The Context-Free Languages include the Regular languages and more,
but not all languages are Context-Free.
For example, \(\{\ a^nb^n\ |\ n\ge 0\ \
\}\) is Context-Free (but not Regular), but \(\{\ a^nb^nc^n\ |\ n\ge 0\ \}\) is neither
Regular nor Context-Free.
Similarly, the language \(\{\ ww^R\ |\ \
w\in\{0,1\}^{*}\ \}\) of all even-length binary palindromes is
Context-Free (but not Regular), but \(\{\ ww\
|\ w\in\{0,1\}^{*}\ \ \}\) is neither Regular nor
Context-Free.
This makes a certain intuitive sense; \(a^nb^n\) is context free because a PDA can
use the stack to store the \(a\)’s, and
then match them up with the \(b\)’s.
But \(a^nb^nc^n\) is not context-free
because once we’ve matched the \(a\)’s
with the \(b\)’s, the stack is empty
and we don’t know how to check the number of \(c\)’s.
But that’s not a proof; how do we know there’s no cleverer
way to store \(a\)’s on the stack that
lets us match the number of \(b\)’s and
\(c\)’s? To get a proof, we need to
find a property shared by all context-free languages, and then show that
the \(a^nb^nc^n\) lacks that
property.
CF-Pumping
There is no nice analogue of “Distinguishable Strings” for
context-free languages. but context-free languages still have a property
similar to (but slightly different from) the pumping property of regular
languages, and so there is a pumping lemma for context-free
languages.
Definition
Given a language \(L\) and a
“pumping length” \(p\geq 1\), we say a
string \(s\in L\) (with \(|s| \geq p\)) can be CF-pumped if
> >1. \(s = uvxyz\)
> (there are substrings \(v\) and
\(y\) inside \(s\)) >2. \(vy
\not= \epsilon\) and \(|vxy| \leq
p\)
> (\(v\) and \(y\) not both empty, not far apart) >3.
\(uv^ixy^iz \in L\) for every \(i\geq 0\)
> (\(uxz\), \(u\underline{v}x\underline{y}z\), \(u\underline{vv}x\underline{yy}z\), … all in
\(L\))
Example
If \(L := \{\ a^nb^n\ |\ n\geq 0\
\}\) and \(p := 4\), then \(~s:= \mathrm{aaabbb~}\) can be CF-pumped.
> There are many ways to show this, including > >- Set \(u=\mathrm{a}\), \(v=\mathrm{a}\), \(x = \mathrm{ab}\), \(y:=\mathrm{b}\), and \(z=\mathrm{b}\) >- Set \(u=\mathrm{a}\), \(v=\mathrm{aa}\), \(x = \epsilon\), \(y:=\mathrm{bb}\), and \(z=\mathrm{b}\) >- Set \(u=\mathrm{aa}\), \(v=\mathrm{a}\), \(x = \mathrm{bb}\), \(y:=\mathrm{b}\), and \(z=\epsilon\) > >In all cases \(|vxy|\leq 4 = p\) and \(uv^ixy^iz\in L\) for every \(i\geq 0\).
The Pumping Lemma
for Context-Free Languages
The utility of this definition comes from the following fact:
Lemma
Pumping Lemma for CFLs
If \(L\) is a context-free language,
then there exists \(p\geq 1\) such that
every string \(s\in L\) with \(|s|\geq p\) can be CF-pumped. > More
importantly the contrapositive holds; if for every \(p\geq\) there is a string \(s\in L\) with \(|s|\geq p\) that cannot be
CF-pumped, then \(L\) is not
context-free.
Example
The language \(L := \{\ a^nb^nc^n\ |\ n
\geq 0\ \}\) is not context-free. >
Proof.
>Let \(p \geq 1\) be given.
>Put \(s := a^pb^pc^p\). Note that
\(s\in L\) and \(|s|\geq p\).
>To show: \(s\) is not
CF-pumpable.
>Let \(s := uvxyz\) be any partition
of \(s\) into five parts with \(vy\not=\epsilon\) and \(|vxy|\leq p\). > There are five cases
for \(vxy\): > >1. \(vxy\) contains all \(a\)’s; >2. \(vxy\) contains all \(b\)’s; >3. \(vxy\) contains all \(c\)’s; >4. \(vxy\) contains \(a\)’s and \(b\)’s; >5. \(vxy\) contains \(b\)’s and \(c\)’s; > \(vxy\) cannot contain \(a\)’s and \(b\)’s and \(c\)’s, because \(|vxy|\leq p\) and the \(a\)’s and \(c\)’s have \(p\)\(b\)’s in-between them. In all five cases,
it is clear that \(uv^2xy^2z\) will
increase the count of one or two letters (whatever letters occur in
\(vxy\)) but not all three, and so
\(uv^2xy^2z\not\in L\). > >Thus
no partition works to pump \(s\).
By the Pumping Lemma for Context-Free Languages, \(L\) is not regular.
Example
The language \(L := \{\ ww\ |\ \
w\in\{0,1\}^{*} \}\) is not context-free. >
Proof.
Let \(p \geq 1\) be given.
Put \(s := 0^p1^p0^p1^p\). Note that
\(s\in L\) and \(|s|\geq p\). To show: \(s\) is not
CF-pumpable.
Let \(s := uvxyz\) be any partition of
\(s\) into five parts with \(vy\not=\epsilon\) and \(|vxy|\leq p\). > > There are three
cases for \(vxy\): > >1. \(vxy\) is entirely in the first half of
\(s\); then \(uv^2xy^2z\not\in L\) because we have
changed the first half but not the second half of the string, and \(uv^2xy^2z\) does not have the form \(ww\); >2. \(vxy\) is entirely in the middle (\(1^p0^p\)) part of \(s\); then \(uv^2xy^2z\not\in L\) because we have
changed the number of 1’s in the first half and/or the number of 0’s in
the second half, and \(uv^2xy^2z\) does
not have the form \(ww\); >3. \(vxy\) is entirely in the second half of
\(s\); then \(uv^2xy^2z\not\in L\) because we have
changed the second half but not the first half of the string, and \(uv^2xy^2z\) does not have the form \(ww\). > The fact that \(|vxy|\leq p\) rules out any other
possibility. > Thus no partition works to pump \(s\).
By the Pumping Lemma for Context-Free Languages, \(L\) is not regular.
Extra: Justifying
the Pumping Lemma for CFLs
We don’t need to know the proof of the Pumping Lemma for CFLs in
order to use it effectively. But it is not hard to see why it is true,
once you know the trick.
Lemma
Pumping Lemma for CFLs
If \(L\) is a context-free language,
then there exists \(p\geq 1\) such that
every string \(s\in L\) with \(|s|\geq p\) can be CF-pumped. >
Proof.
Suppose \(L\) is a context-free
language with grammar \(G=(\Sigma,{\cal
V},S,{\cal R})\). > Then there is a value \(p\) (depending on the number of
nonterminals \(|{\cal V}|\) in the
grammar and the maximum “branchiness” of parse trees in this grammar)
such that every string \(s\) with \(|s|\geq p\) is so long, that its parse tree
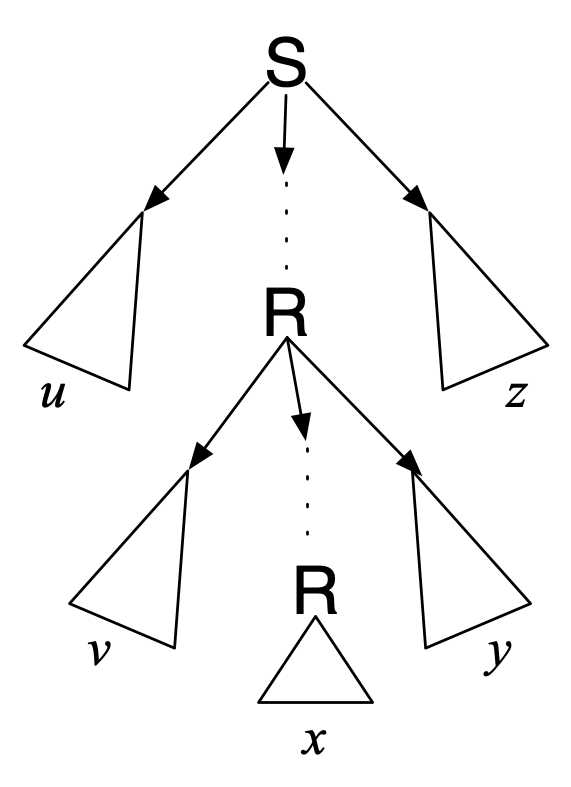
is so tall, that there is a path with at least \(|{\cal V+1}|\) nonterminals. > By the
Pigeonhole Principle, this means that given an arbitrary \(|s|\geq p\), a parse tree for \(s\) has a path where some nonterminal \(R\) appears more than once: > > So there is
a big legal subtree with \(R\) at the
root, and a small legal subtree with \(R\) at the root. > When a parse tree
contains a node \(R\), any valid
subtree (anything the grammar allows us to derive from \(R\)) can appear below it. It follows (by
“tree surgery”) that infinitely many other legal parse trees must exist,
including: > > Since these are all valid
parse trees, the corresponding strings (of the form \(uv^ixy^iz\)) must also be in the language
\(L\). > > (The \(|vxy|\leq p\) condition in the theorem can
be guaranteed as long as we pick the duplicate nonterminal \(R\) that appears “lowest” in the parse
tree.)
 > So there is
a big legal subtree with \(R\) at the
root, and a small legal subtree with \(R\) at the root. > When a parse tree
contains a node \(R\), any valid
subtree (anything the grammar allows us to derive from \(R\)) can appear below it. It follows (by
“tree surgery”) that infinitely many other legal parse trees must exist,
including: >
> So there is
a big legal subtree with \(R\) at the
root, and a small legal subtree with \(R\) at the root. > When a parse tree
contains a node \(R\), any valid
subtree (anything the grammar allows us to derive from \(R\)) can appear below it. It follows (by
“tree surgery”) that infinitely many other legal parse trees must exist,
including: > 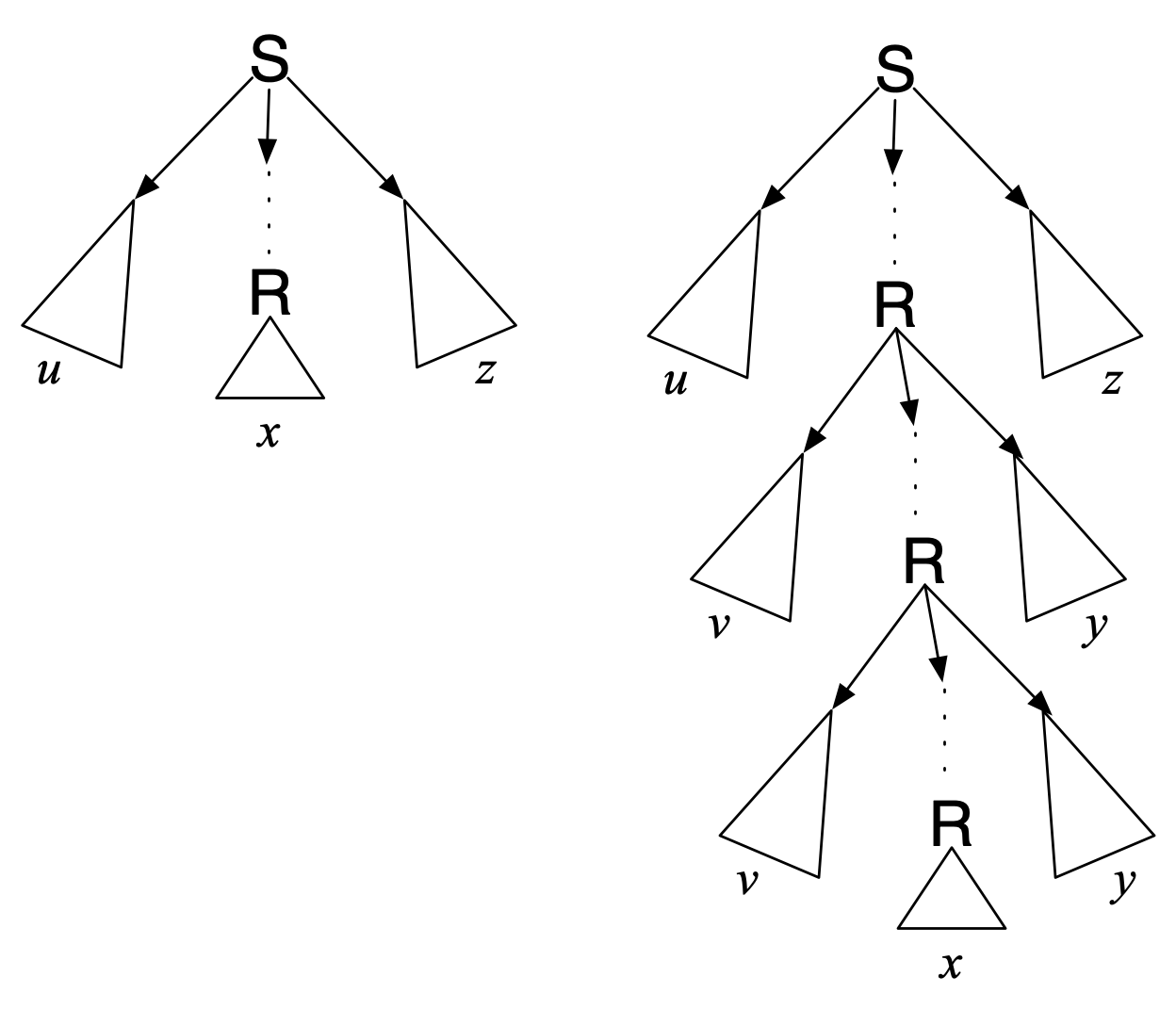 > Since these are all valid
parse trees, the corresponding strings (of the form \(uv^ixy^iz\)) must also be in the language
\(L\). > > (The \(|vxy|\leq p\) condition in the theorem can
be guaranteed as long as we pick the duplicate nonterminal \(R\) that appears “lowest” in the parse
tree.)
> Since these are all valid
parse trees, the corresponding strings (of the form \(uv^ixy^iz\)) must also be in the language
\(L\). > > (The \(|vxy|\leq p\) condition in the theorem can
be guaranteed as long as we pick the duplicate nonterminal \(R\) that appears “lowest” in the parse
tree.)