Harvey Mudd College
Computer Science 60
Assignment 3, Due Tuesday, September 30, by 11:59pm
From Racket to Prolog...
Assuming you took CS5, at this point in CS60 you've worked with (at
least)
three programming languages: Python, HMMM, and Racket. This week -
and in the coming weeks - we will add Prolog to that list (if it's not
already there).
Submitting your code
Parts 1, 2, 3, and 4 this week may be done in pairs -- or individually, if
you prefer. Overall, you will submit 3 files for this week's problems:
- Part 1: hw3pr1.pl, your rules for implementing the Simpsons' family tree relationships in Prolog
- Part 2: Hw3pr2.java, solutions to the Java problems
- Part 3: hw3pr3.rkt, graphs in Racket
- Part 4: hw3pr4.rkt, a unit-conversion calculator implemented in Racket
If you'd like to browse the starter files, they're linked from here
in text format (you'd need to change the Prolog file names
so that their file extensions are .pl to use these):
Part 0: Getting started... [0 points]
First, you will want to be sure you can run prolog -- either from
your computer or on the CS lab machines.
Instructions from the CS lab machines -- or from a Mac once Prolog is installed:
- You'll want to log in and download the HW files. We'll suppose that you download them to the Desktop.
- Next, open a terminal window. You can use the Searchlight feature (upper right)
to look for terminal. You'll see a command-line interface open up.
- Next, change directory to the Desktop. This will use cd as
follows:
cd Desktop
- Next, you can open prolog with the command /usr/local/bin/swipl
- Then, you can load a file, e.g., the hw3pr1.pl file at the prolog
prompt with [hw3pr1]. - the period at the end is important!
- You may see warnings about "Singleton variables" - don't worry about these
for now.
- You can also load a file upon starting with
/usr/local/bin/swipl -f hw3pr1.pl
- You might try predicates such as
parent(X, bart).
- To edit the hw3pr1.pl file, you might use any text editor
at all. I use the Max OS built-in editor, named TextEdit, which
can be found in Applications.
-
You will notice that the hw3pr1.pl file, as written, will
cause Prolog to warn you about "singleton" variables.
These warnings will (or, at least should) disappear when
you write the predicates that
are described for this week's hw, below.
Instructions from your own machine:
- If you have a Mac, the best thing to do is to use Homebrew to install
Prolog. Here's what to do:
- Install Homebrew, (scroll down to the bottom of the page for
information on how to install it). Note that you'll have to use the terminal to
install Homebrew.
- Use Homebrew to install Prolog, by running the following command from the
terminal:
brew install swi-prolog
See the
instructions above describing how to use Prolog on the
CS lab machines, which are Macs. As above, you can use the Mac
built-in text editor, called TextEdit to edit your
prolog files.
- You can obtain a version of SWI-prolog from for
Windows (32 or 64 bit) and
Linux. On Windows, there is
a graphical user interface for
the Prolog "command line" and other windows for editing your Prolog
source files.
One important note before you get started...
Prolog is in some ways like Racket.
However, there are a couple of important differences to keep in mind:
Racket allows you to define functions and data in a file and/or at the
command line (the interpreter). However, prolog is different: you
must define everything in a file. The prolog command line can only be
used to make queries based on the facts and rules in the file.
Therefore, the following will NOT work:
?- [hw3pr1]. <-- Loads in the file hw3pr1.pl with Simpsons stuff
% simpsons compiled 0.42 sec, 4242 bytes
Yes
?- parent(bart, bartjr). % this will not work!
This is attempting to define a new fact inside Prolog's query environment
and prolog will, to use a technical term, "barf."
Part 1: The Simpsons' family tree... (35 points)
[40 points (5 points each), pair or individual]
This part asks you to write predicates that define family relationships
and answer questions about the Simpsons' family tree -- or, at least, the
version of the family tree that appears in hw3pr1.pl.
Formatting and commenting...
Please use the standard commenting
convention of your submission site id/login, file name, and date at the top of each file.
In addition, be sure to include a comment for each function
that you implement. Examples appear through the hw3pr1.pl starter file.
Finally, please be sure to name your files and functions
as noted by the problems.... The grading procedure for this assignment is
partially automated and files and functions whose spellings differ from
those below will help the graders a lot!
