Representing a Language
Warmup, Haskell Datatypes
data Pippo = Blabla
| Azerty Double
data Xyzzy a b = Foo
| Bar Bool
| Qux a
| Thud b
| Fred (Xyzzy a b) Int
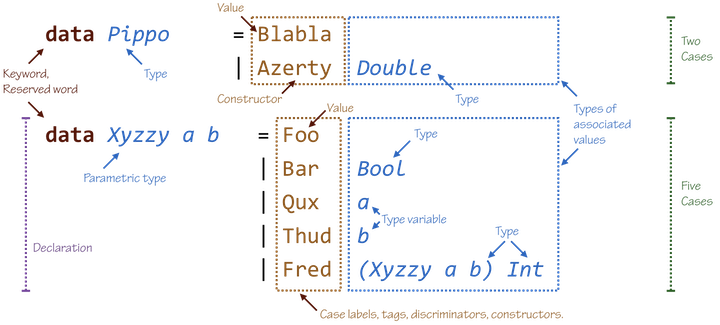
Terminology 1
Expression: computation that calculates a value- "Computation" in functional programming means evaluating expressions.
- Statements may CHANGE values, but they do not, themselves have value
- "Computation" in functional programming means executing a series of statements.
- Functional languages allow few (Racket) or no (Haskell) side-effects.
- Some people say that a statements are code with side-effects, but that's silly since that's their main goal. Statements have effects.
Identify the Expressions and Statements
In C and C++:10 * z + 4
x++;
while (x > 3) { x = x-1; y = y+1; }
Terminology 2
Syntax: What the programmer writes (or is allowed to write)- the fact that "int x;" is valid code is syntax
- the fact that the above code defines a new variable `x` as an integer is semantics
Syntax and/or Semantics?
According to the C++ standard-
^is a valid binary operator.
- When applied to two integers, the
^operator computes "bitwise exclusive-or"
- If your program adds two
intvalues and the sum is a number too big to fit anint, the results are undefined (e.g.,9223372036854775807 + 1).
- A semicolon by itself is a legal statement (a "no-op")
- The expression
new intallocates an uninitialized integer on the heap, whereasnew int()allocates the integer 0 on the heap.
Two Views of Syntax

Terminology 3
Concrete Syntax: what the programmer writes- Program as a linear sequence from a character set
- Keywords, punctuation, legal identifiers, ...
- Rules for resolving ambiguity (e.g., interpreting
3-7 * 2) - Specified by a grammar
- Programs as structured data (trees)
- Exact keywords, punctuation discarded
- No ambiguities (due to tree structure)
Variation in Concrete Syntax
| \(x \,\mapsto\, x{+}1\) | math |
| \(\lambda x.\, x{+}1\) | logic |
lambda x: x+1 |
Python |
(lambda (x) (+ x 1)) |
Scheme/Racket |
\x -> x+1 |
Haskell |
[](int x) { return x+1; } |
C++11 |
x => x+1 |
C# |
(x) => x+1 |
Dart, JavaScript 6 |
{ x in x+1 } |
Swift |
fn x => x+1 |
SML |
function x -> x+1 |
OCaml |
function(x) { return x+1; } |
JavaScript 5 |
Function[x,x+1] |
Mathematica |
Note: We're not expecting you to memorize the details concrete syntax of any non-Haskell language mentioned today. Focus on the big picture: different ways that concrete syntaxes can vary.
Wiki Extra: Variation in Concrete Syntax

Wiki Extra: Human-Friendly (?) Concrete Syntax
CobolMOVE 28 TO D(2). ADD W TO X GIVING SUM.
 DIVIDE 100 INTO Y GIVING Q REMAINDER R.
