Testing and Bug Discovery
Mark Kampe
$Id: testbugs.html 7 2007-08-26 19:52:08Z Mark $
1. Introduction
There are (at least) two major differences between unit testing and system
testing:
- Unit testing tends to focus on the correctness of single component
(the one I built), whereas system testing is primarily concerned
with the correct operation of the entire system.
- Unit testing tends to have a clearly bounded scope (does each
of these mechanisms operate correctly), whereas system testing
attempts to answer a more nebulous question: "is it good enough?"
It is not particularly difficult to define "necessary conditions"
for whether or not a program is "good enough". Our system requirements
and specifications give us a rich set of properties that the final
system must have. Is the sum of these enumerated requirements a
sufficient condition for shipability?
Unfortunately, testing cannot show the absence of bugs,
and the functionality and behavior of many programs
is sufficiently rich that we cannot trust a simple list of
test cases to adequately measure the product's quality.
- How many bugs were originally in this code?
- How many bugs remain in this code?
- How many of those bugs will be found by a particular testing regimen?
- How many bugs will our customers encounter when they use this product?
These are important questions, and many interesting papers have been
(and continue to be) written on this subject. This paper will present
introduction to approaches for determining how buggy a product
is, and then briefly discuss the nuanced relationship between
testing and bug discovery. It is hoped that a better understanding
of the relationship between testing and bug discovery will enable you
to more effectively plan testing activities, to estimate their efficacy,
and to more accurately assess their results.
2. Ship Criteria
If merely having completed all specified test cases cannot be
trusted as a sufficient condition for ship-worthiness, what
additional criteria must we add?
It is common for ship criteria to include additional
(more subjective) indicators of product quality. These often
include things like:
- x weeks of internal use
- x customer-days of alpha or beta testing
- positive feedback from x% of at least y users
- no severity 1 or 2 bugs
- all severity 3 bugs approved by the must-fix committee
Test results, combined with additional experiential criteria
(such as the above), can give us much greater confidence about the
quality of our product. The first three criteria listed above
are goals that can be definitively met. The problem with the
last two is that they could be satisfied on Monday morning, but
no longer hold true a few hours later. We can easily specify
criteria based on the number of open bug reports. It is not possible
to specify such criteria for the number of bugs in the product
... because we do not know how many bugs we have yet to find.
Since we cannot actually measure the bugs that we have not found,
we need some surrogate, that we can measure, and which we believe
to be well-correlated with the number of remaining (undiscovered)
bugs. Many such surrogates have been proposed:
- fraction of test cases successfully completed
It is reasonable to assume that tested code contains
far fewer bugs than untested code, and that the number
of yet-undiscovered bugs is well correlated with the
number of test cases we have not yet run. This is almost
surely true ... but it would not be valid to assume that
our test suite is 100% comprehensive, and that once we have
run all of our test cases, we will have found all bugs.
- code coverage
This is an attempt to improve on the above indicator, by
using code coverage as a measure for the thoroughness of
our testing. The improvement is a good one, but still
incomplete:
- 100% branch coverage is not 100% path coverage
- code coverage measures will not warn us about
problems in required code (e.g. error handling)
that we did not write.
- code coverage measures tell us nothing about
usability.
- code coverage is not an effective predictor for
how thoroughly we have exercised synchronization,
timing, and other dynamic interaction issues.
- bug arrival rate
Pragmatic experience has shown that the rate of bug discovery
follows a fairly predictable curve.
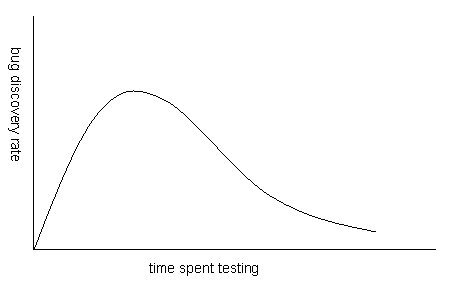
While we may not know what the maximum value on the rate
axis is, or what the scale is on the time axis, we can
surely detect the peak ... and once we have done this,
we should be able to extrapolate the rates at which bugs
will be discovered in the future.
This is well a respected predictor of undiscovered bugs.
It is also commonly included in ship criteria.
- Bug arrival rate must have been in decline for
one month, and have fallen below 1/4 of its peak rate
- Bug arrival rate for severity 1 and 2 bugs must have
fallen below 1/month.
3. Bug Discovery Rates
Why does this curve seem to have such a predictable shape, and what
determines its parameters? This is an interesting question, about
which there is still much debate.
