
Context-Free Grammars (CFGs) play the role for Context-Free Languages that Regular Expressions play for Regular Languages; they give us a way to describe and characterize languages in a way that is more declarative and less reliant on a particular notion of “computation.”
Intuitively, CFGs work as follows: the grammar gives us a starting string (a single character) and a collection of replacement rules (you can replace any occurrence of this character by these characters); the question then is what strings in \(\Sigma^*\) we can generate by applying the replacement rules to the starting character a finite number of times.
A Context-Free Grammar (CFG) is specified by a 4-tuple \((\Sigma, {\cal V}, S, {\cal R})\), where
The language of the grammar is all the strings of terminals we can produce by applying the rules (as substitution steps) to the start symbol.
Consider the grammar where \(\Sigma := \{0,1\}\), \({\cal V} = \{S, A\}\), \(S\) is the start symbol, and the rules are given by: \[ \begin{array}{lcl} S\to 0S & \qquad & A\to 1A\\ S\to 1A & \qquad & A\to \epsilon\\ S\to\epsilon\\ \end{array} \] Then 001 is in the language of the grammar, because \[ S \Rightarrow 0S \Rightarrow 00S \Rightarrow 001A \Rightarrow 001 \] via the replacement rules \(S\to 0S\) [twice], \(S\to 1A\), and \(A\to \epsilon\).
Similarly \(\epsilon\) is in the language of the grammar, as is 111. In general, the language of this grammar is \[ \{\ 0^i1^j\ |\ i,j\geq 0\ \} \] because all and only those strings of 0’s and 1’s can be generated by the replacement rules starting from \(S\).
It is common to abbreviate the grammar if you have several rules that share the same left-hand-side, by listing the possible right-hand-side replacements separated by a vertical bar. For example, five rules of the grammar above could be written more compactly as \[ \begin{array}{l} S\to 0S\ |\ 1A\ |\ \epsilon\\ A\to 1A\ |\ \epsilon\\ \end{array} \] (“\(A\) can be replaced by \(1A\) or \(\epsilon\).”)
\[ \begin{array}{l} S\to (S)\ |\ SS\ |\ ()\\ \end{array} \] This grammar generates all properly-nested sequences of parentheses. For example, \((()())\) is in the language because \(S \Rightarrow (S) \Rightarrow (SS) \Rightarrow (S()) \Rightarrow (()())\).
There is no rule about which order we replace nonterminals, so we could have equally well finished this production sequence by saying \((SS) \Rightarrow (()S) \Rightarrow (()())\). \[ \begin{array}{l} S\to \epsilon\ |\ aSa\ |\ bSb\\ \end{array} \] This grammar generates all even-length palindromes involving a and b. For example, \(aabbaa\) is in the language because \(S \Rightarrow aSa \Rightarrow aaSaa \Rightarrow aabSbaa \Rightarrow aabbaa\).
Intuitively, an even-length palindrome is either empty; or starts and
ends with a and has a middle that is an even-length
palindrome; or starts and ends with b and has a middle that
is an even-length palindrome. ## Parse Trees
There are two annoyances about production sequences like \(S \Rightarrow (S) \Rightarrow (SS) \Rightarrow (S()) \Rightarrow (()()).\) First, there’s a lot of redundancy. We decided on the first step that the outermost characters would be matching parentheses, but then we have to repeat these same parentheses in every following step. Secondly, when we get to \((SS)\) we have to decide which \(S\) to replace first, even though we get the same result either way.
A Parse Tree is more concise (and more practical) way of demonstrating that a particular string is in the language of a grammar.
Given a grammar, a parse tree is a tree such that:
Given the grammar \[ \begin{array}{l} S\to (S)\ |\ SS\ |\ ()\\ \end{array} \] here is one possible parse tree:
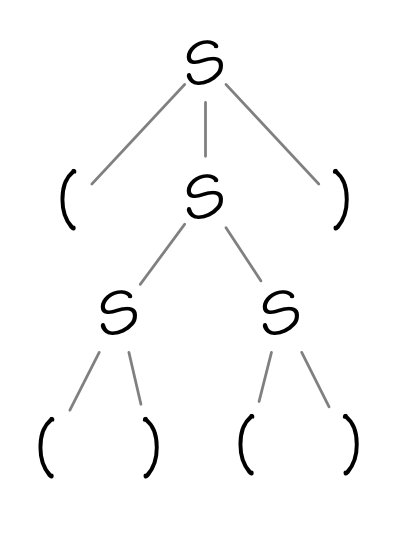
Note that every interior node is a nonterminal, and that the children of each nonterminal are the right-hand-side of a corresponding replacement rule. The leaves of a parse tree are always terminals. By reading the leaves in a left-to-right traversal, we get the corresponding string in the language.
