
You've already completed the back-end API that performs all of the Unicalc calculations (with error propagation!). This week you will make a user-friendly front-end, implementing a language based on quantities. Implementing the language will require you to have a code to tokenize the input, code to parse the input, and a function to evaluate the parse trees. Examples and starting points for the Parser and Evaluator are provided on the main assignments page.
The language lets you evaluate expressions, and to extend the database with new constants or units. Here is a sample interaction that you can use to check your results and to make sure you understand what you are trying to do with the evaluator. There are a few things that are helpful to know when reading the following transcript:
~" appears between two numbers, it means "plus or minus", so the first portion of the interaction is telling us that 14 +/- 4 meters added to 9 +/- 3 meters results in 23 +/- 5 meters.
> java Unicalc input> 14~4 m + 9~3 m Tokens: [14, ~, 4, m, +, 9, ~, 3, m] AST: Sum(Product(Value(14.0 ~ 4.0),Value(1.0 ~ 0.0 m)),Product(Value(9.0 ~ 3.0),Value(1.0 ~ 0.0 m))) Result: 23.0 ~ 5.0 meter input> 60 Hz * 30~1 s Tokens: [60, Hz, *, 30, ~, 1, s] AST: Product(Product(Value(60.0 ~ 0.0),Value(1.0 ~ 0.0 Hz)),Product(Value(30.0 ~ 1.0),Value(1.0 ~ 0.0 s))) Result: 1800.0 ~ 60.0 Hz s input> # 60 Hz * 30~1 s Tokens: [#, 60, Hz, *, 30, ~, 1, s] AST: Normalize(Product(Product(Value(60.0 ~ 0.0),Value(1.0 ~ 0.0 Hz)),Product(Value(30.0 ~ 1.0),Value(1.0 ~ 0.0 s)))) Result: 1800.0 ~ 60.0 input> # 364.4 smoot Tokens: [#, 364.4, smoot] AST: Normalize(Product(Value(364.4 ~ 0.0),Value(1.0 ~ 0.0 smoot))) Result: 364.4 ~ 0.0 smoot input> def smoot 67 in Tokens: [def, smoot, 67, in] AST: Define(smoot,Product(Value(67.0 ~ 0.0),Value(1.0 ~ 0.0 in))) Result: 67.0 ~ 0.0 in input> # 364.4 smoot Tokens: [#, 364.4, smoot] AST: Normalize(Product(Value(364.4 ~ 0.0),Value(1.0 ~ 0.0 smoot))) Result: 620.13592 ~ 0.0 meter
S -> def W L | L
L -> # E | E
E -> P + E | P - E | P
P -> K * P | K / P | K
K -> - K | Q
Q -> R | R Q
R -> V | V ^ J
V -> D | D ~ D | W | ( L )
J -> I | - I
I -> (any nonnegative integer)
D -> (any nonnegative number, integer or floating-point)
W -> (any word that is a unit name)
More discussion of this grammar appears below in Part 2.
The tokens in the Unicalc language include
Near the start of Unicalc.java we need a function tokenize that takes a single string, and sets this.tok to a list of all tokens appearing that string. Specifically, your function should set this.tok to be a new LinkedList<String>, with each string in this list being a single token.
This doesn't require many lines of code. All it needs is:
See MakeDB.java or the Lecture 18 slides for examples of Pattern and Matcher and Java regular expressions. The documentation for Pattern also lists all the notation and abbreviations that can appear in a Java regular expression.
If your tokenizer is working correctly, when you run the Unicalc main function the provided parsing code should already handle extremely simple inputs, including
For this part, you need to implement the rest of the recursive-descent parser for the Unicalc language, according to the grammar shown above.
As discussed in class, for each variable/nonterminal in the grammar there should be exactly one parsing method whose job is to consume a prefix of the remaining input, a prefix derivable from that nonterminal in the grammar. By peeking at the upcoming token or tokens (if necessary), each function should decide which production rule corresponds best to the input.
Development Strategy. We strongly suggest you start from the bottom of the grammar up. First start with R(), and make sure your parser can handle strings derivable from R in the grammar, like meter^2 or (3)^-1. Then get Q() working, and try it on strings derivable from Q in the grammar like 2 meter or 9.8 meter^2 second^-1. Then move on to K(), to P(), and so on.
Parser output. As discussed in class, we want the parser (and each parsing function) to construct a tree representation of the parsed input, because trees make the structure of the input obvious, and are easy to work with.
The file AST.java provides an interface AST that describes any Unicalc abstract-syntax-tree node: it has to have eval(...) and toString(...) methods. It also provides all the classes you will need for representing nodes in an abstract syntax tree for Unicalc, including:
Here is the grammar again. The comments suggest how you might build and return abstract syntax trees, if the input matches the right-hand-side of the corresponding rule
GRAMMAR AST to return
---------- -------------
S -> def W L new Define(..., ...)
| L whatever L() constructed
L -> # E new Normalize(...)
| E whatever E() constructed
E -> P + E new Sum(..., ...)
| P - E new Difference(..., ...)
| P whatever P() constructed
P -> K * P new Product(..., ...)
| K / P new Quotient(..., ...)
| K whatever K() constructed
K -> - K new Negation(...)
| Q whatever Q() constructed
Q -> R Q new Product(..., ...)
| R whatever R() constructed
R -> V ^ J new Power(..., ...)
| V whatever V() constructed
V -> D new Value( new Quantity (...) )
| D ~ D new Value( new Quantity (...) )
| W new Value( new Quantity (...) )
| ( L ) whatever L() constructed
J -> I | - I
I -> (any nonnegative integer)
D -> (any nonnegative number, integer or floating-point)
W -> (any word that is a unit name)
Here are some more specific examples of possible inputs, and the corresponding Abstract Syntax Trees of objects that should be constructed.
