L))) (rest L) ]
[ (equal? e (first L)) (cons (first L) (removeLast1-help e (rest L) (- c 1))) ]
[ else (cons (first L) (removeLast1-help e (rest L) c)) ] ))
(define (count e L)
(cond
[ (null? L) 0 ]
[ (equal? e (first L)) (+ 1 (count e (rest L))) ]
[ else (count e (rest L)) ] ))
(define (removeLast2 e L)In a comment in your hw1part1.scm file, indicate what the (worst-case) big-O running time is for each of these two definitions of removeLast. Explain your answers informally - no more than a sentence or two is needed.
(cond
[ (null? L) L ]
[ (and (not (member e (rest L))) ;; if it's NOT in the rest
(equal? e (first L))) (rest L) ] ;; but IS the first...
[ else (cons (first L) (removeLast2 e (rest L))) ]
))
Write a function (find L M), taking in two lists L and M, such that find returns true (#t in Scheme) if L is a sublist of M. find should return false (#f) otherwise.
Note that the empty list is a valid sublist of any list at all. On the
other hand, no non-empty list is a sublist of the empty list.
Also, because find deals with sublists, not subsequences, all of the top-level elements of L
must appear consecutively and contiguously at the top level of M in order to yield #t. For example,
(test (find '(1 2 3) '(0 1 2 3 4)) #t)Here are a few other tests -- you should devise a few of your own, as well!
(test (find '(1 2 3) '(0 1 2 2 3 4)) #f) ;; they're not contiguous
(test (find '() '(1 2 3)) #t)Hint It may be helpful to use a second, helper function to handle the contiguous-element checking here... .
(test (find '(1) '()) #f)
(test (find '(1 2) '(2 1 1 1)) #f)
(test (find '(1 2) '(2 1 1 (1 2))) #f) ;; an element is not a sub-list
(test (find '(1 1 3) '(2 1 1 2 3 1)) #f)
Run-time analysis: In a comment in your code, describe an example of a three-element list L and a six-element list M that requires your find function to do the most work. That is, what inputs cause the largest number of equality-comparisons between elements to be made? Also, suppose that the inputs to find are of length N and 2N, respectively. What is the resulting worst-case big-O running time of your find function?
Write a variant of reverse named (superreverse L), whose input L will be a list that may contain
lists as some of its elements.
superreverse should output a list identical to L, except that all of its top-level
lists should be reversed. For example,
(test (superreverse '( (1 2 3) (4 5 6) 42 ("k" "o" "o" "l") ("a" "m") ))
'( (3 2 1) (6 5 4) 42 ("l" "o" "o" "k") ("m" "a") ) )
(test (superreverse '( (1 2 3) (4 5 6 (7 8) 9 ) ))
'( (3 2 1) (9 (7 8) 6 5 4) ) )
Next define (duperreverse L), which returns a list whose structure is a complete reversal
of L's. For example,
(test (duperreverse '( (1 2 3) (4 5 6) 42 ("k" "o" "o" "l") ("a" "m") ))
'( ("m" "a") ("l" "o" "o" "k") 42 (6 5 4) (3 2 1) ) )
(test (duperreverse '( (1 2 3) (4 5 6 (7 8) 9 ) ))
'( (9 (8 7) 6 5 4) (3 2 1) ) )
Scheme's built-in function (list? x) returns #t if and only if x is a list;
otherwise it returns #f.
For the purposes of this problem, consider any data type that is not a list to be atomic, that is, it
can not be broken down to be reversed.
In class, we looked at a function that finds its input's smallest factor greater than one:
;; function: spf (smallest prime factor)For this problem, you should use these two functions (copy them into your file) in order to write two more.
;; input: an integer, N > 1
;; output: the smallest factor of N greater than 1
(define (spf N)
(spf-from 2 N))
;; function: spf-from
;; input: two integers, low > 1 and N > 1
;; output: the smallest factor of N that is
;; greater than or equal to low
;; if low >= N, this function returns N
(define (spf-from low N)
(cond
[ (>= low N) N ]
[ (equal? (remainder N low) 0) low ]
[ else (spf-from (+ 1 low) N) ]
))
(test (is-prime 28) #f)
(test (is-prime 97) #t)
fully-factor
Continuing in the vein, next write (fully-factor N), which takes in an integer N > 1 and returns an
ascending-sorted list
of all of the prime factors of N. For example,
(test (fully-factor 28) '(2 2 7))
(test (fully-factor 97) '(97))
Run-time analysis: Lastly, state the big-O running time of both your is-prime and your fully-factor functions in an accompanying comment. Write a sentence or two informally defending your running-time claim.
