Parsing and Parse Trees
Parsing is the process of taking linear data (files) and producing a (more useful) structured representation.
For example, compilers like javac or clang++ start by parsing the
program text to be compiled, and interpreters like python or
DrRacket start by parsing the program to run.
And most large systems read configuration files, data files, etc. Almost always these files are read and translated into trees, maps, or arrays, because these representations are more useful and more efficient than directly working with the linear sequence of characters comprising the file on disk.
Example
If you are given a string containing an arithmetic expression like
"(4 + 2) * 7", it’s not a straightforward task to write code to
calculate the result.
we’d have to find the numbers and do appropriate arithmetic in the
correct order. Worse, although the normal order of operations tells us
to look for multiplications first and do them before additions, in this
case the addition has to happen first, because the plus sign is inside a
pair of parentheses. But not all plus signs in parentheses go first, because
"(4 + 2 * 7)" is supposed to start with a multiplication.
However, if we look at a parse tree for this expression under the grammar
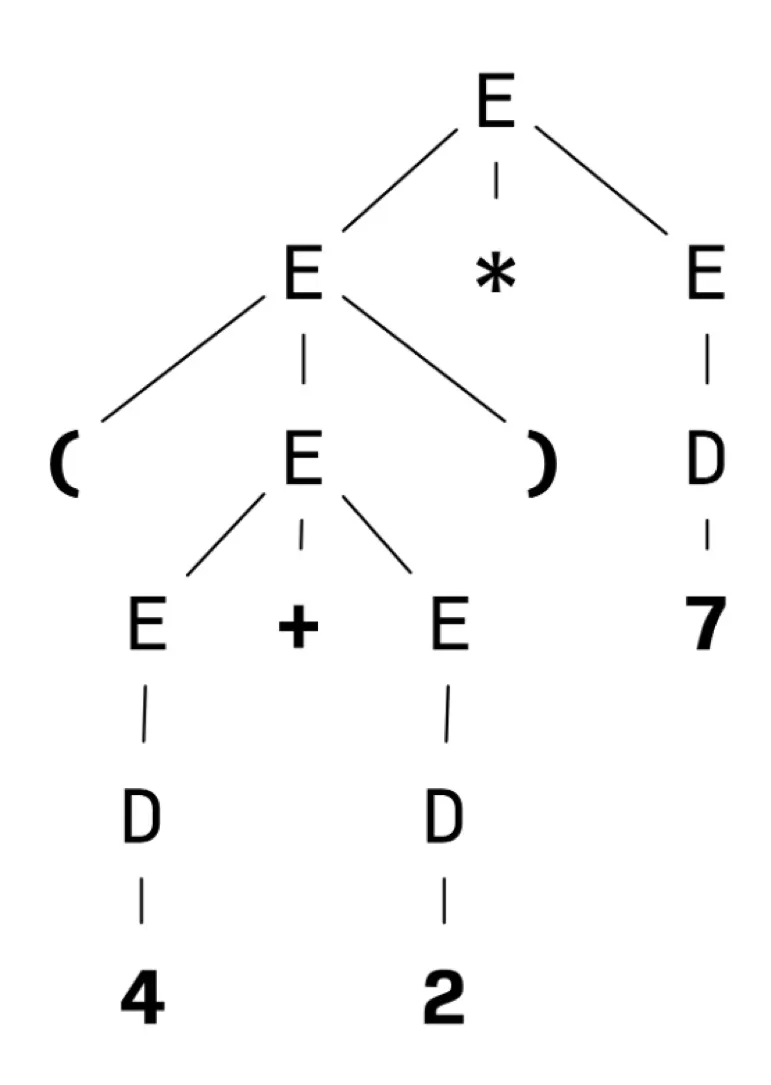
it’s relatively easy to imagine how to do the calculation given such a tree. We just implement a recursive function that looks at the root of the parse tree to see what kind of operation to perform (it’s a multiplication), recursively evaluates the left and right subexpressions/subtrees to get their values (6 and 7, respectively), and perform the operation (producing 42).
Example
The C expression
x > 0 ? y > 0 ? x + y : x - y : y > 0 ? -x + y : -x - yis very hard to interpret for humans, and it is not that much easier for
the computer to interpret it as a linear sequence of bytes/characters.