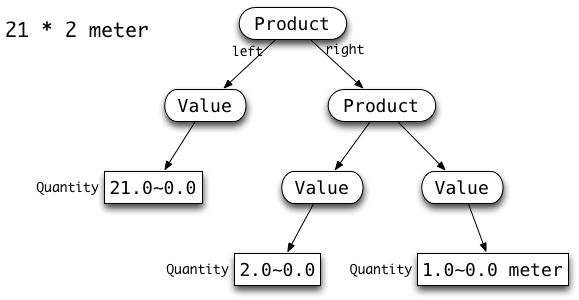 |
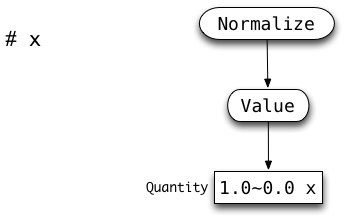 |
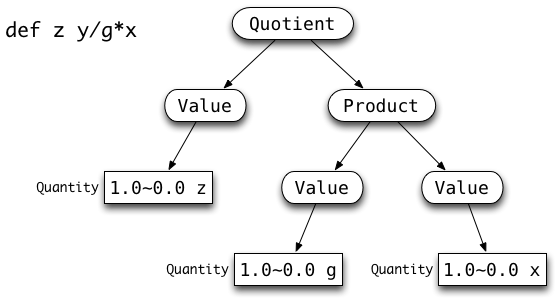 |
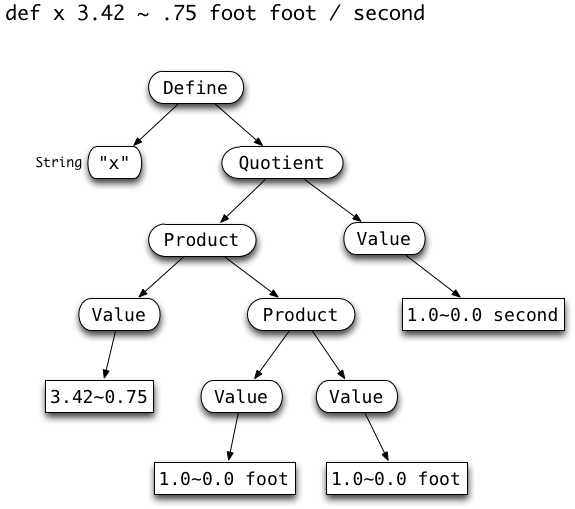 |
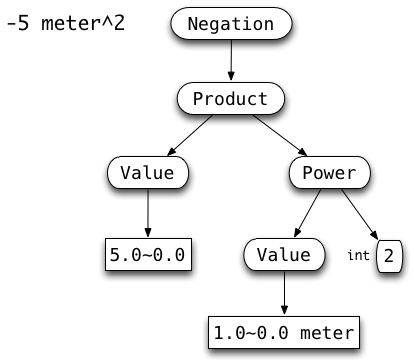 |
30 points
This part completes the Unicalc language. Fill in code for the eval method in the AST classes (in AST.java). The code should work as follows:
[Note: if we were coding Unicalc in Racket, eval would be a single loop taking an AST, testing what sort of node is at the root, and performing the appropriate action. While it is possible to write this kind of code in Java as well (e.g., using instanceof), in object-oriented languages it is generally preferable to invoke a method by name, and let the object itself figure out what to do.]
Error Handling For up to +4 points, modify main to use try and catch, so that when a ParseError exception is thrown by parse(), Unicalc prints a nice error message and restarts the loop (i.e., asks for another input), rather than killing the whole program.
Associativity. For up to +6 points, fix the associativity of the parser. As given, the grammar makes +, -, *, and / right-associative. For example, the abstract syntax tree above for y/g*x shows that the expression groups as y/(g*x). Although right-associativity makes recursive descent parsing easier, it is much more common for these operators to be left-associative (i.e., grouping that expression as (y/g)*x.
One way to handle this is to write E() and P() functions as if they were written (using a bit of regular-expression notation):
E -> P ( + P | - P )*
P -> K ( * K | / K )*
That is, an E is a P followed by zero or more “+ P”s
and/or “- P”s. One can implement this with
(instead of recursion) a while loop, grabbing as many “+ P”s
and/or “- P”s as possible, and building up the appropriate trees as you go.
Similarly, the code for P() would grab one K, and then loop gathering as many “* K”s and “/ K”s as possible.
Be sure to work on a copy of your files -- and then, if you submit this, please place those new files into a folder named extra and zip that folder. There is a spot in the submission site to upload extra.zip for this extra-credit challenge.
Personalizing. For up to +5 (or more) points, improve the unicalc-language with whatever feature you'd like... . Here are the rules, however:
Be sure to work on a copy of your files -- and then, if you submit this, please place those new files into a folder named extra and zip that folder. There is a spot in the submission site to upload extra.zip for this extra-credit challenge.
Please submit the following files: