By the time Ken Thompson and Dennis Richie wrote UNIX in the 1970s, file systems with fixed-sized blocks and tree-structured directories were already common. A key goal for UNIX was to provide the power and generality of larger timesharing systems (most notably Multics) with a much smaller and simpler implementation. Their original UNIX file system design provided very reasonable functionality with relatively simple mechanisms. Their file system implementation, like so many other parts of UNIX, emphasized simplicity over functionality. UNIX file systems worked pretty well, and for many years the only changes made to them were to move to larger block sizes (to provide better throughput).
Over the next decade, many users bemoaned the functional and performance limitations of the basic UNIX file system. A team of researchers at UC Berkeley decided to address these issues in their (now legendary) fourth Software Distribution (4BSD). The functionality (long file names and symbolic links) and performance (cylinder clusters and bit-map free lists) improvements were quickly adopted by all of the major UNIX vendors. Twenty years later, most standard UNIX file systems (including LINUX EXT-3) are based on the BSD (fast) file systems.
The BSD UNIX file system is worth studying because:
All file systems include a few basic types of data structures:
code to be loaded into memory and executed when the computer is powered on. MVS volumes reserve the entire first track of the first cylinder for the boot strap.
information describing the size, type, and layout of the file system ... and in particular how to find the other key meta-data descriptors.
information that describes a file (ownership, protection, time of last update, etc.) and points where the actual data is stored on the disk.
lists of blocks of (currently) unused space that can be allocated to files.
data structures that associate user-chosen names with each file.
Like most UNIX-derived file systems, BSD file systems:
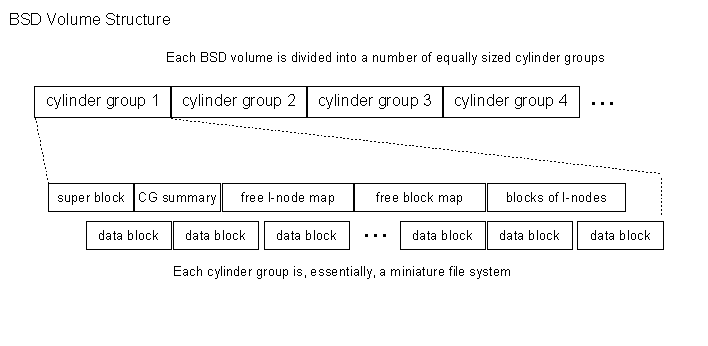
In a classic UNIX file system (UFS) the file descriptors (I-nodes) all appear near the begining of the volume, with the data blocks after them. Disk activity instrumentation showed that the disk spent a great deal of time seeking back-and forth between the I-node area and the data blocks. This led to one of the most significant changes that Berkeley made to the basic UNIX file system: the creation of cylinder groups.
Each BSD volume is divided up into a number of cylinder groups (CGs). Each cylinder group is a miniature file system ... with the intent that directory entries in a CG point to I-nodes in the same CG, which point to blocks in the same CG. To the extent this is true, a file can be opened and read with minimal head motion.
The mini-file systems are not truly independent. A directory in one cylinder group can refer to an I-node in another cylinder group, and an I-node can point to blocks on any cylinder group. When this happens, however, the system incurrs additional head motion when processing those files, and I/O performance is reduced.
All UNIX-derived file systems have a superblock that identifies the file system and defines its key parameters. In the BSD file systems (with cylinder groups) there is actually a superblock at the start of each cylinder group. The additional copies are completely redundant, but are occasionally valuable when attempting to recover data from a severely damaged file system.
The primary superblock can be found in the second block (block 1) of the volume. Realize, however, that file systems can support a wide range of bolck sizes ... so the superblock may be 512 bytes into the volume, or it may be 64K bytes into the volume (depending on what the file system block size is). When opening a new file system, the OS may have to probe multiple locations in order to find the superblock and determine the file system's block size.
The superblock contains a few basic types of information:
The superblock includes a magic number which identifies the file system type, and can be used to confirm that we have found the correct block size. There are many variants of the Berkeley file system, and most of them have different magic numbers. In addition to the basic magic number, there is usually also some version number information, indicating what features this particular file system does and does not support.
The superblock also includes a file system ID number, which can be used by system managers to uniquely label each file system (and indicate what its contents is).
In order to interpret the bits of any UNIX file system, we need to know how the file system is layed out. Because they are divided into cylinder groups, BSD file systems have many more layout parameters than most file systems:
Without knowing these parameters it would be impossible to find a particular I-node, or even a block. If a file system had 100 I-nodes, and 4,000 blocks per cylinder group:
I-nodes 101-200, and blocks 4,000-7,999 would be in cylinder group 2.
etc.
We can greatly improve file access time by allocating consecutive blocks to a file. In order to know what blocks are "consecutive", the operating system must know how long a track is, and how many tracks there are per cylinder. It is also useful to know how fast the disk spins (so we can anticipate and plan for rotational latency). Parameters like these are recorded in the superblock to enable the file system implementation to more efficiently allocate and process files.
