Harvey Mudd College
Computer Science 60
Assignment 7, Due Monday, November 5, 11:59pm
Unicalc and Unilang
Here is the starter code for hw7: hw7.zip
This homework asks you to use Java to implement the Unicalc application that you completed
in Scheme in weeks 2 and 3. You will use the OpenList data structure
as the fundamental building block - OpenList, after all, is designed to implement
Racket-like list structures. Because Java is organized around creating
and combining data structures, we will Java-ize Unicalc in four parts:
- writing a Quantity class that represents a quantity list. This class
will have the functionality of all of Unicalc.
- writing (adapting) a Tokenizer class that converts raw Strings
to arrays of tokens.
- writing (adapting) a Parser class that converts an array of tokens to
a parse tree. Note that the parse tree will be represented as an OpenList.
- writing (adapting) an Evaluator class that converts a parse tree
to a value (that is, an object of type Quantity). Also, the
Evaluator will print out various pieces of the task.
Why so much code provided? I'd prefer to write the application myself... .
Please do! With the support code we are balancing two valid concerns: on
one hand, there is a deep understanding that only a from-scratch implementation
can provide. On the other hand, we want to provide enough examples and framework to build
familiarity with what are certainly intricate - and important! -
computational ideas. There is also an example languages: the MiniMath
language that we extended in class.
Here is a link to that MiniMath example as extended in class, in a zip file...
Feel free to use as much - or as little - of the
support code as you wish. One important thing we do ask if you implement from scratch is to use (or replicate) our toString
conventions, so that we can check your results efficiently! Also,
please adhere to the interfaces we provide (names of functions,
parameters, return types, etc).
The goal of this assignment is that you have hands-on experience with (and, we hope,
insights into) the processing
that is part of implementing all computer languages. Using the starter code or building from
scratch, we believe, can both provide that foundation.
Submitting your code
Please submit the following files zipped in an archive named hw7.zip:
- OpenList.java (whether you use ours or yours)
- Quantity.java (Problem 1) and
- Tokenizer.java (Problem 2) and
- Parser.java (Problem 3) and
- Evaluator.java (Problem 4) and
- extra.zip if you try the extra credit...
Submit your zip archive in the usual way, under homework #7.
Because the .java files you write this week will be
interdependent, keep them all in a single folder/directory named
hw7 That way,
java will be able to find classes as it needs to. Also, it
will be easy to zip up that directory to submit.
Part 1: Unicalc in Java via Quantity
30 points
This is the implementation - really a port - of Unicalc's functionality
into a Quantity class in Java.
Since this problem was also the extra-credit last week, its details and tests
are explained on this page.
There are both tests in the provided main and in the separate
QuantityTester.java file in order to check if your implementation
of quantity lists is correct.
Part 2: Tokenizer
10 points
A Tokenizer.java file provided for you in the code at the top-level assignment page.
You will want to improve it so that the Unicalc language's tokens are found correctly
whether or not spaces are inserted around the operators.
Other things are possible here, too, if you decide to add your own features to the
language, but for the required part of the language, this file will require the fewest
changes.
Notes on the tokenizer:
- The expression 42~1 m represents 42 m with an
uncertainty of 1. The provided parser will handle parsing this into
a Quantity list... however, your tokenizer will need to
separate the ~ (tilde) token in order for it to do so!
- You do not have to tokenize input strings to separate
numbers from variable names. (You're welcome to try this, if you'd like, but
it's not needed.) We will only test your language with spaces separating
numbers from units (or variables).
Thus, you don't have to worry about 3m/s.
We'll always input that as 3 m/s.
Part 2: Parsing the Unicalc language via Parser
30 points
This problem asks you to implement a Parser for the Unicalc language, whose grammar and
parse trees are are summaried in this picture.