There are many popular (at least among geeks like me) formulae
to describe the efficacy of a testing regimen. A typical one is :
where
M(t) is the number of defects (M), discovered by time (t).
A is the number of actual defects in the code.
C(t) is a coverage function, measuring what fraction of
the testable space we will have covered by time (t).
K is the efficacy of the testing technique in question
(what fraction of present bugs is it expected to find).
We will refer back to this formula as we try to understand what
factors influence bug discovery rate.
I believe that it is important to look at this curve on two scales:
- as a measure of bugs discovered by a particular test suite
- as a measure of total bug discovery
The same curve seems to apply equally well on both scales (which is
why the distinction is so seldom made), but the underlying causes are
quite different ... and those differences have very practical implications.
3.1 Bug Discovery Under a Particular Test Suite
One might think that we would run a test suite, find a bunch of
bugs, and have found them all. At time t, we run our test suite
and we find A * K bugs (K% of the A bugs that are actually present).
But it turns out that A (the number of bugs present) is not a
constant, and C(t) (our coverage function) is not a spike.
There are several factors that lead to the observed distribution:
- Ongoing test-case development.
In new products, the test cases are being written in
parallel with the code being tested. All of the test
cases are not available on day one. The increase in the
rate of bug discovery often parallels the rate of bringing
new test cases on-line.
- Ongoing product development.
Very few software products are delivered, complete, into
testing. Testing often begins as soon as there is anything
to test (to exercise the processes, to test what is available,
and to get started finding and fixing problems ASAP). The
increasing rate of new bug discovery also often parallels
the rate of code delivery.
- Blocked test-cases.
In the early stages of testing, the software may be so
failure-prone that some bugs prevent the execution of some
test cases (e.g. by causing the program to fail before that
test case can be attempted). The rate at which test cases
can be run may be limited by the rate at which (already
discovered) bugs can be fixed.
- Difficult problem isolation
Bug reports are not filed immediately after a test case
fails. The failure must be investigated, to ensure that
it is indeed a failure of the tested program and not an
error in the test case. Depending on priorities and work
loads, this investigation process can spread out over weeks
and months ... again limiting the rate at which bug reports
can be filed.
- Regression
Not all bug fixes are perfect, and some (regrettably, often a
large) fraction of bug fixes will, themselves, be faulty.
This means that new bugs will continue to be introduced
into the product (and thus become discoverable) even after
development was nominally completed.
- Non-deterministic failures
It is tempting to think of a test suite as a simple sequence of
well scripted test cases:
- prepare the inputs
- invoke the operation
- check the results against the specifications
For such a test suite (e.g. functionality, error handling,
regression testing), running it once should uncover all of
the bugs that it will ever find. There are other types
of tests (e.g. random scenarios, load and stress testing)
where this is not at all the case. For these (non-deterministic)
tests, running them longer yields greater confidence, which
yields the exponential decay in the bug report rate as testing
continues.
3.2 Bug Discovery and the Release Cycle
The previous discussion was limited to bug discovery resulting from
the execution of a single test suite. If we now zoom out to view
the entire process from development through release, we see a very
similar distribution of bug reports ... but for very different reasons.
Products are "tested" in a great many different ways:
- requirements reviews
- design reviews
- code reviews
- unit testing
- system testing
- alpha testing
- beta testing
- real customer deployment
Each of these "testing" techniques is very different from the others,
and is likely to find very different problems. Returning to our
defect discovery equation, each of these techniques has a different
coverage function (C(t)) and efficacy (K). Moreover, each of these
testing phases (especially system testing) may, itself, be comprised
of many different types of tests, each of which has its own coverage
and efficacy functions.
The "whole product" bug discovery curve is actually the sum of these
tributary curves. Each of the tributary curves tends to follow a
similar distribution (with different parameters) for the reasons
described in the previous section. It might not, however, be immediately
obvious why the sum of a series of such curves should have the
same distribution:
- If you look carefully, they don't.
The bug arrival rate curves for real products do experience
periodic bumps (associated with new testing activities),
but each bump is still followed by an exponential decay.
- There are, however, other factors that tend to replicate
a similar distribution on the larger scales.
-
In the earliest stages of the product, there is no code
and so there is little basis on which bug reports could
be filed.
-
As code becomes available, and test cases are run, the
bug arrival rate ramps up.
-
Each successive testing activity removes more defects,
and so the number of residual defects does experience
an exponential decay.
-
The deterministic test cases are defined and run
relatively early in the process. They play a very
significant role in the initial ramp-up of bug-discovery,
but quickly cease to be a source of new bugs.
