CS 151: Programming Assignment 4 [PAIR OPTION]
Naive Bayes Nets [90 points +10 extra credit]
due Thursday, March 12 11:55pm
This assignment was designed by Prof. Sara Sood.
Provided files for this assignment:
The purpose of this assignment is to program a simple Bayesian classifier (naive Bayes, which is a VERY simple Bayes net).
In this assignment, you will implement a Naïve Bayes Classifier
that analyzes the sentiment conveyed in text. When given a selection of
text as input, your system will return whether the text is positive,
negative, or neutral. The system will use a corpus of movie reviews as
training and testing data, using the number of stars assigned to the
each review by its author as the truth data (1 star is negative, 5
stars is positive). Depending on time, we may hold a short tournament
to test the accuracy of your systems.
Notice that I have provided a template file for this assignment,
“bayes_template.py.” Copy this file to your machine and
rename it “bayes.py” – where you will complete your
work for parts 1, 2 and 3. Create a file called
“bayes_best.py” for part 4 and put all of your reflection
and evaluation from the questions in the assignment in a file called
“reflection_evaluation.txt”. You will submit all
three files through the assignments page on Sakai.
Part 0: Overview
Recall that a Naive Bayes classifier is just a simple Bayes net that
has one root node with some number of children. The children are
connected only to the root, not to each other, as in the network shown
below:
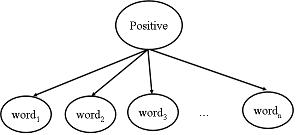
This is the Naive Bayes network we will begin with for this assignment.
In this network, all variables are Boolean. The variable
"Positive" represents whether the document is a positive review
(Positive=false means the document is a negative review), and the
variables "word_1", "word_2", ..., "word_n" represent the presence or
absence of different words in the document. The idea behind this
network is that certain words are more likely to occur in postive
documents, while others are more likely to occur in negatives ones.
However, the assumption we make is that once we know whether the
document is positive or negative, the occurance of the words in the
document become independent from one another.
Your task in this assignment will be to learn the necessary CPTs needed
to perform inference with this network, i.e. P(Positive) and
P(word_n|Positive).
Part 1: The Training Data
To train your system, you will be using data from a corpus of movie and product reviews collected from www.rateitall.com.
The reviews come from a variety of domains, e.g., movies, music, books,
and politicians and are stored in individual text files where the file
name is of the form domainnumber_of_stars-id.txt. For example, the file
“movies-1-32.txt” contains a movie review that was assigned
one star by its author, and has an id of 32. Please note that the id
number will be of no use to you for this assignment.
For your system, you will only be using reviews that had one or five
stars, where the reviews with one star are the “negative”
training data and the reviews with five stars are the
“positive” training data. I’ve provided you with two
Python functions (in the template file) to help you in using this
training data.
- loadFile – a simple Python function that takes a filename and returns a string of the file’s contents.
- tokenize – takes a string of text and returns a list of the individual words that occur in the text.
Familiarize yourself with these functions by using them at the python
interpreter to read reviews from the training data files. Take a moment
to explore the code provided in the template file so that you
don’t create extra work for yourself. Note that you might
need to use full paths on
filenames to get these functions to work.
Part 2: Training the Bayes Net [25 points]
Now that you’re familiar with the training data, your next task
is to train the classifier. As you know from your reading and from
class, a Naive Bayes classifier is just a simple Bayes Net, in this
case the one shown above.
We will use maximum likelihood parameter estimation to estimate each
parameter in the Bayes net. As a reminder, the parameters that we
need to estimate are all of the conditional and prior probabilities we
need to specify the network, which are:
- P(positive): The prior probability that a document is positive
- P(word_i|positive): The conditional probability that word_i appears, given that a document is positive, for each word_i
- P(word_i|¬postive): The conditional probability that word_i
appears, given that a document is not positive (negative), for each
word_i
Recall from class (on Tuesday, March 3) that the ML estimate for these parameters are:
P(positive) = #positive / #docs
P(word_i|positive) = (#word_i in positive documents) / (#words in positive documents)
P(word_i|negative) = (#word_i in negative documents) / (#words in negative documents)
Where #positive is the total number of positive documents, #docs is the
total number of documents, #word_i is the total frequency of word_i (in
positive or negative documents).