But if we look at a hypothetical parse tree for this expression,
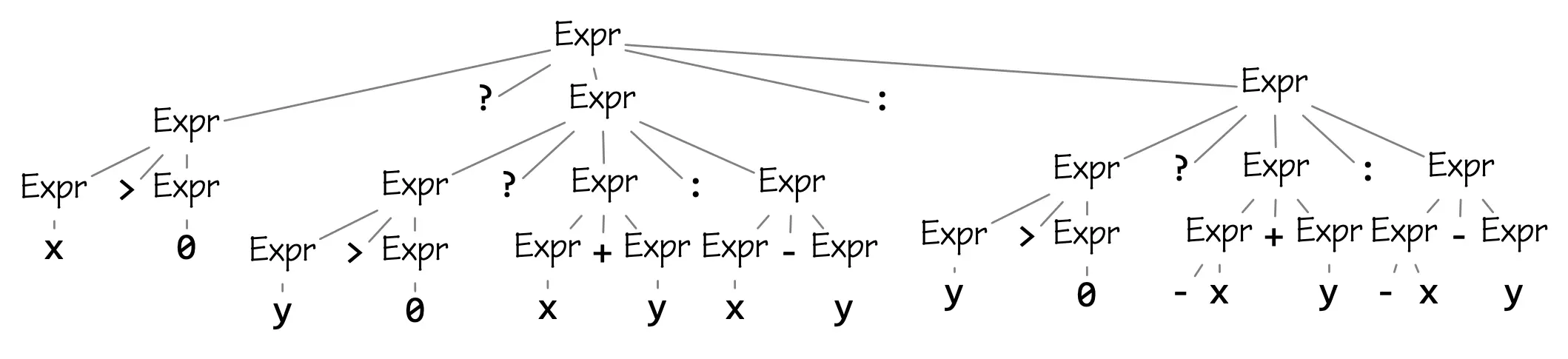 the structure is
much clearer; this is a “ternary expression” (…
the structure is
much clearer; this is a “ternary expression” (… ? … : …) that
tests whether x>0 and the returns one of two other ternary
expressions; each of the latter ternary expressions test whether y>0
and either do an addition or a subtraction.
Ambiguous grammars
We argued above that the meaning of a string can be clarified by looking at the parse tree. But if one string has two or more possible parse trees, we may have trouble deciding the intended meaning.
Definition
A grammar is ambiguous if some string in the language of the grammar has two possible parse trees.
Example
If we wanted to focus on expressions involving only subtractions of digits, we could use the following simplified grammar:
The language of this grammar includes 3 and
6-2 and 3-2-1 and 8-5-6-7 and any other sequence of digits
separated by subtaction sign.
Then the string 3-2-1 has two parse trees:
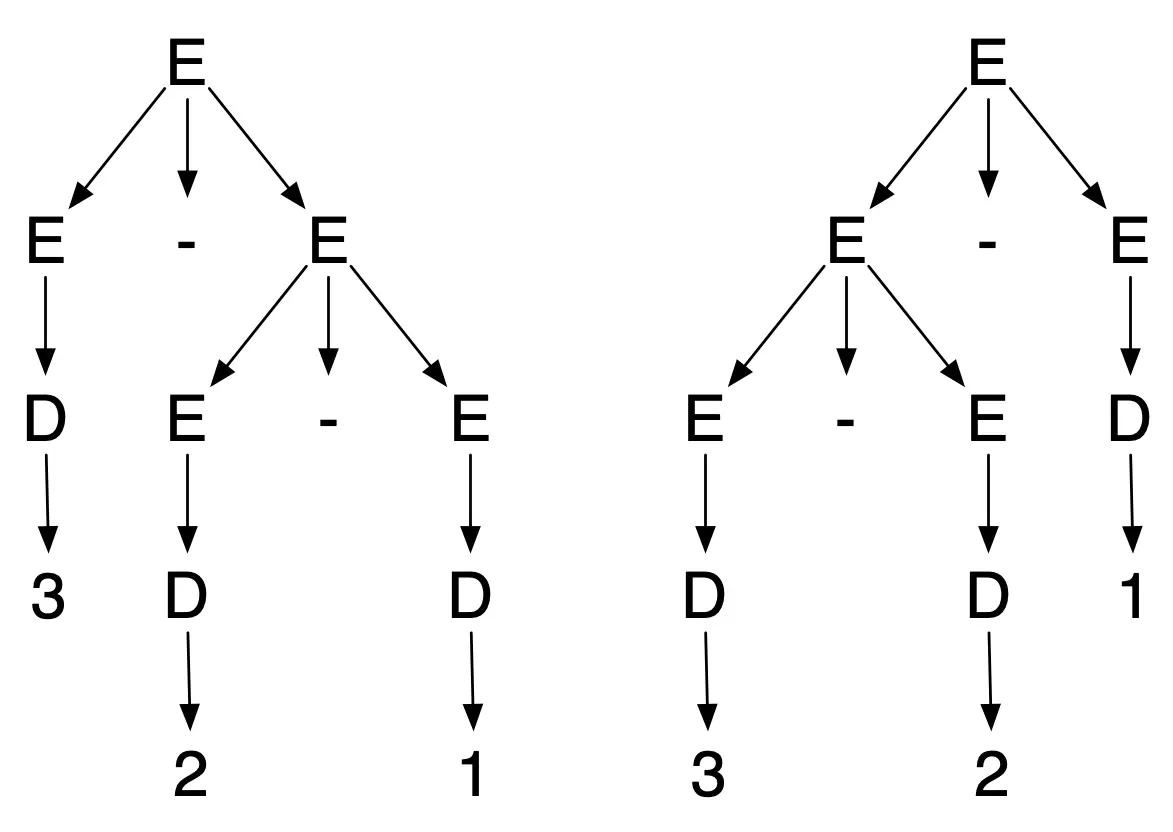