This particular parse tree is evidence that \((()())\) is in the language of the grammar.
A grammar for strings with an equal number of 0’s and 1’s can be
given as follows: \[
\begin{array}{l}
S\to 0A\ |\ 1B\ |\ \epsilon\\
A\to 1S\ |\ 0AA\\
B\to 0S\ |\ 1BB\\
\end{array}
\] Here’s a parse tree for 001101
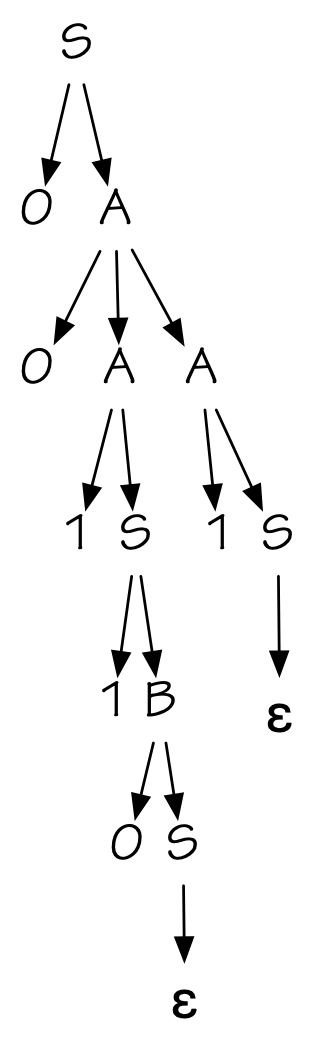
(Intuitively, this grammar works because \(S\) produces strings with equal numbers of 0’s and 1’s; \(A\) produces strings with one more 1 than 0; and \(B\) produces strings with one more 0 than 1.)
The core ideas of Context-Free Grammars were independently invented by computer scientists (under the name Backus-Naur Form, or BNF) and by the linguist Noam Chomsky. Here is a small linguistics example.
\[ \begin{array}{lcl} S&\to&\mathit{NP}\ \mathit{VP}\\ \mathit{NP}&\to&\mathrm{the}\ N\\ \mathit{VP}&\to&\mathit{V}\ \mathit{NP}\\ V&\to&\mathrm{sings}\ |\ \mathrm{eats}\\ N&\to&\mathrm{cat}\ |\ \mathrm{song}\ |\ \mathrm{canary}\\ \end{array} \] This generates sentences such as “the canary sings the song”
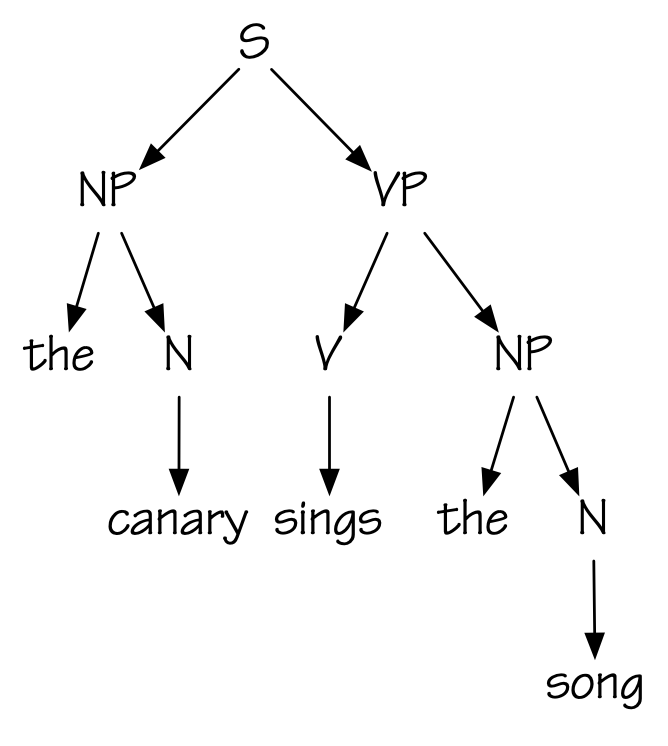
Of course, it also generates less likely sentences like “the song sings the canary” or even “the song eats the cat.”