When training the system, instead of storing the actual parameter
estimates, you will simply calculate the frequencies needed to
calculate the parameters on the fly. In calculating these
parameter estimates, you will need to keep track of how often each word
appears in positive documents and how often each word appears in
negative documents. There are two different types of
tallies that are commonly used:
presence refers to the number of documents in the training data that
the feature occurs in and frequency
refers to the number of times that
the feature occurs in the training set (i.e. if it occurs three times
in one document, that counts as three). We will use frequency
counts for this part of the assignment to estimate parameters, but you
might experiment in part 4 with using presence counts instead.
Given all of the counts that are to be stored, Naïve Bayes
Classifiers typically use a database. However, since you are writing
this code in Python, we’ll instead use a handy Python utility
called pickle. Using pickle, one can write a data structure to a file,
and then load it back into memory later. In particular, you’ll
have two dictionaries (like hashtables), one which holds all of the
words that occur in positive documents and the frequencies at which
they occurred, and the corresponding dictionary for negative documents.
Since these dictionaries are time consuming to construct, it is useful
to only calculate them once, pickle them, and then load them into
memory the next time you need to use them.
Write a function called train that takes no parameters, and trains the system by:
- Getting the names of all of the files in the
“reviews” directory using os.walk(“reviews/”)
in the following manner (again, you might need to replace "reviews"
with the full path to your reviews directory):
lFileList = []
for fFileObj in os.walk("reviews/"):
lFileList = fFileObj[2]
break
Following the execution of the above code, the list of filenames will be stored in lFileList.
- For each file name, parse the file name and determine if it is a positive or negative review.
- For each word in the file, update the frequency for that word in the appropriate dictionary.
- Note that you should also find a way to store the counts of
positive and negative documents in the dictionaries (so you can compute
the priors).
- Save these dictionaries using “pickle” so that the
system only has to calculate them once. I’ve provided you
with two functions (save and load) to help with this step.
- Write the initialization function for the Bayes_Classifier class __init__ that does the following:
- Initializes the two dictionaries as attributes of the class.
- If the pickled files exist, then load the dictionaries into memory.
- If the pickled files do not exist, then train the system.
Part 3: Start Classifying! [30 points]
At this point, you now have all the data you need stored in memory, and
can start classifying text! Given a piece of text, the goal is
for your system to output the correct document class (i.e. positive,
negative, or neutral). In particular, you’ll calculate the
conditional probability of each document class given the features in
the target document (e.g. P(positive | word1, word2, …)) and
return the document class of the highest probability.
To classify a document, you need to find:
P(positive|word_1, word_2, ..., word_k)
That
is, the probability that a document is postive, given the words in that
document. Like any Bayes Net, the Naive Bayes classifier calculates
this probability as the product of the probability of each node in the
network, given the value for its parents. In this case:
P(positive|word_1,...,word_k) = alpha * P(positive)*P(word_1|positive)*...*P(word_k|positive)
Note,
however, that this probability ignores some information that we are given. In particular, it
only considers words that you HAVE seen in the document, and it does
not factor in the words that appearn in the Bayes net that you HAVE NOT
seen. What we're really after is:
P(positive|word_1,...,word_k,¬word_k+1,...,¬word_n) =
alpha *
P(positive)*P(word_1|positive)*...*P(word_k|positive)*P(¬word_k+1|positive)*...*P(¬word_n|positive)
where
word_k+1...word_n are words that are in the full Bayes Net (i.e.,
words seen in some document), but do not happen to appear in this
document. Effectively the simplification above is saying that we have
not observed word_k+1...word_n, i.e., we haven't seen them, but we
haven't NOT seen them either.
Reflection question #1: In your "reflection_evaulation.txt" file, answer the following question:
- Give
at least one reason why we ignore words we have not see in the document
when classifying the document (i.e., why not use the full
specification that includes words that are NOT in the document?).
Furthermore, we don't *really* care about alpha, since it is the same
for P(positive|[words_in_doc]) and P(negative|[words_in_doc]).
Thus, if you want you can ignore it and just compare the
unnormalized probabilities for positive and negative directly.
You will find that two problems will arise in building this basic
classifier. I suggest that build the classifier first, and then address
the problems, which are:
- Underflow – Because you are multiplying so many
fractions, the product becomes too small to be represented. The
standard solution to this problem is to calculate the sum of the logs
of the probabilities, as opposed to the product of the probabilities
themselves.