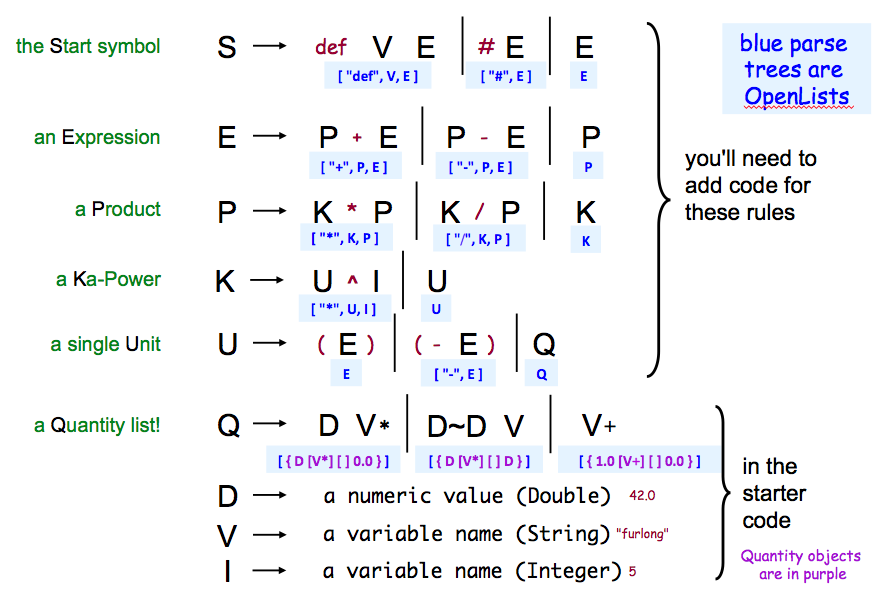
More detail on some fo these are below... .
Notes on this grammar
Symbols listed in red are terminal symbols. Similarly, doubles, ints and strings are
also terminals.
The rule for Q uses the asterisk, not as "times," but
meaning "zero or more of the preceding symbol." It also uses the plus sign, not as addition,
but meaning "one or more of the preceding symbol." This Q rule
is already
implemented in the provided Parser.java file. D,
I, and V are also already implemented. You will only need to implement
rules U and above.
Parser.java implements a recursive-descent parser for part of
the above grammar; your task is to extend it to the rest of the grammar.
Reminders about parsing:
-
The method that will begin all the work - even though all of that work will be
delegated recursively - is parse:
public OpenList parse(String[] tokens) This method should return
a new object of type OpenList that represents the parse tree for that set of tokens.
-
We will not test your code on invalid sets of tokens:
- There will be no unmatched parentheses.
- We won't use negation except as the grammar indicates (none of
the numbers will be negative).
and so on... . It's still a good idea to include checking to see if there
are tokens remaining as you write your parser, because as you debug the
parser those checks may get used - they did when we implemented it!
That said, we won't check what your language will do on inputs that
don't match the grammar.
-
Examples for testing your Parser (and tokenizer)
Here are a sizable number of examples, roughly in the suggested implementation order
of the Parser's rules, so that it's reasonable
if you test them in this order, as you implement.
Assignment 7's tokenizer and parser tests.
-
Suggested strategy for Parser
One way to build up to the full grammar is to implement
one nonterminal method at a time and then test it to be sure that
your rule works. The parse trees above can be used in the order they're presented
you implement the rules in a similar order:
- first, E
- then, P
- then, K
- then, U
- then, finally, S
This is a great way to build up functionality incrementally, and it's roughly the
order of difficulty in implementation - especially if you use the MiniMath language
as a guide.
Warning! if you use the order suggested above, BE SURE
you are changing the start symbol that is called in the parse method! Also, be sure that
the lowest-implemented method calls Q until methods lower in the grammar can
replace it. To be even more concrete, here is a summary of the symbols you'll need to
change as you implement - and test - these Parser methods one at a time:
public OpenList E() // be sure to change parse to call E and change E to call Q and E (not P and E)
public OpenList P() // be sure to change E to call P and change P to call Q and P (not K and P)
public OpenList K() // be sure to change P to call K and change K to call Q and I (not U and I)
public OpenList U() // be sure to change K to call U and change U to call Q and E (as it should)
public OpenList S() // be sure to change parse to call S and change S to call E and V, as appropriate
-
Note on negation: note that in our language, negation can only happen immediately
inside a left parenthesis. This makes it considerably easier to parse. Depending
on how you tokenize, providing negative numbers may or may not yield the "-"
token. In order not to worry about these ambiguities in implementation, your language
will only be tested with positive quantities, and negation will be tested as the U
rule indicates, by including a minus sign immediately after a left parenthesis.
