The Neural Network
This is the main part of the project. Given four coarse coded images,
this produces a numerical score of the likelihood of a face appearing in
the image the coarse coded set was derived from.
There are two separate networks that achieve this task: one for each
of the training patterns. Two facial images are used as patterns for training:
 and
and 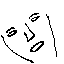 .
The network never actually sees these images; it uses their coarse coded
representations. Each network is trained to return 1.0 if it sees the pattern
or -1.0 if it sees a solid black field. Of course the network will never
return those end values, but rather something in between. Each network
is a single tanh activated neuron with only third order weights. This third
order structure of the neurons ensures invariance to geometric transformations.
This is why it doesn't matter that one of the training patterns is tilted:
that information is ignored. When the neurons are trained (using a standard
delta rule) the neurons are ready to be used to face-detect images. The
images are ran through each neuron and the outputs of each neuron are added
together to yield the final score. Since each neuron returns values in
the range of -1.0 to 1.0, the total value ranges from -2.0 to 2.0.
.
The network never actually sees these images; it uses their coarse coded
representations. Each network is trained to return 1.0 if it sees the pattern
or -1.0 if it sees a solid black field. Of course the network will never
return those end values, but rather something in between. Each network
is a single tanh activated neuron with only third order weights. This third
order structure of the neurons ensures invariance to geometric transformations.
This is why it doesn't matter that one of the training patterns is tilted:
that information is ignored. When the neurons are trained (using a standard
delta rule) the neurons are ready to be used to face-detect images. The
images are ran through each neuron and the outputs of each neuron are added
together to yield the final score. Since each neuron returns values in
the range of -1.0 to 1.0, the total value ranges from -2.0 to 2.0.
This section of the program could be improved as well. The patterns
need to be researched to find the optimal training images for this task.
A different angular resolution could be used in the network possibly resulting
in better recognition capabilities. Finally, it may be a good idea to weight
the sum of the outputs of the two networks. Since more images may lean
towards one pattern than the other, it doesn't make very much sense to
add the two values equally.
Back to main