AppleScript
set my text item delimiters to (item i of theVariables) set theText to every text item of theText if class of (item i of theReplacements) is date then set my text item delimiters to my customDateStyle(item i of theReplacements) else set my text item delimiters to (item i of theReplacements) end if set theText to theText as string set my text item delimiters to ""
Wiki Extra: Expressive(?) Concrete Syntax
APL (Iverson, 1960's)
Fortress (Sun, 2000's)
Wiki Extra: Two Concrete Syntaxes in One Language
Dylan (Apple et al., 1990's)define method double(x) 2 * x; end method;or
(define-method double (x) (* 2 x))
C++ (up through C++17)
bool eq(int a, int b)
{
return !( (a < b) || (a > b));
}
or
bool eq(int a, int b) <% return not( (a < b) or (a > b)); %>
ASTs Ignore Irrelevant Details
Preserve only the important structural information from the parse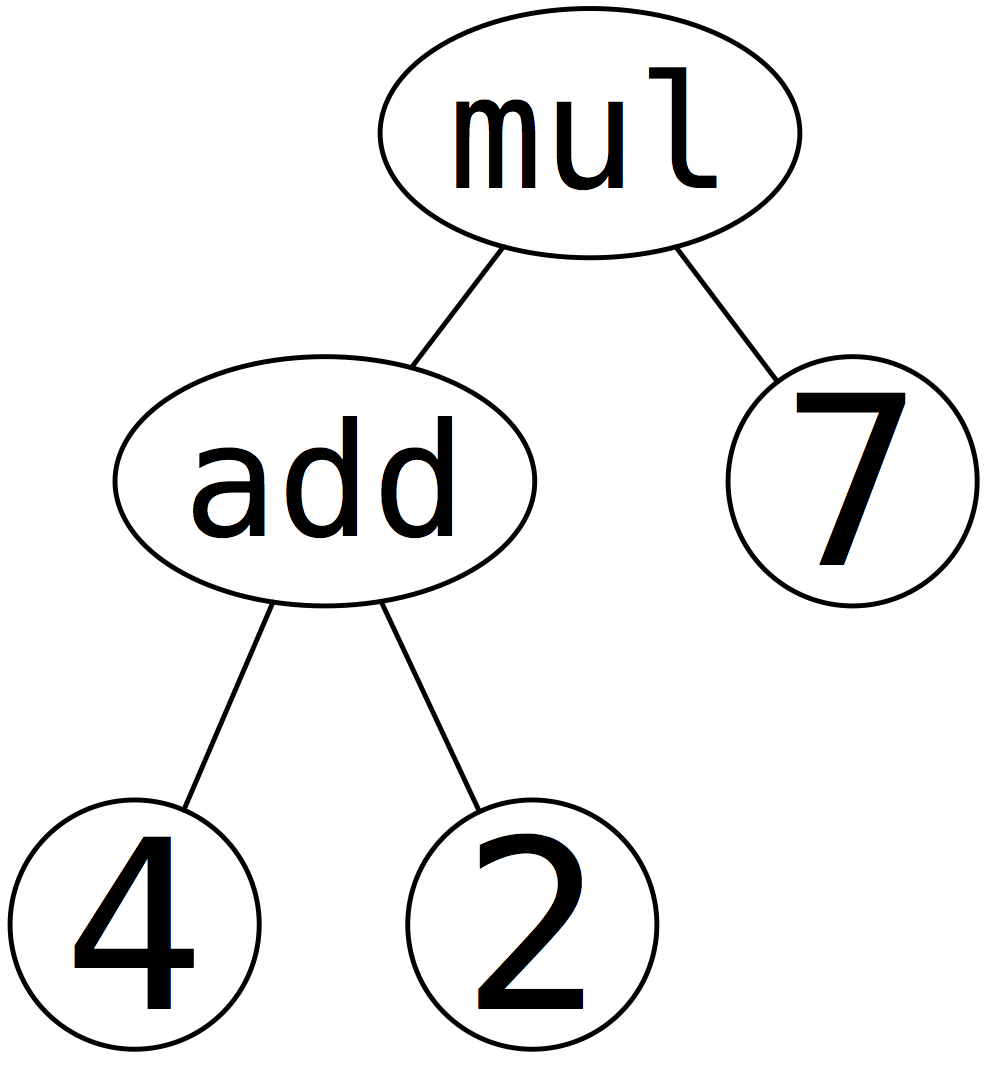 ASTs are just trees; any tree representation (from your previous experience with Racket, C++, Java, etc.) will work.