- Smoothing – This problem is more subtle as it won’t
produce a bug, but will throw off your
calculations. Suppose a feature (word) f does not occur at all in the
training data for negative (or positive) documents. Then our
estimate for P(f|negative)=0. This one missing word essentially
negates the influence of all other words in the document! One
word should not be given that much power in our decisions. Read
online about “add one smoothing” as a solution this
problem. Feel free to implement any smoothing algorithm you
choose.
Write a function classify that takes as input a string of text, and
returns a string of the classification – either
“positive,” “negative,” or
“neutral.” Note that in building your classifier, you only
have data to calculate the probability of a document being positive or
negative, so you’ll have to come up with some way to determine if
a document is neutral (keep it simple).
If you’ve followed my instructions, you should now have a classifier that can be used in the following manner:
>>> execfile("bayes.py")
>>> bc = Bayes_Classifier()
>>> result = bc.classify("I love my AI class!")
>>> print result
positive
Reflection Question #2: Take a
moment to celebrate your success. Try out your classifier on a few
sentences and see when it performs well and when it performs poorly.
What are three examples of sentences (or any length of text) on which
you think your classifier failed? For each example, why do you think it
failed? What was hard about the target text? Write your answers to
these questions in a file called
“reflection_evaluation.txt.”
Part 4: Improve your Classifier [15 points + 5 extra credit]
Congratulations! Once you reach this point, you will have built your
first Naïve Bayes Classifier! If the previous part, you probably
realized some ways in which you can improve upon your system. In this
part, I would like you to be creative and implement these ideas and
build your best classifier. Time permitting; we’ll hold a
competition in class to see whose classifier does best on a set of
documents that I’ll choose randomly. The outcome of this
competition will not have an impact on your grade. For this part, make
a copy of your python file and add the word “best” to the
end of the filename. This will make it easier for me to grade these
parts separately.
The most important research problem with respect to Naïve Bayes
Classifiers is the choice of features used in classification (i.e., the
children nodes in the Bayes net). Thus far, you’ve only used
“unigrams” (i.e. single words) as features. Another common
feature is “bigrams” (i.e. two word phrases). Another
feature might be the length of the document, or amount of
capitalization or punctuation used. For your best classifier, you must
include at least one other feature in your classification. For
particularly creative or ambitious classifiers, you can earn up to +5
extra credit points.
Part 5: Evaluate Your System [20 points +5 extra credit]
I’d now like you to evaluate how well your system works. In
particular, I’d like you to compare your base system (that you
completed in part 3) to your best
classifier (that you completed in part 4).
You should first use the standard measures of performace for text
classification: precision, recall and f-measure. Why three
different measures? As you've likely noticed, there is a tradeoff
between performing well on positive documents and performing well on
negative documents. That is, you could classify all positive
documents correctly simply by saying that all
documents are positive, but then you would perform very poorly on
negative documents. Precision, recall and f-measure are ways to
quantify this tradeoff.
Precision is a measure of how many irrelevant documents you included in a class. In this context it is defined as:
# of positive (or negative) documents classified as positive (negative) / total # of documents classified as positive (negative)
Recall, on the other hand, is
a measure of how many of the documents you were supposed to include in
a class actually got included in that class. In our context it is
defined as:
# of positive (or negative) documents classified as positive (negative) / total number of positive (negative) documents
For example, a Precision of 1.0 on positive documents means that all
the documents you classified as positive were actually positive (though
you might have missed some). A Recall of 1.0 on positive
documents means that you classified all positive documents as positive
(though you might have also classified some negative documents as
positive too).
Finally, f-measure is simply a way to combine recall and precision into a single number:
F = 2 * (precision * recall) / (precision+recall)
Not only should you compare
the two systems based on their precision, recall, and f-measure, but
also reflect on why you think the systems performed well (or poorly).
Outline ways that you would extend the system to improve future
performance. Consider and present other ways that you might approach
this task of classifying sentiment in text. Include your careful
evaluation and write your answers to these questions in a file called
“reflection_evaluation.txt.”
You should think carefully about your evaluation. Consider
testing your classifier on documents not included in the set I
provided. How will you tease out the specific strengths and
weaknesses of your classifier (beyond precision and recall).
Particularly
complete, creative or ambitious evaluations (e.g., comparing more than just the two classifiers) will earn up to +5 extra
credit points.