-
Note on the "defining" rule, S: The S rule
introduces a new operator, the string "def". The parse tree that
is returned for this operator should be ["def", V, E], where V
will be a String and E will be a suitable parse tree starting with
that E symbol in the grammar. The behavior of def is
both to return the value of E (easy) and to remember that value
within the variable represented by V. This latter part is more challenging,
but it's the job of the evaluator, so we procrastinate worrying about it until then!
Your parser simply will want to return the correct parse tree, and for that, the def
operator is relatively straightforward to implement.
-
Testing your code
The main method is already written to make this easy - you should be
able to try out all of the above test (and more of your own) to be sure
that your Parser
is working correctly.
(You don't need to submit additional tests for this problem.)
Part 4: Evaluating the Unicalc language via Evaluator
30 points
This part completes the unicalc language. Here, you should build/extend the
Evaluator class that will convert parse trees into objects of
type Quantity.
What does everything evaluate to? Well, every valid statement
in the Unicalc language evaluates to an object of type Quantity, that is, a
quantity list.
For example, the parse tree which is simply a list of a Quantity
naturally evaluates to that Quantity object.
Notes on the Evaluator:
-
Some of the others parse trees are clear in
how they will evaluate. They're very similar to the MiniMath example,
and you will have methods in Quantity that handle them:
- multiplication
- division
- power
- negation
- normalizing A parse tree of the form [ "#", E ] should evaluate to
a normalized object of type Quantity. This will take advantage of norm
and norm_unit in your Quantity class. It also requires a database of units
in which to do the normalizing. To start, you should use the database provided by the Quantity.getSmallDB()
method. (The last part of the language, def will let you replace this database with one built on-the-fly.)
To make it easy to use any association list as a database, you might include thes lines
at or near the top of the evaluate method in Evaluator.java:
// DB is the unit database in which the expression is evaluated, if needed
// when you implement def, this should change the line
// OpenList DB = Quantity.getSmallDB(); to the line
// OpenList DB = this.env;
OpenList DB = Quantity.getSmallDB();
- adding A parse tree of the form [ "+", P, E ] should evaluate
to an object of type Quantity by using the add method. This requires a database
because both subtrees should be normalized and checked for equivalent normalized units before adding.
To begin, the same database obtained by Quantity.getSmallDB() is the one to use.
- subtracting should be handled by using addition and negation appropriately. Note that
this handling is happening in the evaluation step, not the parsing step: subtraction is still parsed
as you'd expect.
- grouping is never even seen by the evaluation stage -- parentheses are all resolved
during the parsing!
- defining variables is the most open-ended and challenging part of this assignment.
First, the parse tree [ "def", V, E ] should simply evaluate to the value of
E, which will be an object of type Quantity.
This functionality is what you'll want to get working initially.
However, the much more important function of def is that
it should add an association to the front of the evaluator's association list representing
the environment in which the evaluator does its work!
This requires some explanation. First, an example: we'd like to be able to assign
42 m to x and then use that value in the future. For example:
def x 42 m # defines x to be 42 m
18 m + x # asks, what is 18 m plus x
In order to do this, you will need to use the private OpenList env data member to your Evaluator class.
That data member is there in order to represent an association list of variable names with their values.
It starts out empty, which is a valid association list, and unused.
Each time your evaluator sees a def statement, it should add a binding of the value of E to the
variable name V in the association list this.env! This "binding" is nothing more than
an OpenList with two elements: the String V and the Quantity that's the value
of E. To illustrate this, here is the full set of interactions from the two lines above. To
See the env data member, you'll need to set the PRINT_ENV variable to true:
def x 42 m
The tokens are < def, x, 42, m >
The parseTree is [def, x, [{ 42.0, [m], [], 0.0 }]]
The value is { 42.0, [m], [], 0.0 }
The current env is
[
[x, { 42.0, [m], [], 0.0 }] // NOTE: no longer empty!