We are often forced to make trade-offs between how rappidly we can perform various operations, and how efficiently we use space. BSD file systems have per file system tuning paremeters that permit system managers to make different trade-offs on different file systems. A temporary file system, for instance, might be optimized for allocation speed, while a project archival file system might be optimized for space efficiency or contiguous allocation. The superblock includes a collection of tunable parameters that permit system managers to optimize each file system for the way it will be used.
File system superblocks also contain a small amount of information to reflect how the file system is currently being used (or was last being used).
In addition to the file system description information in the superblock, there is some additional (per cylinder group) information associated with each cylinder group:
Each file in a UNIX file system is described by an I-node, and any file is uniquely identified by a (file system ID, I-node number) pair. All I-nodes are the same length (typically 128 bytes). As described previously, the division of a file system into cylinder groups makes the process of finding a particular I-node non-trivial.
The UNIX/POSIX file manipulation system calls presume that the same basic administrative information is associated with all files, and consequently, all UNIX-based file systems tend to have exactly the same administrative information in their I-nodes:
Most UNIX-based file systems also use a block-pointer scheme with direct, indirect, double-indirect, and tripple-indirect blocks.
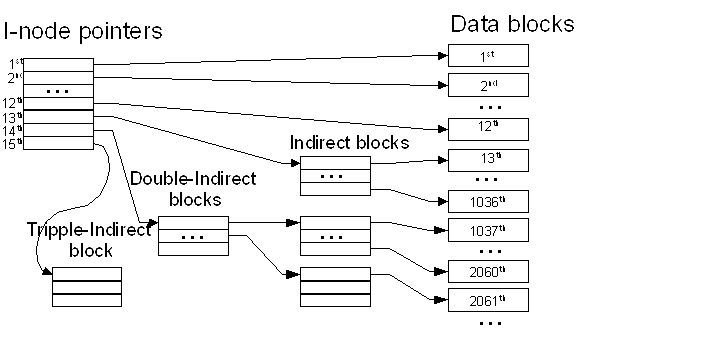
BSD file systems are fairly traditional in this respect (with twelve direct pointers, one indirect, one double-indirect, and one tripple-indirect pointer) ... but they do introduce one interesting twist: fragment blocks.
Larger block sizes improve file I/O throughput by performing a smaller number of larger transfers. Traditionally, this comes at the cost of increased internal fragmentation (since on average, half of the last block is unused). The Berkeley file system came up with an innovative solution to this problem.
In Berkeley UFS file systems, blocks can be broken into smaller fragments, which are also of a fixed size, but typically only a fraction (e.g. 1/8) as large as a block. If, after being written to and closed, a file does not fill up its last block, the last block is replaced with a smaller number of contiguous block fragments. This can give us the best of both worlds: e.g. the I/O throughput of 8K blocks, but an average internal fragmentation loss of only 512 bytes per file.
This further complicates the allocation and addressing of blocks. All of the block addresses in a file are actually fragment addresses. All of the pointers except for the last, however, refer to a full block worth of fragments. To figure out how many fragments are in the last block, the system looks at the file size, modulo the block size. This sort of complexity is probably typical of the hoops people jump through to get better throughput and storage efficiency out of a file system.
Each cylinder group contains blocks and I-nodes that can be allocated to files. Because the number of blocks and I-nodes per cylinder group is fixed, the Berkeley file system keeps track of them in a bit-map. A bit-map is a very compact representation for the state of a fixed number of objects. Each bit in the bit-map corresponds to one block (fragment) or I-node in the cylinder group.
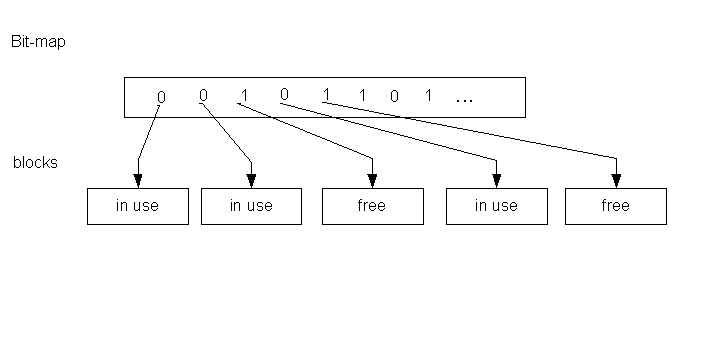
The bit-map free-list is not merely very compact. It also makes it very easy to do carving (of blocks into fragments), coalescing (of fragments back into whole blocks), and locating new blocks that are very close to the existing blocks in a file.