The first parse tree interprets the string as the difference of 3 and (2-1), while the second parse tree interprets the string as the difference of (3-2) and 1. This ambiguity is a problem if we’re evaluating expressions starting with the parse tree, because the first interpretation yields an answer of 2, while the second interpretation has the answer 0.
Encoding Associativity
By careful design of our grammar, we can ensure that our parse trees treat binary operations as left-associative (grouping to the left) or right-associative (grouping to the right) as desired.
Example
Consider this grammar:
Instead of saying that a subtraction can involve two arbitrary expressions, we now say that all subtractions involve an potentially complicated expression and a single digit.
The language is the same as the language of the ambiguous grammar in the previous example; it still generates all strings of one or more digits separated by subtraction signs.
However, now the language is not ambiguous. For example,
3-2-1 has only one possible parse tree:
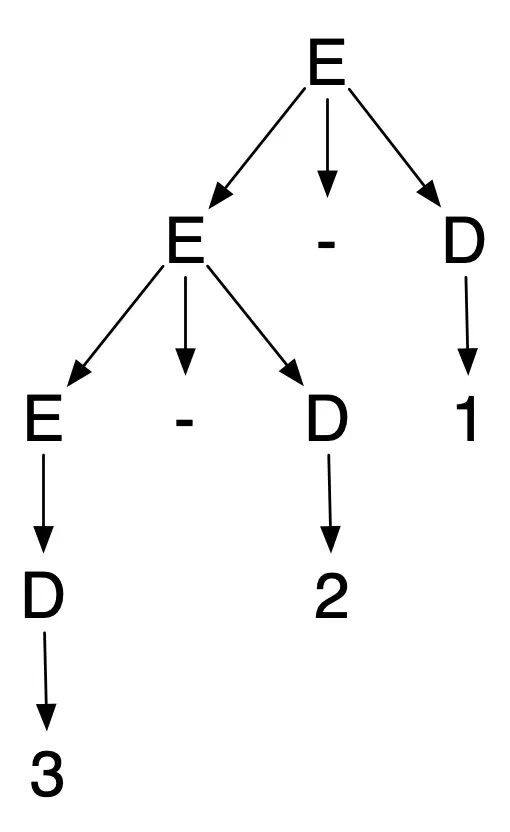
By changing the rule for subtractions from to , we have forced the parse trees to treat subtractions in a “left associative” manner
For example, 3-2-1 and 8-5-3-7 groups subtractions to the left
(corresponding to calculations producting 0 and -7 respectively).
