by Blake Larkin
In 2013, DeepMind put out a paper describing their success in producing a program that could learn to play several Atari 2600 games through deep reinforcement learning. The primary goal of their project was to create a network that could take a direct pixel-level input of the screen and produce a logical action response that would continue gameplay at human levels of control. Before this research, the best successful example in the same vein was TD-gammon, a network that could play backgammon, but not much else. Other success in gameplay did exist, but it was heavily based on handmade and pre-learned features. DeepMind felt that if they could successfully get a network to learn from direct input, perhaps it would be able to form deeper connections than the premade features. Through their research, they managed to create a network that could play numerous Atari 2600 games with human proficiency by utilizing deep Q-learning.

Originally, I hoped to examine DeepMind’s deep Q-learning network (DQN) to see how it reacted to specific situations. Specifically, I hoped to test out how the network performed against the game Stampede. In Stampede the player controls a rancher on horseback that needs to lasso cows before they make it across the screen. The game provides an interesting point of strategy as at first it is possible to catch every cow, but as the game progresses and difficulty increases, it becomes necessary to run into the cows to force them to go back to the far side of the screen. This provides no points, but it is vital if you want to catch all the cows to avoid losing the game. I was curious how the network would handle the possibility of needing two strategies for different segments of the game like humans typically use. My project plan involved running the base network on the game and comparing it to a modified version that builds two networks for each section of gameplay. I was interested to see if the network was stumped by the strategy change at all. Sadly, this did not go as well as I planned.
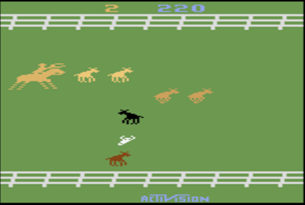
DeepMind’s DQN can interact and play Atari 2600 games through the use of a system known as the Arcade Learning Environment (ALE). The ALE is a very powerful tool in game learning, as it allows easy and direct access and emulation of games. By default, the ALE supports about 49 Atari 2600 games, but it does technically have an API that can add support for any game with only a small amount of information. This is how I initially planned to get the network to play Stampede. Sadly, the information you need to get does not come easy. The ALE requires very specific information about where in the Atari 2600’s memory the game stores information about things like score and lives, and this information can only be gotten through proprietary Atari debuggers, which I do not have access to. This made it effectively impossible for me to add any new games to the ALE selection, and limited my choice of games to the 49 pre-supported.
Since games like Stampede were out of the question, I had to modify my overall project goal. Instead of examining the DQN in a very specific situation, I instead opted to look at the DQN at large and see what changes I could make. I hoped to find ways to improve the rate at which the network learned through any changes I could make. To do this I planned to get DeepMind’s original DQN running and then modify it so that I could compare my changes and see how they impacted learning. Due to time limitations and issues with running the initial network, I did not have time to adequately get data from the original DQN, nor did I have the time to test any of the changes to the network I made, but I hope to continue this as time permits.
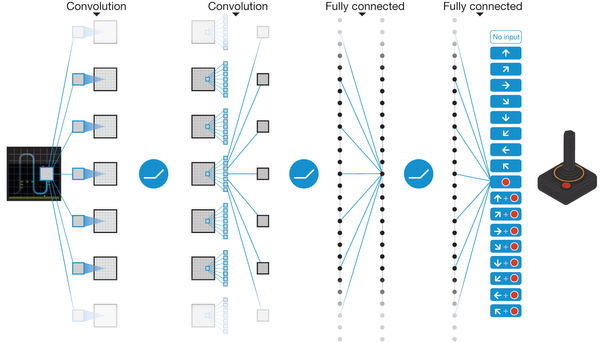
The DQN takes in a modified version of the game screen as input. The modifications here simply cut out a square from the middle of the screen for uniformity and converts pixel values to grayscale. It also stacks 4 frames together as one input, as this effectively quadruples the learning rate. This works because there is little need to make decisions frame by frame in most scenarios. The input then is fed into a convolutional layer that convolves the picture 32 times with an 8x8 kernel with a stride of 4. This convolutional layer is connected to another layer that convolves the picture 64 times, again with an 8x8 kernel. After this, the results are fed into three fully connected layers before leading to outputs corresponding to legal game commands. Each layer is connected through a linear rectifier.
