The CYK Algorithm
We conclude the discussion of context-free languages by answering the question, “How can we tell whether a string is in the language of a context-free grammar?”
Parsing is the process of taking a linear sequence of characters and converting this into structured data, such as a parse tree (or, more commonly in practice, into a simplified version of the parse tree called an Abstract Syntax Tree).
There are a number of clever parsing algorithms commonly used in practice, including Recursive Descent and Shift-Reduce Parsing. Both of these algorithms are very efficient; parsing a string of length can be done in time.
Unfortunately, these algorithms only work for some CFGs, not all. Recursive Descent is designed to work if the CFG is “LL()” (for some ), while Shift-Reduce Parsing works if the CFG is “LR()” or “LALR()” (for some ).
In many computer applications, this isn’t a problem, because we can often modify the grammar or even the entire language to make these algorithms work! The original designers of Java, for example, chose a syntax for the language—keywords, operators, punctuation, etc.—specifically designed to be LALR(1).
However, we don’t always have the option of changing the language. A linguist trying to model a portion of English using CFGs, for example, doesn’t have the option of changing the syntax of English to make it easier to parse! And since this is a course on Theory of Computability, we still might like to know whether it’s possible to parse strings using arbitrary context-free grammars.
The answer is yes!
The CYK Algorithm
There are several parsing algorithms that work for all CFGs, such as Earley’s Algorithm, though none are terribly efficient (often for an input of length ). Here we will briefly describe the CYK Algorithm, probably the simplest algorithm for general-purpose CFG parsing.
(The CYK algorithm was independently invented by many researchers; the name comes from the initials of Cocke, Younger, and Kasami, three of people who rediscovered and published this algorithm.)
Chomsky Normal Form
Definition
A grammar is said to be in Chomsky Normal Form if all rules are either of the form (i.e., the nonterminal can be replaced by a single terminal) or of the form (i.e., the nonterminal can be replaced by two nonterminals).
Example
The grammar
is not in Chomsky Normal Form, because the first and third rules don’t have the right shape.
However, the grammar
is in Chomsky Normal Form (and has the same language, namely non-empty well-balanced strings of parentheses).
The CYK algorithm only works (efficiently) for grammars in Chomsky Normal Form. This is less a problem than it might seem at first, because there’s an algorithm to convert any CFG into Chomsky Normal Form grammar with the same language. In fact, if the grammar doesn’t explicitly mention , then the conversion is relatively easy to do by hand:
Example
Given the grammar
- First, we can replace the rule with the rules
- Second, we can break up the rule
into two binary rules
and then replace the parentheses with references to and to getPutting this all together, we get the equivalent grammar
The Idea
Suppose our input is a string
(where ). The idea is to answer the question, “For every substring of the input , what nonterminals can produce that substring?”
We denote by the set of nonterminals that can produce the substring .
More formally, for every such that ,
We are primarily interested in calculating the set , because the start symbol is in this set iff , that is, iff our given string is in the language of the grammar.
The Algorithm
We can calculate recursively as follows:
That is,
- Since our grammar is in Chomsky normal form, the only nonterminals that can produce a single character substring are those with a rule that directly replaces that nonterminal with character .
- For a nonterminal to produce a longer string , there has to be a rule such that produces the first part of this string and produces the rest.
In practice, we don’t want to directly implement this recursive definition, because we end up with a lot of redundant work. (The same function calls happen over and over again. This is the same problem with the simple recursive definition of the Fibonacci function.) The easiest solution is to use Dynamic Programming.
In the Dynamic Programming implementation of CYK, we create a
two-dimensional array N of size by , with the idea that
N[i,k] will hold the value of
. Then we can define
If we fill the entries of the array in the right order (starting at the diagonal), then we can ensure that when computing the value of a new array cell, we only look at other entries in the array that have already been computed. The last cell filled is N[1,]; if it contains our start symbol then we have verified that the entire strings is in the language of the grammar.
Example
Suppose we want to parse
using the grammar
We can create an array N of size 6 by 6, and start by filling in the diagonal entries (i.e., the sets of nonterminals that can directly produce each character in our string):

Then we can work on the next diagonal. There is no rule so is empty. There is a rule so is nonempty (i.e, can produce the substring consisting of the second and third characters of the input). Continuing on, we get:

We can then fill in the next diagonal:

Above, because and and , i.e., we have discovered that and can produce the end of our input because can produce the first two of these characters and can produce the last character.
Finally, we fill in the remaining diagonals to generate
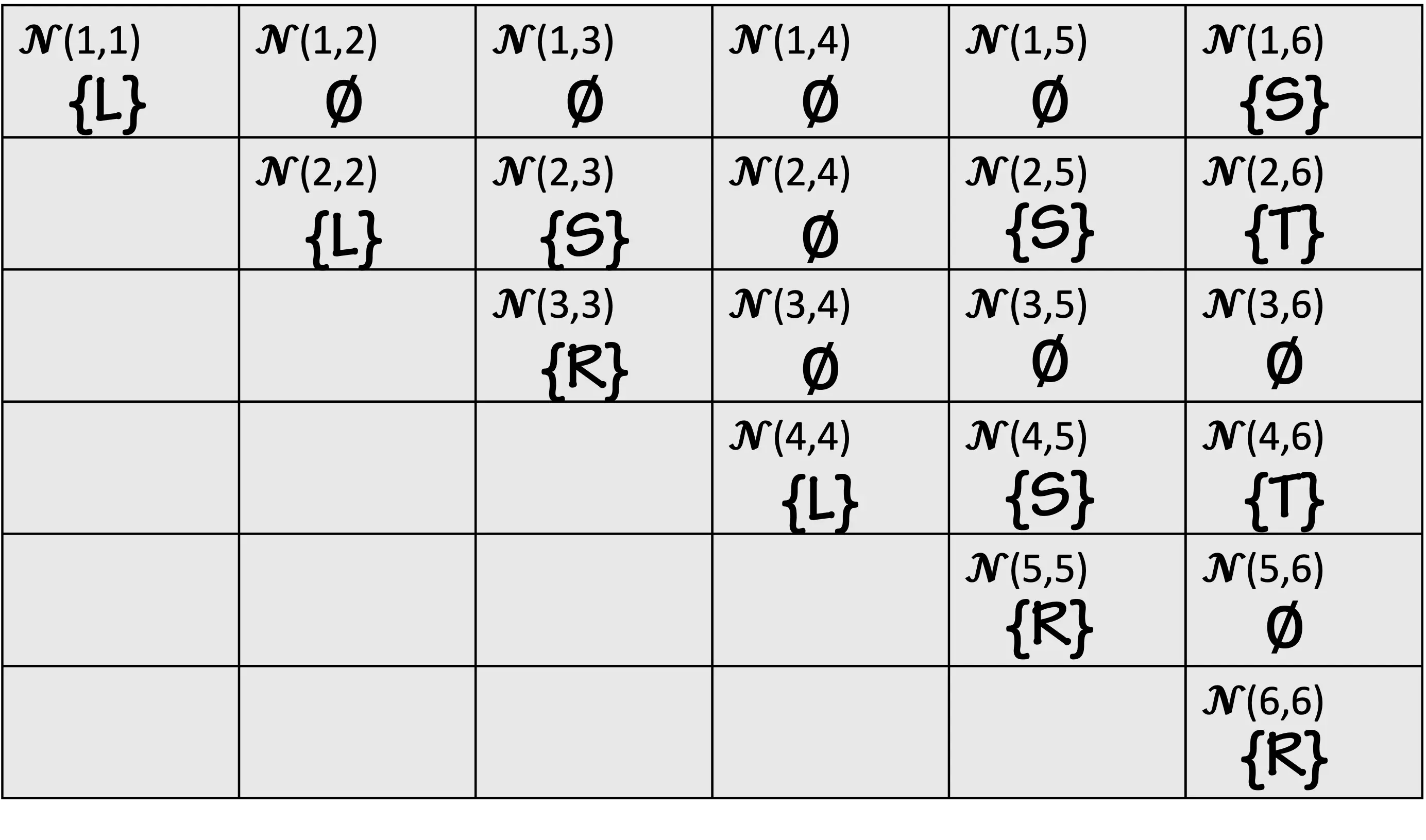
Since , we have verified that the start symbol can produce the whole string, and the string
is in the language of the given grammar.
For a string of length we have to calculate values for array elements, each containing a set of nonterminals. Each calculation takes on average, so the CYK Algorithm runs in total time .