Closure Properties of (the set of) Regular Languages
By definition, the union of two regular languages is regular, the concatenation of two regular languages is regular, and the star of a regular language is regular. In this section we look at other operations on regular languages that are guaranteed to produce regular languages. Specifically:
- The complement of a regular language is regular.
- The intersection of two regular languages is regular.
Theorems of this kind are called closure properties, because they tell us that the collection of all regular languages is closed under particular operations. (A set is closed under an operation if applying that operation to members of the set is guaranteed to produce members of that same set.)
Closure under Complement
Theorem
The complement of a regular language is regular.
Proof:
Let be an arbitrary regular language. There exists a DFA such that
. Define to be a DFA just like but with accept/reject
swapped (i.e., the set of final/accepting states is replaced by
). Then accepts a string iff rejects that
string. That is, , so the complement of
is regular too.
Example
The complement of the set is regular, because we can find a DFA for this set:
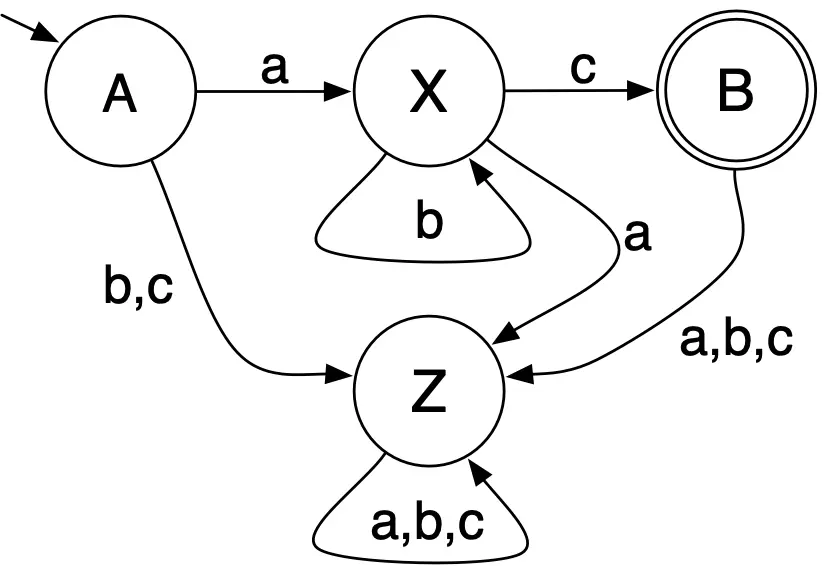
and use that to construct the DFA for the complement:
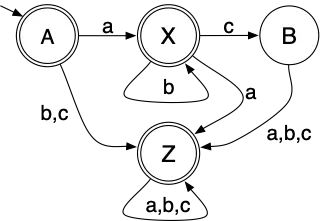
Closure Under Intersection
Theorem
The intersection of two regular languages is regular.
Proof 1:
Let and be arbitrary regular languages. Since
(a form of DeMorgan’s Law), it
follows that . We know and
are regular. So is regular Thus
is regular.
Theorem
The intersection of two regular languages is regular.
Proof 2:
Given DFAs
and accepting the two regular languages, we can construct a new DFA ,
called the Product Automaton of and that
accepts inputs and keeps track of what states and would be
in when given those inputs (i.e., we are simulating the two machines
being run in parallel), and only accept if both machines would accept
the input string.
Formally, we can define the components of the product automaton as follows:
The states of are pairs telling us where and would be on the input so far.
When we start, both machines are in their start states
If the first machine is in state and the second machine is in state and we see input , we use the transition functions of the machines to figure out which states the two machines will be in afterwards.
We have found a string in the intersection iff both machines have reached an accepting state.
Example
Here are two small DFAs and their product automaton:
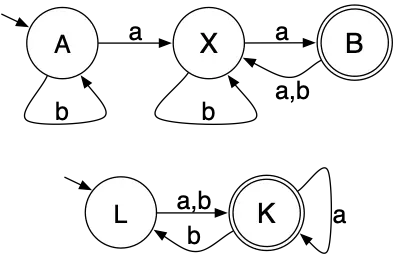
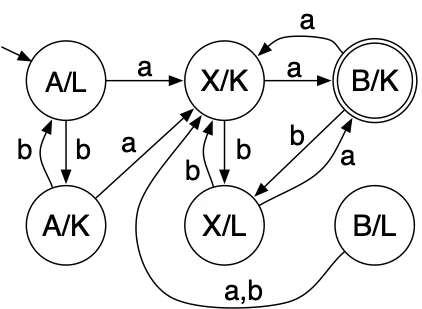
Initially the first DFA is in state A and the second DFA is in state L.
If the first input is a, then the first DFA switches to state X and
the second machine switches to state K. Conversely, if the first input
is b, then the first DFA stays in state A, but the second DFA switches
to state K. And so on…