-
After significant testing and use the
product quickly reaches the point where most of the
remaining bugs are:
- in untested and infrequently used operations
- in unlikely error conditions
- in unlikely timing and interaction problems
And the detection rate for these bugs should indeed
decay exponentially (as increasing exposure gives
asymptotically better confidence).
4. Testing and Bug Discovery
Different types of testing find different types of bugs.
The bug discovery rate equation attempts to capture this
with its efficacy constant (K).
-
Specification based test cases are likely to have a
high efficacy at finding bugs that compute output as
a function of input, but a relatively low efficacy
at finding bugs in the management of internal state.
-
White-box test cases are likely to have a high efficacy at
finding static algorithmic and data management errors ... but
dynamic interaction problems tend to be harder to find by
testing.
-
Targeted stress tests may be effective at finding
resource exhaustion problems and race conditions, but
are often useless for finding functionality problems.
Thus, our expectation of how many (new) bugs we will find when we
begin the next phase of testing depends on how similar the new
phase of testing is to testing that has already been done. If we
are to begin exercising the system in significantly different
ways, we should not be surprised if we experience a significant
increase in the number of bugs we discover. If we want to find
more bugs than we have already found, we are going to need to do
a different type of testing.
Different types of testing require different amounts of time.
The bug discovery rate equation attempts to capture with its
coverage function (C(t)):
-
Deterministic functionality tests can achieve complete coverage
in a single execution.
Running the same tests a billion times longer would provide no
incremental confidence.
-
The confidence gained by load and stress testing is an exponential
function of the testing time.
Ship criteria often spell out a required
number of hours (or months, years, centuries, ...)
that must be performed.
-
Random combinations (with no discernable equivalence partitions)
might accrue confidence that is only a linear function of the
testing time. Attempting to test a 64 bit multiplier in this
way would take longer than the expected life of the earth.
Understanding this should give us some basis for deciding how long
we need to run a particular type of test, before we have "squeezed
the juice out of it". Re-running a functional validation twice
might be a waste of cycles, whereas running a load-stress
suite for a second billion transactions might add considerable value.
Don't make the mistake of blindly assuming that the number of test cases
that have been run, or the number of hours that a system has been tested
can be used to predict its quality. How efficacious do we believe these
test cases are likely to be in finding the bugs we think we are likely
to have, and how much coverage do we think that our hours of testing
have bought us?
5. Testing and Confidence
Insight into the shape of real bug discovery curves is a good thing,
but what we really need is to be able to predict the discovery
rates for future products. More specifically, we want to know
how well we can use experience gained in unit and system testing
to predict the rates at which customers will encounter problems.
I suggest that it is misleading to think about software in terms
of an abstract number of residual defects (bugs not yet found):
- the shape of the defect discovery curve is only a general
trend, and results of extrapolating such a curve are imprecise.
- even if we knew how many residual defects were in the
code, this would not enable us to predict the rate at
which customers would encounter them or the severity
of the resulting errors.
Rather, I think it is more useful to think about quality assessment
in terms of confidence. How likely is it that our current estimate
of the product quality will match what the customers actually
experience?
If we believe that customers will use the system in ways that
are very similar to the ways that we have tested the system,
then we should expect the customer experience to be
an extrapolation of the current system testing results.
If, however, we believe our testing methodology to be artificial
(i.e. not particularly representative of the way that customers
will use the product), then we should expect a significant increase
in the number of reported problems when the product goes out to
real users.
If we do not believe (or are not confident) that our testing is
representative of (or at least well correlated with) the way the
product will actually be used:
- We are doing the wrong testing.
We must understand the ways in which real usage differs
from our testing, and find more representative ways of
exercising our products.
- We need real customer experience.
We need to have a carefully monitored beta program in which
we deploy a (supposedly complete) system to a full spectrum
of representative users, and see how their experience of our
product accords with (or differs from) our own testing results.
This should be the basis for our product readiness assessment.
So how are we supposed to know how representative our testing is of
the way that customers will use our software?
- We developed our requirements, so we should have some sense
of who our users are and what they are going to do with the
product.
- We designed the software, so we should have some sense of
its weaknesses, and areas where problems are most likely.
- We designed the test plans, so we should have some sense of
what aspects of program behavior are fully exercised, and
what aspects are poorly exercised.
Like so many things, Sun Tzu clearly understood this when he advised us:
-
One who knows the enemy and knows himself
will not be in danger in a hundred battles.
-
One who does not know the enemy but knows himself
will sometimes win, sometimes lose.
-
One who does not know the enemy and does not know himself
will be in danger in every battle.