You should download that hw3pr1.txt
file -- you may need to change
its name to hw3pr1.pl from hw3pr1.txt, depending on
how you get the file. If it's already hw3pr1.pl, it's OK. (This
is because some browsers believe that files ending in .pl are Perl
scripts.)
In that file, there are rules for a (fictional) Simpsons' family
tree. These rules define, from scratch, the predicates
- person
- parent
- female
- male
- age
In addition, there are example prolog predicates that
define child, mother, and ancestor relationships,
based on the above primitive rules. For each of these provided functions, please
add at least one test case.
Finally, at the very top of the file, there are eight
placeholders where you should
replace the code after :-
with rules that define each of the predicates described
in detail below. The predicates to write are
- grandparent
- siblings
- cousins
- hasDaughterAndSon
- hasOlderSibling
- hasYS (younger sister)
- hasOlderCousin
- hasFirstGC
You may also add any additional
helper predicates that you wish,
including anything that we looked at in class. In fact,
some of the above are predicates we covered in class: this
is completely Ok: it's warm-up. However, please don't
change the facts about parenthood/relationships among the Simpsons!
We need those for testing.
For each predicate you write and the three provided functions, please add at least
one additional test case. These test cases should be clearly labeled, by writing them
in the blank provided. Again, we remind you that writing tests is a great way to start
thinking about the code you plan to write and should be done BEFORE writing code.
% The following tests can be run by typing:
% run_tests(child)
:- begin_tests(child).
test(childT1) :- child(bart, marge), !.
test(childT2) :- child(lisa, marge), !.
test(childT3) :- child(bart, homer), !.
test(childT4) :-
setof(OneKid, child(OneKid, marge), AllKids),
AllKids == [bart, lisa, maggie].
test(childT5) :-
setof(OnePar, child(marge, OnePar), AllParents),
AllParents == [jackie, john].
test(childT6) :- \+child(marge, homer).
test(childT7) :- \+child(jackie, _).
% add additional tests below:
%% here's where you'd add more tests
:- end_tests(child).
The Simpsons' Family-tree predicates to write:
- grandparent(X, Y) should be true if and
only if X is a grandparent of Y.
You can test this out with
grandparent( john, bart ). % yes!
grandparent( lisa, bart ). % no.
grandparent( X, bart ). % there will be four answers
setof( P, grandparent( P, bart ), Answer ).
Answer = [homericus, jackie, john, matilda]
- siblings(X, Y) should be true if and only if
X and Y are siblings
Note that for the sake of this problem (and perhaps in general),
a person cannot be their own sibling.
You can test this out with
siblings( bart, lisa ). % yes or true
siblings( bart, terpsichore ). % no or false
setof( S, siblings(S,lisa), Answer ). % lisa has 2 siblings
Answer = [bart,maggie]
- cousins(X, Y) should be true if and only if
X and Y are first
cousins. Note that for the sake of this problem (and perhaps in general),
a person cannot be their own cousin. Similarly, do not
consider brothers and sisters to be cousins for this problem.
You can test this out with
cousins( bart, lisa ). % no or false
cousins( bart, terpsichore ). % yes or true
setof( C, cousins(C,lisa), Answer ). % lisa has 2 cousins here
Answer = [millhouse, terpsichore]
- hasDaughterAndSon(P) should be true if and only if
P is a parent of a daughter and a parent of a son.
For example, you can test this out with
hasDaughterAndSon( homer ). % yes or true
hasDaughterAndSon( esmerelda ). # no or false
setof( P, hasDaughterAndSon(P), Answer ).
Answer = [cher,glum,homer,jackie,john,marge]
- hasOlderSibling(X) should be true if and only if X
has an older sibling (half-sibling is OK). (Consider "older" to mean strictly
greater-than in age.)
You should check this with some queries of your own devising;
in addition, you can check for all of the people with older siblings with
setof( X, hasOlderSibling(X), Answer ).
Answer = [atropos,glum,homer,homericus,lachesis,lisa,maggie,marge]
- hasYS(X) should be true if and only if X
has a younger sister. (Consider "younger" to mean
strictly less-than in
age.)
You should check this with some queries of your own devising;
in addition, you can check for all of the people with younger sisters with
setof( P, hasYS(P), Answer ). % everyone with a younger sister
Answer = [atropos, bart, klotho, lisa, patty, selma]
- hasOlderCousin(X,GP) should be true if and only if X
has an older cousin through the particular grandparent GP. That is,
X is a grandchild of GP and GP has another
grandchild who is strictly older than X.