Today we'll focus on trees in Haskell
ASTs are just trees; any tree representation (from your previous experience with Racket, C++, Java, etc.) will work.
Today we'll focus on trees in Haskell
Syntax: Exercise
Write the expression below in writing in as many different ways you can: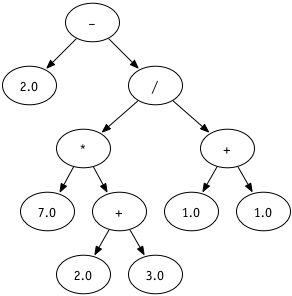 Possible options?
Possible options?
- \[ 2 - \frac{7(2+3)}{1+1} \]
-
(- 2.0 (/ (* 7.0 (+ 2.0 3.0)) (+ 1.0 1.0))) -
MINUS 2 (DIV (TIMES 7 (PLUS 2.0 3.0)) (PLUS 1.0 1.0)) -
ADD TWO AND THREE AND MULTIPLY THAT BY SEVEN, DIVIDING THE RESULT BY ONE PLUS ONE AND THEN SUBTRACT THAT RESULT FROM TWO -
SUBTRACT FROM TWO THE RESULT OF DIVIDING SEVEN TIMES THE SUM OF TWO AND THREE BY THE SUM OF ONE AND ONE - 2 7 2 3 + * 1 1 + / -
Representing Abstract Syntax
Terminology #4:
Haskell’sdata declarations (which are ideal to use in representing abstract syntax and similar structured types) have been (re)invented multiple times, called:
- Algebraic datatypes (or just datatypes)
- Specifically, sum types (whereas tuples are product types)
- Enumerations with associated values
- Variant records (or just variants)
- Tagged unions (or discriminated unions)
- Case classes (same goals, slightly different details)
Option 1: Wrong!
What's wrong with this?
data Exp = Double
| Plus Exp Exp
| Minus Exp Exp
| Times Exp Exp
| Divide Exp Exp
The datatype is missing a label for the case with the Double. - This will not cause an error, but it also won't do what you want. Haskell will just create a value for you called
Double, but it won't have any associated value.
Option 2: Inelegant!
This would be correct code:
data Exp = Num Double