]
18 m + x
The tokens are < 18, m, +, x >
The parseTree is [+, [{ 18.0, [m], [], 0.0 }], [{ 1.0, [x], [], 0.0 }]]
The value is { 60.0, [m], [], 0.0 } // CORRECT RESULT!
The current env is
[
[x, { 42.0, [m], [], 0.0 }]
]
Note that the current env is no longer empty after the initial def statement.
Now its association list contains one association: the variable x is associated with
the Quantity { 42.0, [m], [], 0.0 } (this is a Quantity, not a string!)
Then, it gets used in the future in order to look up the values of variables!
How could my code "look up" the value of a variable? Since this.env
is an association list, the assoc method already in your
OpenList class is all you'll need. [[But wait, there's more!]]
Since you most likely already use assoc in your Quantity
class's norm_unit method, all you'll need to so is to pass
this.env as the third input to add or as the second input
to norm in order to use the values of the defined variables. Neat!
How do I know whether something is a unit or a variable?
There is no difference! In the above example, x was looked up and m
was looked up!! Everything gets looked up -- but only some of the strings
are actually in the association list - it's those that get used. The rest are basic, uninterpretable
units that are handled as the units in the numerator and denominator. To begin, all
variables are simply uninterpretable units.
What if x gets redefined? This special case isn't special at all -- simply
cons the new binding (two-element OpenList) at the top of this.env. Then, assoc
will find the latest, front-most binding, ignoring previous ones!
Once you have your environment, this.env working, you can replace the default
database of units, obtained from Quantity.getSmallDB, with this.env: it
becomes a database of units created "on-the-fly." Here is another detailed example of
how your language would use create that database.
We will only print the env to keep things brief:
def mile 5280 foot
The current env is
[
[mile, { 5280.0, [foot], [], 0.0 }]
]
def league 0.125 mile
The current env is
[
["league", { 0.125, ["mile"], [], 0.0 }],
["mile", { 5280.0, ["foot"], [], 0.0 }]
]
def mile 1760 yard
The current env is
[
["mile", { 1760.0, ["yard"], [], 0.0 }],
["league", { 0.125, ["mile"], [], 0.0 }],
["mile", { 5280.0, ["foot"], [], 0.0 }]
]
where we'd redefined "mile" and updated env at the top;
assoc will "do the right thing" by taking that topmost match.
The test cases, below, show more examples of this use of the environment... .
Testing your code
When the graders run your file, they will make sure to enable the
printing of all of the tokens, parse trees, evaluations, and the environment in
order to get a full picture of the behavior of your language.
Here are a pretty extensive list of examples, including
the printout of the input line,
the tokens, parse tree, value, and - when of interest -
the environment association list in this.env each time.
They're the same as the parse trees above, but now with
the evaluation results.
Assignment 7's tests including evaluation and (when applicable) the this.env environment.
These are the tests we will use in grading the code, so if it
passes all of these - perfect!
Optional extra credit: personalization or functionalization!
Personalizing For up to +5 (or more) points, improve the unicalc-language with whatever
feature you'd like... . Here are the rules, however:
- be sure not to change or break valid statements in the language as specified in the assignment (so we can still grade it!)
- in a comment at the top of Evaluator.java document what you did and how we can test it.
Again, give the graders a couple of examples to try.
Functions! For up to an additional +20 points, provide an implementation of functions in the
Parser and Evaluator
of the unicalc language. How to design and implement this is 100% up to you.
Warning: If you try this, be sure not to edit the only copy of your
unicalc language files! -- implementing functions is tricky, and it's happened that
people have broken their language in the attempt to do so!
Be sure to work on a copy of your files -- and then, if you submit this, please place
those new files into a folder named extra and zip that folder. There is a spot in
the submission site to upload extra.zip for this extra-credit challenge.
Be sure to include a comment at the top of your new Evaluator.java
on how we could best test your code - give the graders a couple of examples to try!
Here is a (very small) image of one possible grammar for introducing functions into the language.
It's not the only approach, to be sure. Click on the image for a larger version.