You should check this with some queries of your own devising;
in addition, you can check for all of the people with older cousins
(and the grandparents through which this occurs) with
setof( [X,GP], hasOlderCousin(X,GP), Answer ).
Answer = [[gomer,helga],[gomer,olf],[homer,helga],[homer,olf],[maggie,jackie],[maggie,john],[millhouse,jackie],[millhouse,john],[terpsichore,jackie],[terpsichore,john]]
Note: using six clauses to define hasOlderCousin is completely OK -- and may,
in fact, be necessary.
- hasFirstGC(X) should be true if and only if X
has a parent GP and a child C, such that C is
GP's oldest (hence "first") grandchild.
The predicate hasFirstGC(X) should be
false if X has no parent or has no child (or does not have a child that
matches the criterion above).
Hint: The negation examples we looked at in class won't help
outright on this problem, but consider using hasOlderCousin
as a helper predicate.
Then the negation example we looked at in class will serve as a good template!
Remember that the "not" operator in prolog is \+, as in
the construction \+predicate(...).
You should check this with some of your own queries;
in addition, you can check for all of the people with first grandchildren via
setof( P, hasFirstGC(P), Answer ).
Answer = [esmerelda, homer, marge, matilda, skug]
Prolog reminders
Recall that "," is the symbol for AND, ";" is the SYMBOL for OR, and
"\+" is the symbol for NOT, while \== is the symbol for "not equal."
Please look at the class notes for other Prolog syntax. Another good resource is Learn Prolog Now!,
a site that explains the language concisely and with a number of examples.
Please submit your solutions in your hw3pr1.pl file under assignment #3.
Note on Prolog's output formatting
There are several settings that control how Prolog
formats its output: the following describes a few of those settings
you may want to change.
You may have noticed that when answer variables get bound to long lists,
swipl shows the list with '...' after about 10 elements,
which can be annoying.
To see the entire list, simply type
w
range(L,H,[]) :- L > H.
range(L,H,[L|R]) :- M is L+1, range(M,H,R).
?- range(1, 50, X).
X = [1, 2, 3, 4, 5, 6, 7, 8, 9|...]
X = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11,
12, 13, 14, 15, 16, 17, 18, 19, 20,
21, 22, 23, 24, 25, 26, 27, 28, 29,
30, 31, 32, 33, 34, 35, 36, 37, 38,
39, 40, 41, 42, 43, 44, 45, 46, 47,
48, 49, 50]
To change the limit on the number of elements once and for all, copy the
following at the top of your source file (we have done this
for the two source files this week).
:- set_prolog_flag(toplevel_print_options, [quoted(true),
portray(true), attributes(portray), max_depth(999), priority(699)]).
Part 2: Java! (7 points)
We have six additional Java problems this week. We also want you to
experiment with creating a particular type of error in Java. We've given
you a challenge to complete, which is described in the following function
in the file Hw3pr2.java
public static void main(String[] args)
Modify the main function as described in the file and fill in the
blanks in the six assigned problems. The following resources
might be helpful to you:
Part 3: Graphs and use-it-or-lose-it (15 points)
Problem 1: Define Graphs
You are required to use the following functions when working with weighted
edges and
graphs. For this problem, write some simple graphs to use for testing.