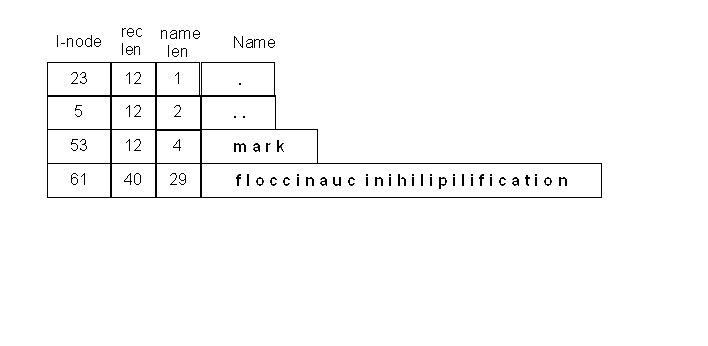
UNIX file systems associate names with I-nodes through links in directories. Each link is described by a directory entry. In the original UNIX file system, directory entries were fixed sized (16 bytes) and pretty simple:

These directory entries are called hard links because each entry contains a direct reference to the I-node for the referenced file. The I-node for a file includes a count of the number of directory links that refer to it, and when the last link is deleted (the reference count goes to zero) the I-node is actually deleted.
UNIX file systems have always supported modified hierarchical directory trees. The directories always exist in a tree (each directory has exactly one parent), but there can be multiple links to each file. By convention the first two entries in each directory were for "." a pointer to the I-node for the current directory, and ".." a pointer to the I-node for the parent directory.
A fully qualified path name can be very long (if the file is nestled deep in a directory hierarchy), but each element of the file name was limited to be 14 bytes or less. Many people complained about this limitation.
When Microsoft confronted this problem, they came up with an auxiliary directory entry scheme that could represent the extended filenames in a relatively upwards-compatible fashion. Berkeley took the opposite approach. They had introduced enough changes to the file system that they decided they were willing to change the format of directories. But, rather than merely changing all the existing UNIX programs to understand the new directory entry format, they created new system calls for walking and searching directories. The new system calls hid the underlying format of the directory entries from the applications, thus making it easier to make other changes in the future. Changing programs not to depend on the details of on-disk file system data structures is a good thing.
The new directory format uses variable length directory entries that contain variable length names. Having a separate length for the directory entry and the file name made it easier to add new information to directory entries in the future.
Another extension made to the directory entries in later systems was to include a file type field. At first blush, this might seem wrong. The file type is clearly an attribute of the file, and so belongs in a file descriptor. Why should it be included in the directory entry, whose purpose is to associate a name with a file? The answer lies in the applications that most commonly read directories. Directory viewers want to list, not only the names of each file, but their types. Doing this involved, first, reading the directory to find out what files it contained, and then opening (actually stating) each file to ascertain its type. Replicating the type information in the directory entry, sped up this process by almost an order of magnitude. Note however that the type in the directory entry is only a "hint". The true file type is recorded in the I-node.
The other major limitations of traditional UNIX directories involved the I-node number in each directory entry:
These problems were addressed by creating a new type of file, called a symbolic link. Note that there are not (in UNIX) very many file types (ordinary files, directories, pipes, special files) ... so creating a new one was a pretty big deal. A symbolic link looks very similar to an ordinary file ... but it gets very special treatment from the OS. Whenever the OS opens a symbolic link (whether in the middle of a path name or at the end of it), it looks inside the file to get the name of a file that should be opened instead, and then opens that file.
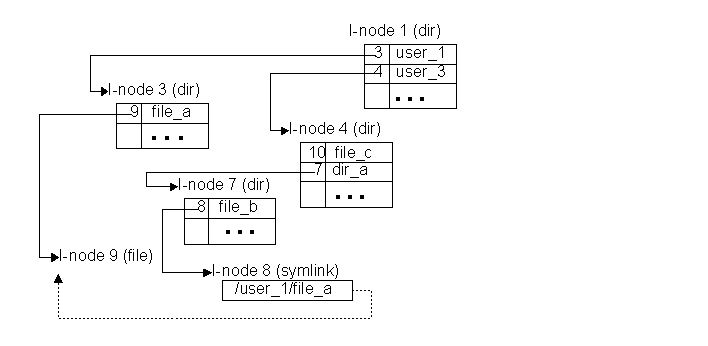
Symbolic links addressed both of the major concerns about UNIX directory entries:
Detecting loops in paths that span multiple file systems and machines is both dificult and expensive. When the Berkeley team added symbolic links to UNIX, they added a very simple feature that counts the number of I-node fetches associated with a single open ... and if that number gets too big (e.g. greater than 100) they assume that there is a loop somewhere in the symbolic links and abort the open. This is an arbitrary and imperfect test, but it seems to work pretty well.
It has often been observed that every solution should be as simple as possible, but no simpler! Traditional UNIX file systems were just a little too simple. There are a few lessons we can learn by studying BSD file systems:
The functionality requirements that motivated the BSD changes are common. The functionality, performance, and robustness supported by BSD file systems is often considered the base-line against which other file systems are judged. The decision about whether or not new features justify non-upwards compaible extensions is one that most OS vendors have had to face.
FreeBSD Sources, FFS super-block and cylinder group summaries, ffs/fs.h
FreeBSD Sources, UFS on-disk I-node, ufs/dinode.h
FreeBSD Sources, directory entries, ufs/dir.h