The network learns through Q-learning, utilizing an experience replay system. This system records a before and after picture of the environment, what the network decided to do, and any reward received. The network then learns by grabbing a random handful of these past memories and updating them based on rewards seen at each step. Effectively this lets the network explore different possible states that come from multiple different moves and assign potential reward gains to each one. Then when the network needs to play it produces a Markovian chain of these states in hopes of achieving the highest possible score.

Currently, the network sees every fourth frame, chooses an action, and repeats it for the next three frames. This removes the chance of performing actions that only require one frame of input and lead to possible overcorrecting.
Fix: I added three extra output neurons that simply correspond to if the network should repeat the action for every additional frame. This does not hurt the speed increase of only choosing an action every four frames, while directly helping the issue of always repeating actions.
The network also normalizes all reward, no matter how large, to 1. This means that an action that gets 1 point or 1000 points both look equally appealing to the network. This was done in order to let the network play games of any point range, but it hurts the strategy of some games with multiple point values.
Fix: Since I only trained the network on one game, I added a max reward field that stores the largest reward the network has seen thus far in a game, and then all rewards are used as proportions of that score. This means that if you score 1000 points as your highest reward, another 1000 will register as a 1, and 500 will register as 0.5. This allows for prioritizing larger point values, while also giving fair space for getting lots of small points, and keeps the scores comparable between games.
In the code I used as a foundation, the author had effectively hard coded the concept that losing a life is equivalent to a game over to the learning algorithm.
Fix: I disagree with this change as it is effectively providing handmade features to the network, which is against the entire point of this project. It also doesn’t make sense for the network to have to consider every death the new start of a game. Instead, it could make more sense for the network to always experience the beginning of the game with full lives, the midpoint with 2 lives, and the end with no lives, and learn accordingly. As such I removed this addition.
The starter code also tried to prioritize certain memories in the experience replay system, but their math seemed to prioritize pretty much every memory in the end, which defeats the purpose of priority in the first place.
Fix: I modified their equation for how priority spreads through the memories to be less far-reaching, and also added in a multiplier for memories that generate reward so they are only as prioritized as the size of the reward using the proportionate reward system described above. This means that the network will be more likely to learn multiple times from actions that generate a lot of points, while also not giving everything the same priority.
Due to issues with Amazon EC2 and XSEDE, in the end, I had to run DeepMind’s code on my own CPU. This meant that the epochs they were able to complete in 30 minutes took me 9+ hours. Due to this, I was not able to train nearly as many games as I would have liked or any games for as long as they did. This didn’t stop me though, and I was able to run the network for about 7 epochs (~60+ hours) on two games, Assault and Demon Attack. These are both classic shooters akin to Space Invaders or Galaxian. Demon Attack is overall a simpler game, though the enemies move in much more complicated ways and fire much more frequently, but Assault adds extra constraints like overheating that the network must manage to avoid death. In the end, it learned to play both games at human levels surprisingly quickly. I think the coolest part of this learning process was how easy it was to see what was stumping the network, and it was easy to predict how it might overcome the obstacle in question. For instance, in Assault, the network was overheating because it shot to the side for no reason, and it was easy to see that the next thing the network should learn was to stop shooting to the side as often. The chart below shows my final results. The human player info was gathered from DeepMind’s original paper and was the highest score a game tester could achieve after 30 minutes of game time. The “Learned” Threshold corresponds to 75% of the human value.
|
Game |
Human Player |
“Learned” Threshold |
Num epochs by DeepMind |
Final DeepMind Score |
Num epochs by me |
Final Observed Score |
|
Demon Attack |
3401 |
2551 |
250 |
9711 |
6 |
7423 |
|
Assault |
1496 |
1122 |
250 |
3359 |
7 |
1273 |
In the future, I hope to actually compare the changes I made to the network to see how they impact the DQN’s ability to learn.
http://www.nature.com/nature/journal/v518/n7540/full/nature14236.html
https://docs.google.com/presentation/d/14d-bVxYdFpm-heXK2T-7dFka0c5e6eFU6JSLqve1PfI/edit#slide=id.g22060f5850_0_123
https://github.com/kuz/DeepMind-Atari-Deep-Q-Learner
https://github.com/gtoubassi/dqn-atari