Example
Interpreting subtraction as being left-associative (grouping a series of subtractions to the left) is the usual mathematical practice. But if we wanted subtraction to be right-associative (as it was in the programming language APL), we could say a subtraction involves a digit on the left and an arbitrarily complicated expression on the right:
This is another umambiguous grammar. It still
generates the same strings, but now the unique parse tree for 3-2-1 is:
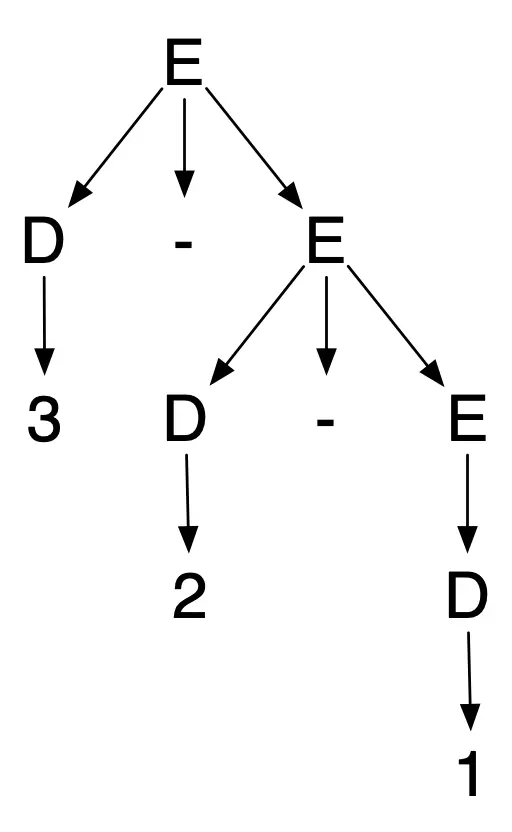
By changing the rule for subtractions to , we have forced the parse trees that treat subtractions in a “right associative” manner
For example, 3-2-1 and 8-5-3-7 groups subtractions to the right
(corresponding to calculations producting 2 and -1 respectively).
Encoding Precedence
In addition to ensuring that the only possible parse trees for an expression have the right associativity, we can also ensure that parse trees respect the relative precedence of different binary operators.
Example
We can apply the lessons of the previous section to get an unambiguous (left-associative) grammar for all arithmetic expressions involving digits:
However, just because the grammar is unambiguous doesn’t mean it gives
us the parse trees we want. For example, 6*7-4*9 has the unique
parse tree
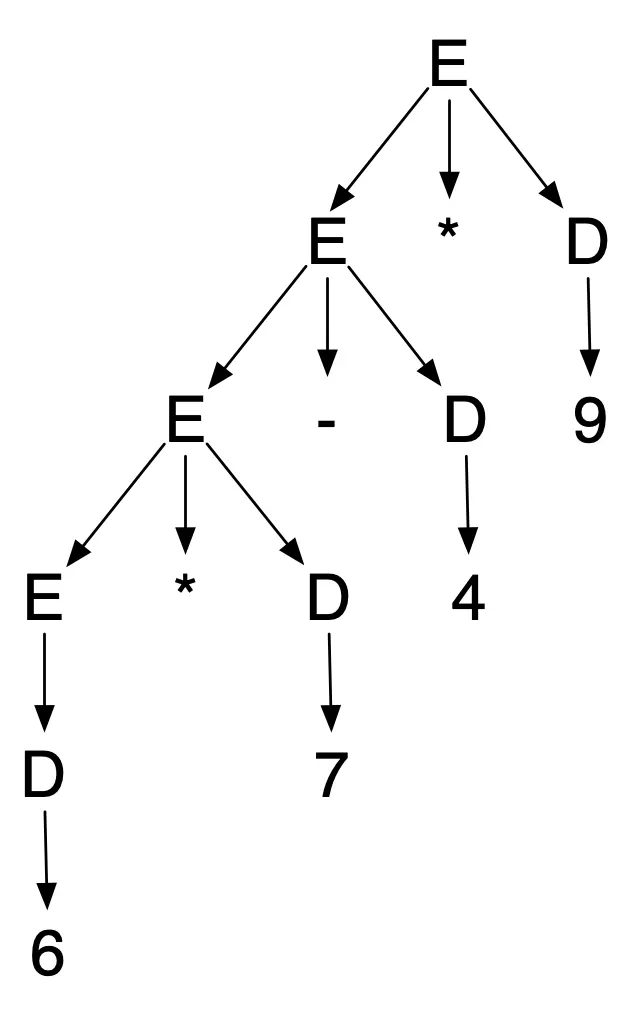
which corresponds to the left-associative calcuation (((6*7)-4)*9) = 342. But in mathematics and most programming languages, multiplication and division have higher precedence than addition and subtraction; to get the “expected” interpretation, we need subtraction to be at the root of the parse tree, and have two subtrees doing multiplications, which would evaluate to 42-36 = 6.