We have provided the definition for BigGraph below. You should create:
- A graph with no edges
- A graph with four edges that do not include a loop (e.g. a->b->c->d)
- A graph with four edges that do include a loop (e.g. a->b->c->d->a)
- A graph with four edges where not all nodes are connected (e.g. a->b->a, c->d->c)
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; Weighted Edge interface
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; make-edge: creates a weighted edge from a source and destination node and a weight
;; inputs: a source node and a desintation node
;; output: a weighted edge edge
(define (make-edge s d w)
(list s d w))
;; src: gets the source of an edge
;; inputs: a weighted edge
;; output: the source node of the edge
(define (src edge)
(first edge))
;; dest: gets the destination of an edge
;; inputs: a weighted edge
;; output: the destination node of the edge
(define (dst edge)
(second edge))
;; weight: gets the weight of an edge
;; inputs: a weighted edge
;; output: the edge's weight
(define (weight edge)
(third edge))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; Graph interface
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; make-empty-graph:
;; inputs: none
;; output: an empty graph
(define (make-empty-graph)
'())
;; add-edge: adds an edge to a graph (does not check for duplicates)
;; inputs: an edge and a graph
;; output: a new graph that includes the given edge
(define (add-edge e G)
(cons e G))
;; emptyGraph?:
;; inputs: a graph
;; output: #t if the graph is empty; #f otherwise
(define (emptyGraph? G)
(null? G))
;; edge-list: gets a list of edges in the graph
;; inputs: a graph
;; output: a list of edges in the graph
(define (edge-list G)
G)
;; remove-edge: removes an edge from a graph
;; inputs: an edge and a graph
;; output: a new graph that excludes the given edge
(define (remove-edge e G)
(remove e G))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; Graphs for testing
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; This graph makes it clearer how graphs are created:
(define TinyGraph
(add-edge (make-edge 'a 'b 1)
(add-edge (make-edge 'b 'a 1)
(make-empty-graph))))
; identical result to BigGraph
(define BigGraphVerbose
(add-edge (make-edge 'a 'b 1)
(add-edge (make-edge 'b 'c 1)
(add-edge (make-edge 'c 'd 1)
(add-edge (make-edge 'd 'e 1)
(add-edge (make-edge 'c 'f 1)
(add-edge (make-edge 'e 'g 1)
(add-edge (make-edge 'e 'h 1)
(add-edge (make-edge 'f 'x 1)
(add-edge (make-edge 'x 'y 1)
(add-edge (make-edge 'y 'z 1)
(add-edge (make-edge 'z 'b 1)
(make-empty-graph)))))))))))))
(define BigGraph
(foldr add-edge
(make-empty-graph)
(map make-edge
'(a b c d c e e f x y z)
'(b c d e f g h x y z b)
'(1 1 1 1 1 1 1 1 1 1 1))))
Problem 2: gchildren
In this problem, you'll use the function (edge-list <graph>)
to get a list of edges in the graph. (note: we know that the interface uses a
list of edges to represent a graph, but we don't violate the abstraction! We can
call (rest <list-of-edges>) but never (rest <graph>) Write a function
(define (gchildren N n G)
- N, a nonnegative integer
- n, a symbol representing a node in a graph
- G, a positively-weighted graph
As output, gchildren should return a list of all of the N-th
generation descendants of node n in graph G.
If N is 0, then (list n) should be returned,
regardless of G.
If node n does not have any descendants that are n-levels
deep in G, the empty list should be returned.
Here are a few examples using our example graph:
(check-expect (gchildren 0 'a BigGraph) '(a))
(check-expect (gchildren 1 'a BigGraph) '(b))
(check-expect (gchildren 2 'a BigGraph) '(c))
;; these tests use sortsym to avoid ambiguity in node order...
(define (sym<? s1 s2) (string<? (symbol->string s1) (symbol->string s2)))
(define (sortsym L) (sort L sym<?)) ;; will sort a list of symbols
(check-expect (sortsym (gchildren 1 'c BigGraph)) '(d f))
(check-expect (sortsym (gchildren 2 'c BigGraph)) '(e x))
(check-expect (sortsym (gchildren 3 'a BigGraph)) '(d f))
(check-expect (sortsym (gchildren 3 'c BigGraph)) '(g h y))
Remember to write additional test cases!!
Problem 3: min-dist
Write (min-dist a b G),
which takes in two nodes a and b
and a directed, positively-weighted graph G.
Your min-dist should
return the smallest distance that is required to travel from a
to b through graph G. Every
node should be considered 0 away from itself. However, if
there is no path from a to b in G,
for different nodes a and b, your function
should return the
value 42000000, which will be bigger than any feasible path
in our graphs. (The problem with using the value +inf.0 is
that it is floating-point, which changes check-expect's behavior.)
