
Dumb NN Prediction Accuracy
The Dumb Neural Network has achieved fairly good prediction accuracy on our dataset:
- Round 0: Pre-Flop: ~57%
- Round 1: Flop: ~63%
- Round 2: Turn: ~65%
- Round 3: Rive: ~75%

A RNN/FNN Bot
A reinforced Learning Neural network that plays poker (sometimes well), created by Nicholas Trieu and Kanishk Tantia
The PokerBot is a neural network that plays Classic No Limit Texas Hold 'Em Poker. Since No Limit Texas Hold 'Em is the standard non-deterministic game used for NN research, we decided it was the ideal game to test our network on.
When we began, we had certain objectives in mind for the network. The following include both, implementation and outcome details.
Reinforcement Learning has grown in popularity in recent years, and since Google Deepmind's AlhpaGo emerged victorious against Lee Sedol and other GO Grandmasters, Reinforcement Learning has been proven to be an effective training method for neural networks, especially in cases of deterministic and non-deterministic gameplay. Libratus, a Poker playing Neural Network developed by Carnegie Mellon University, applies Reinforcement Learning techniques along with standard backpropagation and temporal delay techniques in order to win against Poker players across the world, including the winners of past Poker Grand Tournaments. However, Libratus does not use current deep learning and reinforcement learning techniques, as outlined by the AlphaGO or Deepmind papers. We wanted to explore the possible benefits of using Q-Learning to create a poker bot that automatically learns the best possible policy through self-play over a period of time.
Q-learning is the specific reinforcement learning technique we wanted to apply to our PokerBot. A complete explanation of Q-Learning can be found here. For our purposes, it will suffice to know that:
The very first thing we did was create a "dumb" AI. Thsi was simply a series of nested if statements designed to play each game out to the best of it's ability. However, this "AI" wouldn't win any games or indeed be very effective against any opponent who knew how to counter it or knew the rules it worked on. The idea behind this AI was two-fold. First, we needed a quick and efficient method of generating millions of datasets, and since we couldn't find any reasonable datasets online, we manufactured them by using this dumb AI to simulate multiple players on the same table. Secondly, we needed a starting point for our neural network to simulate. Since finding real datasets was impossible, we decided to first have our neural network emulate our dumb AI, and then improve from there through self play and reinforcement learning.