| Plus Exp Exp
| Minus Exp Exp
| Times Exp Exp
| Divide Exp Exp
Extra Reminder / Example
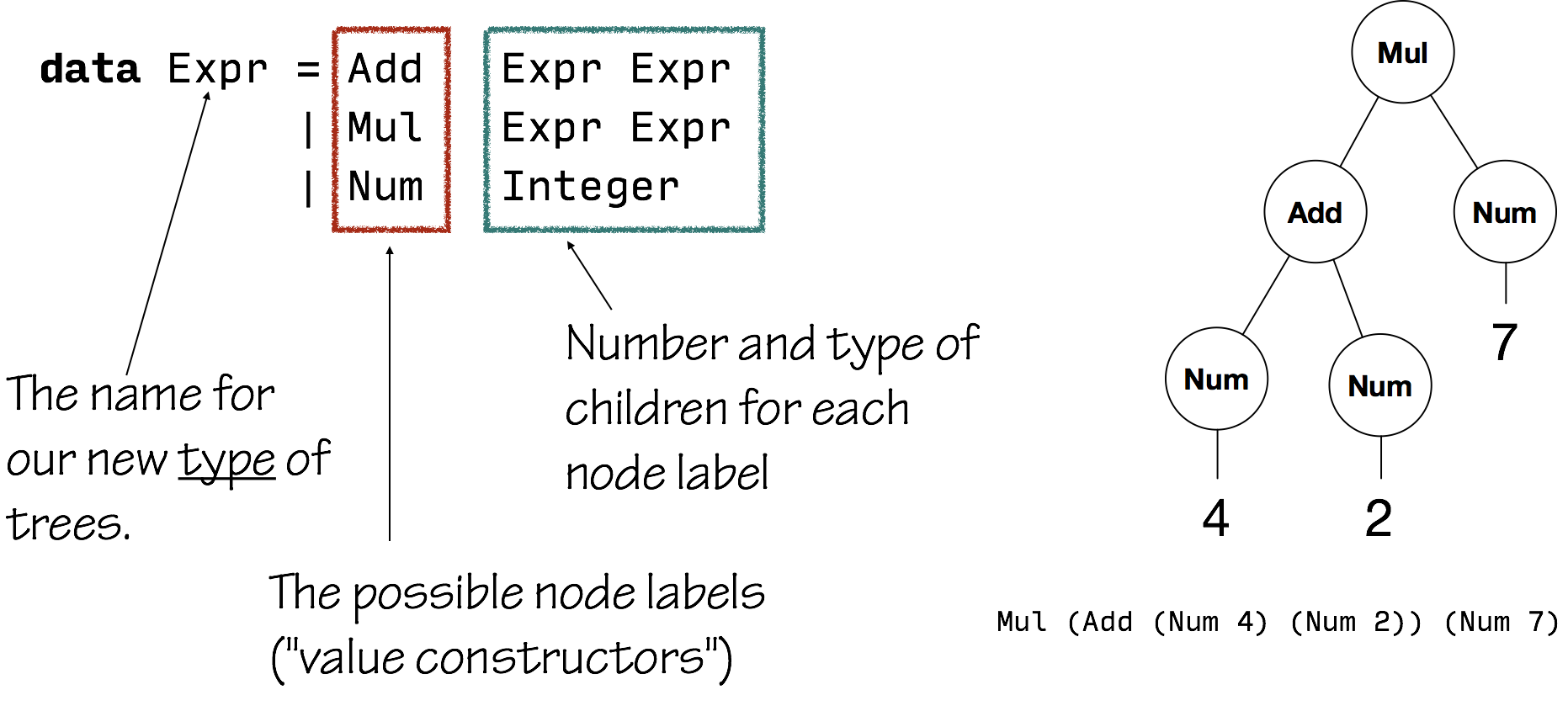
But this is a bit inelegant. There is redundancy in that we have to pattern match four different cases when we might not care what the operator is.
Option 3: Nice!
data Op = PlusOp | MinusOp | TimesOp | DivOp
data Exp = Num Double
| BinOp Exp Op Exp
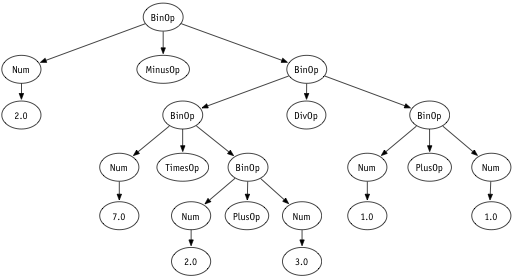 What about...
What about...
Option 4: Overgeneralizing
type Op = String
data Exp = Num Double
| BinOp Exp Op Exp
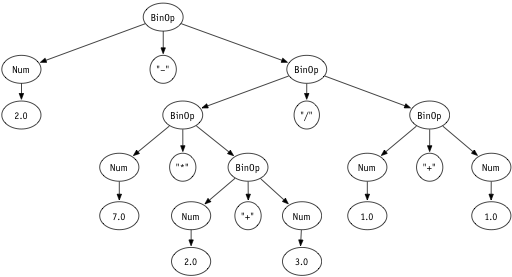 For our purposes, this is not a good implementation, because very few strings are valid operators. There are only four valid operators so it makes more sense to define a distinct
For our purposes, this is not a good implementation, because very few strings are valid operators. There are only four valid operators so it makes more sense to define a distinct Op type using data. (In a more industrial-strength and/or flexible language with user-defined operators, we might make different choices.)
Option 5: Crazy Town
Or, why not this...?
data Op = PlusOp | MinusOp | TimesOp | DivOp
data Paren = LeftParen | RightParen
data Exp = Num Double
| BinOp Exp Op Exp
| Parenthesized Paren Exp Paren
The parentheses aren't necessary since the subexpressions in the BinOp already allow us to nest expressions. - Specifically, the tree structure of
Expalready encodes the order of operations (which is what parentheses are normally used for). - Also, the way
Parenthesizedis defined allows us to make nonsensical expressions such asParenthesized RightParen? (Num 2.0) RightParen?