Linguists make a distinction between grammar (whether a sentence has the proper structure), and semantics (whether the sentence makes any sense); CFGs, as their name implies, only captures the grammatical aspects of language.
Grammars are not uncommon in Computer Science, but different applications tend to use slightly different syntax. For example, in the notation we have been using so far, we might write: \[ \begin{array}{lrl} S&\to&V\ \mathtt{=}\ E\ \mathtt{;}\\ &|&\mathtt{if}\ \mathtt{(}\ E\ \mathtt{)}\ S\\ &|&\mathtt{if}\ \mathtt{(}\ E\ \mathtt{)}\ S\ \mathtt{else}\ S.\\ \end{array} \] But the same grammar in traditional Backus-Naur Form (BNF) notation might be:
<stmt> ::= <var> = <expr> ;
| if ( <expr> ) <stmt>
| if ( <expr> ) <stmt> else <stmt>Where nonterminals are written using words in angle brackets, and
::= replaces the arrow.
And formal specifications of C and C++ use yet another format: \[
\begin{array}{l}
\mathit{statement}:\\
\qquad\mathit{identifier}\ \mathtt{=}\ \mathit{expression}\
\mathtt{;}\\
\qquad\mathtt{if}\ \mathtt{(}\ \mathit{expression}\
\mathtt{)}\ \mathit{statement}\ \mathit{else{-}part}_\mathit{opt}\\
\\
\mathit{else{-}part}:\\
\qquad\mathtt{else}\ \mathit{statement}\\
\end{array}
\] where nonterminals are italicized words, and the
right-hand-sides are signified by indented lines. Further, lines with
the subscript \(\mathit{opt}\)
abbreviates two lines, one where the item with the subscript is present
and one where it’s absent. (\(\mathit{opt}\) is a bit like ?
in regular expressions.)
The takeaway here is just don’t be too surprised about variation in notation; the fundamental ideas of context-free grammars don’t change.
Example
Earlier we saw a verbal description of C integer constants, which was
not entirely unambiguous. By the time of the C99 standard, the designers
of C had switched to using a grammar notation, to be completely clear
and unambiguous. (They could have used regular expressions, but since
they were using grammars elsewhere in the specification, and grammars
can do anything a regular expression can do, they chose to do this part
using grammars as well.) 
Example
\[ \{\ 1^n0^n \ |\ n \geq 0\ \} \] \[ \begin{array}{lrl} S&\to&\epsilon\ |\ 1S0\\ \end{array} \]
Example
\[ \{\ a^nb^nc^md^m \ |\ n,m \geq 0\ \} \] \[ \begin{array}{lrl} S&\to&XY\\ X&\to&\epsilon\ |\ aXb\\ Y&\to&\epsilon\ |\ cYd\\ \end{array} \]
Example
\[ \{\ a^{n+m}b^nc^m \ |\ n,m \geq 0\ \} \] \[ \begin{array}{lrl} S&\to&X\ |\ aSc\\ X&\to&\epsilon\ |\ aXb\\ \end{array} \]
(since the set is equivalent to \(\{\ a^ma^nb^nc^m \ |\ n,m \geq 0\ \ \}\)
Example
\[ \{\ w\in\{a,b\}^*\ |\ w\mathrm{~has~odd~length~and~middle~}a\ \} \] \[ \begin{array}{lrl} S&\to&a\ |\ aSa\ |\ bSb\ |\ aSb\ |\ bSa\\ \end{array} \]
Example
\[ \{\ w\in\{a,b\}^*\ |\ w\mathrm{~has~odd~length}\ \} \] \[ \begin{array}{lrl} S&\to&a\ |\ b\ |\ aSa\ |\ bSb\ |\ aSb\ |\ bSa\\ \end{array} \]
Example
\[ \{\ w\in\{a,b\}^*\ |\ w\mathrm{~has~even~length}\ \} \] \[ \begin{array}{lrl} S&\to&\epsilon\ |\ aSa\ |\ bSb\ |\ aSb\ |\ bSa\\ \end{array} \]
Previous: 6.10 CFLs
Next: 6.12 Parsing