The first thing we discovered when we started hunting for datasets: There were NO datasets. We couldn't find a freely available set of poker hands being played across, for example, a Poker Tournament, or otherwise play by play records of poker games. Why? Because professional poker players pay (try saying that fast!) a lot of money to find and analyze possible moves. Which means that data on hands is extremely valuable, and therefore quite expensive. Instead, we decided to try generating our own poker hands using the Dumb AI we created. We simply had the DumbAI play against itself repeatedly, and evaluated each hand position using the PokerStove hand evaluation library. It was a simple process, and we generated millions of hands pretty quickly.
Once we had a Dumb AI model, we began to improve it to take into account other factors, such as opponents betting histories, percentage of the total pot that the opponent and the AI had bet, and other statistical features. We wanted the Smart AI to play based on features and patterns, and not based on a set of rules, which is what the Dumb AI was doing.
Once we created a Smart AI model, we started training it using Q-Learning. We used the Dumb AI's neural network weights to begin with, but after ~10,000 epochs of training, stopped, due to extremely clear errors. The Smart AI, in an extreme case of "the only winning move is not to play" decided to fold immediately instead of playing games out to completion. This certianly minimizes the total future loss, but does not maximize reward. Therefore, due to this clear error, we decided to quit the Q-learning training.
The Structure of the network
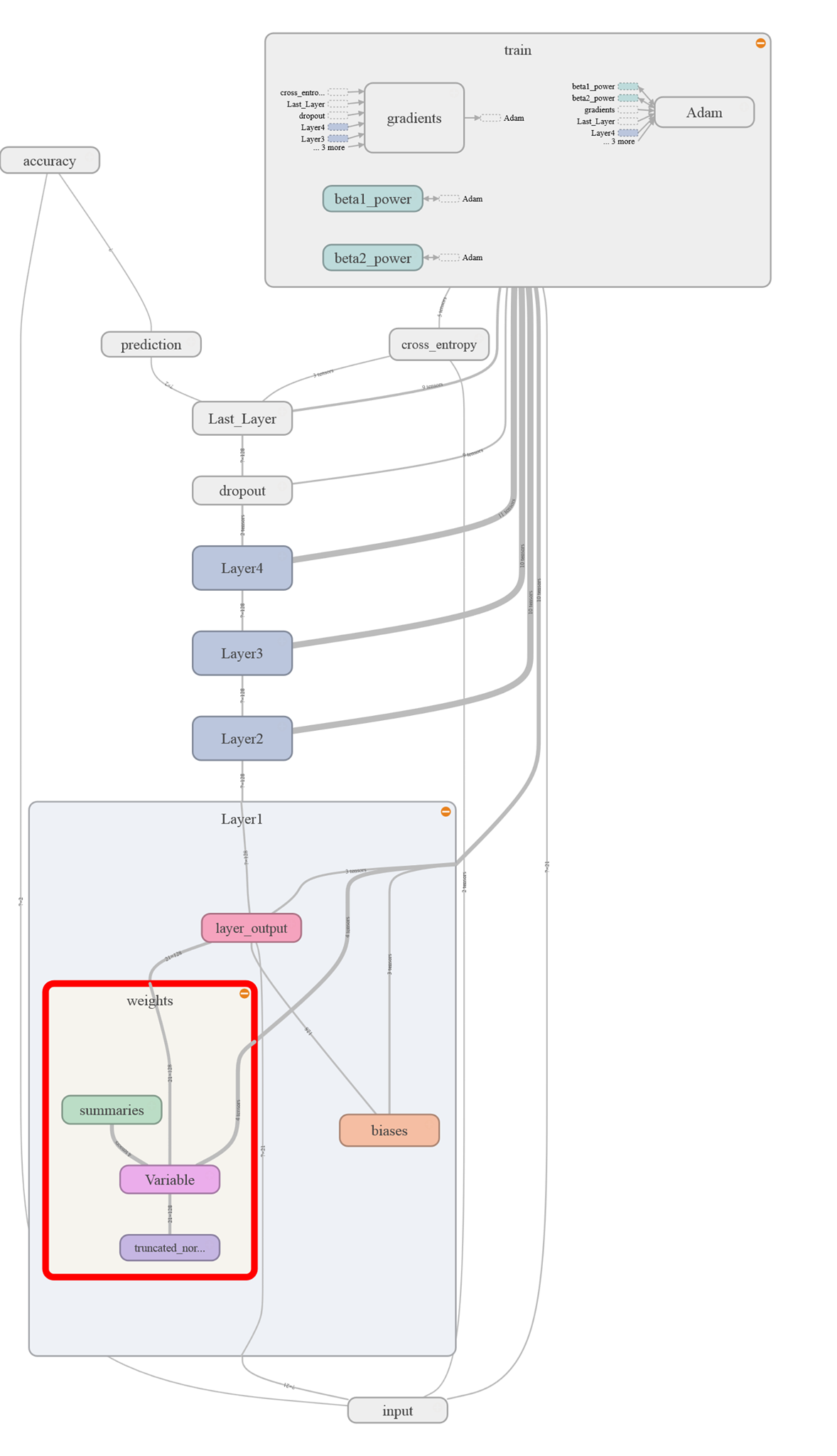
Our PokerBot has managed the following
The Dumb Neural Network has achieved fairly good prediction accuracy on our dataset:

We decided to test the networks and see if a series of expert networks for each round would perform better than a single network trained on the entire game (Keep in mind that the structure of these networks was identical.) We found that the general solo network was worse at predicting overall win/loss:

We used the Dumb Neural Network to be the value approximator for future rewards, since it had a decent win/loss prediction accuracy. However, applying Q-Learning from scratch eventually taught the network to keep folding. We have a few ideas for why this may have happened:
While not quite perfect, we're steadily making progress. Hopefully in the right direction
DeepStack implemented an excellent PokerPlaying network using conterfactual learning, but not RL. We would like to implement this counterfactual strategy within the Dumb AI before we strat training it via Reinforcement Learning.
The University of Alberta has an extremely large Poker Dataset. We would like to use that Poker Dataset or alternatively, generate better Poker Hand DataSets to improve the general feasibility and training of our Neural Network.
As a more long term goal, we'd like to implement the AlphaGo rollout tree and pruning methods, as outlined the in the DeepMind Papers. This is a longer terms strategy, but we believe that this will eventually teach our AI to play at expert levels.