For example,
(define Graph2
(foldr add-edge
(make-empty-graph)
(map make-edge
'(e a e a a a b b d b c c)
'(b b a c d e c d e e d e)
'(100 25 42 7 13 15 10 5 2 100 1 7))))
(check-expect (min-dist 'a 'e Graph2) 10)
(check-expect (min-dist 'e 'b Graph2) 67)
(check-expect (min-dist 'd 'd Graph2) 0)
(check-expect (min-dist 'f 'a Graph2) 42000000)
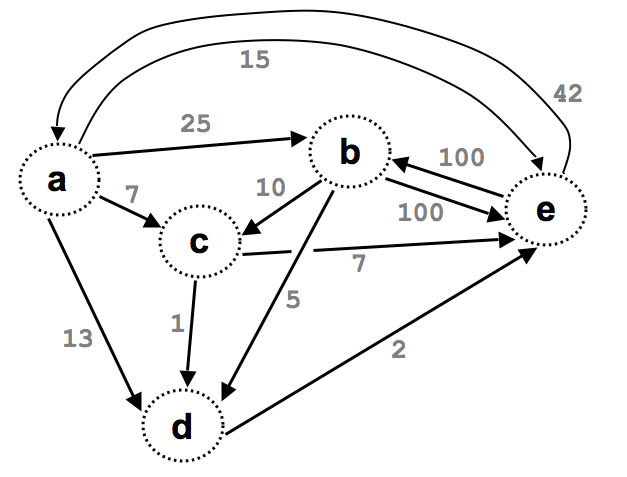
You should also start by writing tests using your graphs from question #1.
Hint: You might start with the reach code here
and consider how to
change the return values appropriately from booleans to numeric quantities... !
Part 4: Unicalc (43 points)
This semester you'll build
your own task-specific language that will be able to
handle arbitrary multiplication-based conversions from one unit
to another -- and account for error propagation, too.
To do this, your application will be able to
navigate within arbitrarily large graphs of unit-conversion data.
We're calling this application a unit-calculator, or unicalc.
You'll prototype your
application in Racket this week. When we begin to focus on Java you'll build the
fundamental data structure for a Java implementation of unicalc.
Pair or individual problem
You may work on this
one either individually or in a pair. If you work in a pair, be sure to follow
the CS 60 pair-programming guidelines.
43 Points
This problem asks you to write several Racket functions:
together, they will implement a "unit-calculator" or unicalc
application. A complete application will be able to convert any unit
quantity to any compatible quantity by using an association list
as a database of known conversions.
Quantity Lists
The fundamental structure used in unicalc is called a Quantity List.
As a data structure, a Quantity List is a 4-element Racket list in which
- the first element is a floating-point number, the quantity
- the second element is a sorted list of symbols, the numerator
- the third element is a sorted list of symbols, the denominator
- the fourth element is a floating-point number, the uncertainty,
which represents the one-standard-deviation error associated
with the overall quantity being represented
For instance, the following would represent the typical value for Earth's
acceleration due to gravity (with a small uncertainty of 0.01):
'(9.8 (meter) (second second) 0.01)
Generally speaking, a data structure is rather low-level:
it specifies the particular way that
language-specific and/or machine-specific constructs are used to organize
data, as the above example indicates. An information structure, on the
other hand, provides problem-specific capabilities that are independent
of a particular application. To reinforce this distinction, we provide a
make-QL function in Racket that creates a Quantity List. In addition,
we provide the accessor functions get-quant, get-num,
get-den, and get-unc, which return the individual pieces
of a Quantity List. In order to compare and sort lists of symbols, we provide
functions sym<? and sortsym.
In Racket, the difference between data structure and information structure
is almost entirely one's point of view. After all, the different ways of organizing
data are relatively limited!
The unit database
In the file hw3pr4.rkt is a
unit-conversion database in the form of an association list - here
are a few of its conversions:
(define unicalc-db
(list
(list 'A (make-QL 1.0 '(ampere) '() 0.0))
(list 'faraday (make-QL 96490.0 '(coulomb) '() 0.0))
(list 'farad (make-QL 1.0 '(coulomb) '(volt) 0.0))
(list 'fathom (make-QL 6.0 '(foot) '() 0.0))
(list 'hour (make-QL 60.0 '(minute) '() 0.0))
(list 'inch (make-QL 0.02539954113 '(meter) '() 0.0))
... ))
When a quantity is normalized,
it is converted entirely into basic units.
Also, the database does not contain
conversions from everything to everything: that would
make it very large and difficult to maintain! Instead,
the database can be used multiple times, e.g., to convert
furlongs to miles to feet to inches to meters.
Unicalc's functions to write
A note on uncertainty-propagation: there are many
online references that indicate how to propagate uncertainty
through various functions. We used
this reference from Harvard and this
error-propagation calculator as a check for our results.