Construct the function number-each, which expects a single argument that is an
arbitrary list, say L. It then returns an association list of 2-lists, where each 2-list consists of an
ordinal number, starting with 1, followed by the corresponding element of L. For example,
(number-each '(jan feb mar apr)) ==> ((1 jan) (2 feb) (3 mar) (4 apr))Hint: Use a more general auxiliary function to do most of the work.
(number-each '(I II III IV V VI)) ==> ((1 I) (2 II) (3 III) (4 IV) (5 V) (6 VI))
(number-each '()) ==> ()
Association lists, or "a-lists" for short, are always lists of lists. For example, the above function, number-each outputs association lists. they are often used serve as data repositories, as this problem illustrates using the example of scrabble-letter scores.
The function (assoc e A) takes in an a-list A (remember that A contains lists of lists) and returns the element of A whose own first element is equal to e. For example:(assoc 3 '((1 jan) (2 feb) (3 mar) (4 apr))) ==> (3 mar)As the second example shows, assoc returns #f when e does not appear as a first element of any of A's sublists.
(assoc 5 '((1 jan) (2 feb) (3 mar) (4 apr))) ==> #f
In this
problem we want to use an association-list to score information about scrabble tiles. The following Scheme
statement defines an A-list that provides all of the letter scores. You should copy this
code into your hw1part2.scm file:
;; scrabble-tile-bagThe notation #\a is Scheme's way of representing single-character literals.
;;
;; letter tile scores and counts from the game of Scrabble
;; the counts aren't needed (but don't hurt)
;; obtained from http://en.wikipedia.org/wiki/Image:Scrabble_tiles_en.jpg
;;
(define scrabble-tile-bag
'((#\a 1 9) (#\b 3 2) (#\c 3 2) (#\d 2 4) (#\e 1 12)
(#\f 4 2) (#\g 2 3) (#\h 4 2) (#\i 1 9) (#\j 8 1)
(#\k 5 1) (#\l 1 4) (#\m 3 2) (#\n 1 6) (#\o 1 8)
(#\p 3 2) (#\q 10 1)(#\r 1 6) (#\s 1 4) (#\t 1 6)
(#\u 1 4) (#\v 4 2) (#\w 4 2) (#\x 8 1) (#\y 4 2)
(#\z 10 1) (#\_ 0 2)) ) ;; end define scrabble-tile-bag
;;
;; The underscore _ represents a blank tile.
;; The notation #\a is Scheme's unusual character notation
(score-letter #\w) ==> 4
score-word
Next, construct a function score-word that determines the score for a string of letters.
Note that strings in Scheme are not the same as symbols, nor are characters the same as strings (as in Python).
Strings are doubly quoted. The built-in functions string->list and list->string,
which convert from strings to lists of characters and vice-versa, may be of use. Here are examples of them in action:
(string->list "hi") ==> (#\h #\i)Here are three tests of score-word:
(list->string '(\#h \#i) ) ==> "hi"
(test (score-word "zzz") 30)
(test (score-word "fortytwo") 17)
(test (score-word "twelve") 12)
For totally optional extra credit of up to +15%,
define a function best-word as follows:
(define (best-word rack wordList)Thus, best-word takes two inputs: a string of letters rack and a list of legal strings named wordList. Then, best-word should return a list of two elements: the return value's first element should be the highest-scoring word from wordList that can be made from the letters in rack. The return value's second element should be the score of that highest-scoring word. If there is a tie, any one of the strings in the wordList with maximal score may be returned. When we test your code, we will make sure that the highest-scoring word in each test case is unique.
(best-word "academy" (list "ace" "ade" "cad" "cay" "day")) ==> ("cay" 8)
(best-word "appler" (list "peal" "peel" "ape" "paper")) ==> ("paper" 9)
(best-word "paler" (list "peal" "peel" "ape" "paper")) ==> ("peal" 6)
Note that "paper" could not be made in the third example, because the rack had only a single #\p.
Hint: planning out your strategy for this problem before diving in to the coding is a good thing! In particular, you will want to define and use a number of helper-functions to keep your definition of best-word simple and elegant. You'll want to keep the helper-functions short, as well!