Example
We can encode precedence by splitting up the expressions into different “levels,” according to precedence.
The expressions produced by , , and here are often referred to as expressions, terms, and factors.
In this grammar, factors (strings produced by in the grammar) are the simplest expressions, digits or explicitly parenthesized expressions. For these atomic expressions, it’s obvious where they start and end.
The next level up is terms (strings produced by in the grammar). A
term is a (left-associative) sequence of products and quotients of
(atomic) factors, e.g., 3 or 3*8 or 3*8/6 or 3*8/6/2.
Finally, expressions (strings produced by ) are defined to be sums and differences of terms, i.e., sums and differences of products and quotients of atomic expressions.
As a consequence, the only possible interpretation of 6*7-4*9
is as an expression that is the difference of two product terms,
yielding the parse tree
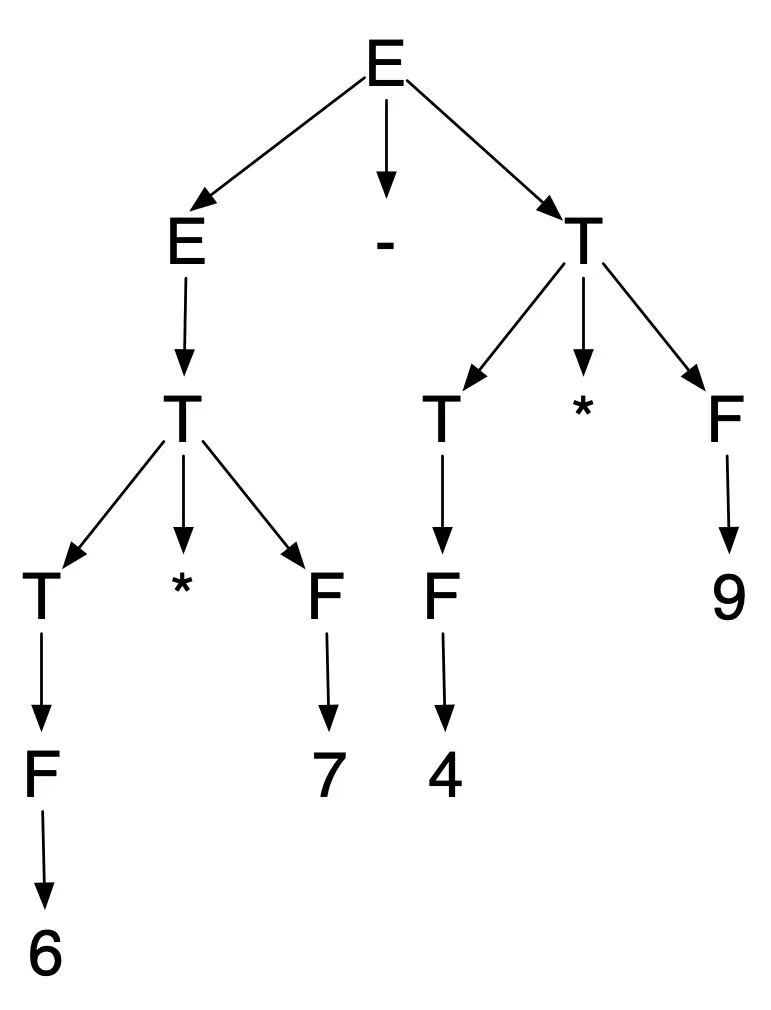
which has the general shape (and grouping of digits) corresponding to the intended interpretation
The general rule is that if you break expressions up into levels, the closer you are to the base atomic level (factors in the above grammar) the higher the precedence of the operator. Two operators at the same level (e.g., multiplication and division above) have equal precedence.
Real programming languages like C, C++, and Java have many more binary
operators than here (+=, <<, &&, etc.) and if you look at
the official grammar for expressions in those languages, you will find
expressions have been broken up into well over a dozen levels, encoding
the relative precedence and associativity of all these operators.