Our uncertainties represent the size of one-standard-deviation within a
Gaussian distribution around the quantity in our quantity list - note
that we're not tracking relative uncertainties here, though
the formulas below do compute them, as needed.
-
Write a function
(define (merge L1 L2)
(check-expect (merge '(m m s) '(kg m s s)) '(kg m m m s s s))
-
More merging! Next, write a function
(define (n-merge L n)
(check-expect (n-merge '(kg m s) 0) '())
(check-expect (n-merge '(kg m s) 1) '(kg m s))
(check-expect (n-merge '(kg m s) 2) '(kg kg m m s s))
-
Write a function
(define (cancel L1 L2)
(check-expect (cancel '(m m s) '(kg m s s)) '(m))
(check-expect (cancel '(m s) '(kg m s s)) '())
(check-expect (cancel '(m s s s) '(kg m s s)) '(s))
(check-expect (cancel '(kg m s s) '(m m s)) '(kg s))
-
Write a function
(define (simplify QL)
(check-expect (equal-QLs? (make-QL 1.0 '(m) '(s) 0.0)
(simplify '(1.0 (m m s) (m s s) 0.0)))
#t)
(check-expect (equal-QLs? (make-QL 1.0 '(m) '(kg) 0.0)
(simplify '(1.0 (kg m m s) (kg kg m s) 0.0)))
#t)
-
Write a function
(define (multiply QL1 QL2)
q1*q2*( (u1/q1)**2 + (u2/q2)**2 )**0.5
We will avoid multiplying by zero! Here are some examples:
(check-expect (equal-QLs? (make-QL 1764.0 '(m) '(s) 59.39696962)
(multiply (make-QL 42.0 '(kg m m) '(s s) 1.0)
(make-QL 42.0 '(s) '(kg m) 1.0)))
#t)
(check-expect (equal-QLs? (make-QL 1.0 '(kg meter x) '(amp s w) 0.02061553)
(multiply (make-QL 2.0 '(meter) '(amp w) 0.01)
(make-QL 0.5 '(kg x) '(s) 0.01)))
#t)
-
Write a function
(define (power QL p)
How to do this? You will want to use the following
ideas:
- For the new quantity, take the appropriate power of the old quantity. (Use Racket's expt function.)
- For the new numerator and new denominator, you'll want a helper function that concatenates - and maintains the
sorted order - of the correct number of the original numerator and denominator. You'll
use recursion, in all likelihood! Note that negative
powers aren't a problem: they simply switch the roles of these two pieces of the quantity list!
- As for the uncertainty, it's not just an extension of the multiplication/division
uncertainty! This is because the factors in power are correlated; those in multiplication are
considered uncorrelated. Here is the formula for uncertainty propagation:
abs(p)*(q**(p-1))*u
Here are some examples of power in action:
(check-expect (equal-QLs? (make-QL 1.0 '() '() 0.0)
(power (make-QL 200.0 '(euro) '() 1.0) 0))
#t)
(check-expect (equal-QLs? (make-QL 0.005 '() '(euro) 2.5e-005)
(power (make-QL 200.0 '(euro) '() 1.0) -1))
#t)
(check-expect (equal-QLs? (make-QL 8000000.0 '(euro euro euro) '() 120000.0)
(power (make-QL 200.0 '(euro) '() 1.0) 3))
#t)
-
Write a function
(define (divide QL1 QL2)
(q1/q2)*( (u1/q1)**2 + (u2/q2)**2 )**0.5
We will avoid dividing by zero. Here are some examples:
(check-expect (equal-QLs? (make-QL 1.0 '(m) '(s) 0.03367175)
(divide (make-QL 42.0 '(kg m m) '(s s) 1.0)
(make-QL 42.0 '(kg m) '(s) 1.0)))
#t)
(check-expect (equal-QLs? (make-QL 4.0 '(meter s) '(amp kg w x) 0.08246211)
(divide (make-QL 2.0 '(meter) '(amp w) 0.01)
(make-QL 0.5 '(kg x) '(s) 0.01)))
#t)
-
Write a function
(define (norm-unit unit)
(check-expect (equal-QLs? (make-QL 1.0 '(kg meter meter)
'(ampere second second second second) 0.0)
(norm-unit 'weber))
#t)
(check-expect (equal-QLs? (make-QL 1.0 '(ampere) '() 0.0)
(norm-unit 'ampere))
#t)
-
Write a function
(define (norm-QL QL)
(check-expect (equal-QLs? (make-QL 42.0 '() '(ampere second) 1.0)
(norm-QL (make-QL 42.0 '(weber) '(ampere volt) 1.0)))
#t)
(check-expect (equal-QLs? (make-QL 4.3890407 '(meter) '() 0.09143834)
(norm-QL (make-QL 14.4 '(foot) '() 0.3)))
#t)
(check-expect (equal-QLs? (make-QL 0.010159816 '(meter) '(second) 0.0005079908)
(norm-QL (make-QL 2.0 '(foot) '(minute) 0.1)))
#t)
-
Write a function
(define (add QL1 QL2)
(list 'error 'add QL1 QL2)
new_uncertainty = ((u1**2) + (u2**2))**0.5
where u1 and u2 are the old uncertainties, respectively.