Let's make a (simple!) programming language...
S-K Combinators? It's simple, but a little too simple. Lambda Calculus!Lambda Calculus: Syntax
Haskell Representation
type VarName = String
data Exp = Var VarName -- variable
| Lam VarName Exp -- anonymous function
| App Exp Exp -- function application
deriving (Show)
Example
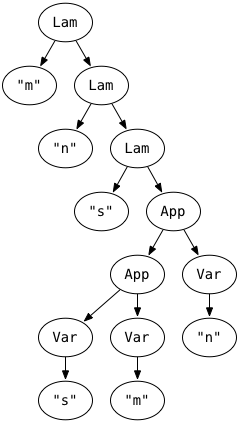
First, let's consider a simple lambda function, this is ourPAIR function:
λm.λn.λs.s m nor, more explicitly with (redundant) parentheses that's
(λm.(λn.(λs.((s m) n))))and with the space for function application clearly marked (using the ␣ character to mark spaces), that's
λm.(λn.(λs.(s␣m)␣n))In our Haskell representation of the abstract syntax, that'd be this Haskell expression.
Lam "m" (Lam "n" (Lam "s" (App (App (Var "s") (Var "m")) (Var "n"))))Drawn as a graph, that Haskell expression is:
Example: STEP from HW1
Our step function from HW1 was:
λn.n (λb.b (λt.λf.f) (λt.λf.t)) (λt.λf.f) (λf.λx.n f (n f (n f (f x)))) (n (λp.p (λm.λb.b (λb.b (λf.λx.m f (f x)) (λt.λf.f)) (λb.b m (λt.λf.t)))) (λb.b (λf.λx.x) (λt.λf.f)) (λt.λf.t))Representing this in syntax in Haskell, it's
Lam "n" (App (App (App (App (Var "n") (Lam "b" (App (App (Var "b") (Lam "t" (Lam "f" (Var "f")))) (Lam "t" (Lam "f" (Var "t")))))) (Lam "t" (Lam "f" (Var "f")))) (Lam "f" (Lam "x" (App (App (Var "n") (Var "f")) (App (App (Var "n") (Var "f")) (App (App (Var "n") (Var "f")) (App (Var "f") (Var "x")))))))) (App (App (App (Var "n") (Lam "p" (App (Var "p") (Lam "m" (Lam "b" (App (App (Var "b") (Lam "b" (App (App (Var "b") (Lam "f" (Lam "x" (App (App (Var "m") (Var "f")) (App (Var "f") (Var "x")))))) (Lam "t" (Lam "f" (Var "f")))))) (Lam "b" (App (App (Var "b") (Var "m")) (Lam "t" (Lam "f" (Var "t"))))))))))) (Lam "b" (App (App (Var "b") (Lam "f" (Lam "x" (Var "x")))) (Lam "t" (Lam "f" (Var "f")))))) (Lam "t" (Lam "f" (Var "t")))))Or as graph, that's

Operating on the λ-calculus
Remember this? \[ \newcommand{\FV}[1]{\mathrm{\mathbf{FV}}[\![\, #1 \,]\!]} \begin{array}{rcll} \FV{v} & = & \{ v \}\ & \mathrm{\ \ \ (Variables)} \\\ \FV{(M \; N)} & = & \FV{M} \cup \FV{N}\ & \mathrm{\ \ \ (Application\ of\ lambda\ expressions)}\\\ \FV{(\lambda v.M)} & = & \FV{M} \setminus \{ v \}\ & \mathrm{\ \ \ (Lambda\ abstraction)} \end{array} \] Assume you haveSet with singleton, union and difference, write freeVars in Haskell.
Reminder: These are our Haskell declarations.
data Exp = Var VarName -- variable
| App Exp Exp -- function application
| Lam VarName Exp -- anonymous function
If you want to print this page, you can click
to show all the answers.
-- MelissaONeill - 12 Feb 2020
- Current Courses
 |
|
Ideas, requests, problems regarding TWiki? Send feedback