Here are a couple of examples:
(check-expect (equal-QLs? (make-QL 2.13356145 '(meter) '() 0.03592037)
(add (make-QL 42.0 '(inch) '() 1.0)
(make-QL 42.0 '(inch) '() 1.0)))
#t)
(check-expect (equal? (add (make-QL 42.0 '(inch) '() 1.0)
(make-QL 42.0 '(s) '() 1.0))
(list 'error 'add
(make-QL 42.0 '(inch) '() 1.0)
(make-QL 42.0 '(s) '() 1.0)))
#t)
-
Write a function
(define (subtract QL1 QL2)
(list 'error 'subtract QL1 QL2)
(check-expect (equal-QLs? (make-QL 0.0 '(meter) '() 0.03592037)
(subtract (make-QL 42.0 '(inch) '() 1.0)
(make-QL 42.0 '(inch) '() 1.0)))
#t)
(check-expect (equal? (subtract (make-QL 42.0 '(inch) '() 1.0)
(make-QL 42.0 '(s) '() 1.0))
(list 'error 'subtract
(make-QL 42.0 '(inch) '() 1.0)
(make-QL 42.0 '(s) '() 1.0)))
#t)
Where's convert?
With this toolkit of functions in place,
unit-conversion turns out to be an application of division:
(define (convert from to)
(norm-QL (divide from to)))
More tests... Here are
a few more tests you might try. These combine your unit-calculation
functions into composite operations:
(check-expect (equal-QLs? (make-QL 0.38735983 '(second) '() 0.030581039)
(divide (norm-QL (make-QL 3.8 '(m) '(s) 0.3))
(norm-QL (make-QL 9.81 '(m) '(s s) 0.0))))
#t)
(check-expect (equal-QLs? (norm-QL (make-QL 0.48 '(cm) '() 0.6327716))
(let* ((w (make-QL 4.52 '(cm) '() 0.02))
(x (make-QL 2.0 '(cm) '() 0.2))
(y (make-QL 3.0 '(cm) '() 0.6)))
(subtract (add (norm-QL x) (norm-QL y)) (norm-QL w))))
#t)
(check-expect (equal-QLs? (norm-QL (make-QL 18.04 '(cm cm) '() 3.7119827))
(let* ((w (make-QL 4.52 '(cm) '() 0.02))
(x (make-QL 2.0 '(cm) '() 0.2))
(y (make-QL 3.0 '(cm) '() 0.6)))
(norm-QL (add (multiply w x) (power y 2)))))
#t)
(check-expect (equal-QLs? (make-QL 5.1 '(meter) '() 0.360555127)
(subtract (norm-QL (make-QL 14.4 '(meter) '() 0.3))
(norm-QL (make-QL 9.3 '(meter) '() 0.2))))
#t)
(check-expect (equal-QLs? (make-QL 23.7 '(meter) '() 0.360555127)
(add (norm-QL (make-QL 14.4 '(meter) '() 0.3))
(norm-QL (make-QL 9.3 '(meter) '() 0.2))))
#t)
Congratulations! on creating an error-propagating unit calculator!
Later on, you will extend this prototype implementation into a full-fledged
language... in Java. For the moment, however, there's still a bit more Java
to get used to!
Submitting Be sure to submit hw3pr3.rkt
to the submission site.