
Adaptive Query Processing for Crowd-Powered Database Systems
NSF funded project. See funding section below for details.
Project Overview
Goals and Challenges
Hybrid human-machine query processing systems, such as crowd-powered
database systems, aim to broaden the scope of questions users can ask
about data by incorporating human computation to support queries
that may be subjective and/or require visual or semantic interpretation.
In this work, we focus on filtering data with predicates evaluated by people.
While traditional database systems use cost-based optimization to devise
a low-cost query execution plan, in a hybrid system statistics that an optimizer
would use, e.g., predicate cost and selectivity, are not available at run time.
The goal of this project is to develop an adaptive query processing approach for filter queries that learns the relevant optimization statistics as the query is running and adjusts the execution plan accordingly. In such an adaptive approach, the choice of which predicate a human worker should evaluate next for an item is decided on-the-fly, with the aim of minimizing the number of tasks that workers must complete. The challenges include devising an effective strategy for estimating statistics that considers the characteristics of human computation and crowdsourcing platforms. For example, query cost can include both latency and number of worker votes to reach concensus; crowd platforms are a dynamic environment in which workers come and go and can choose how many tasks they want to complete.
Results
In our HCOMP 2017 paper, we describe an adaptive
approach called Dynamic Filter
for dynamically reordering filtering predicates. Adapted from work on Eddies by
Avnur and Hellerstein, Dynamic Filter uses a lottery scheduling algorithm to learn the
relative predicate selectivities and costs as the query is running and adjusts the
order in which it chooses the next task to give to a human worker; a task consists of
asking the worker if a given item satisfies a given predicate. We use simulations to
show that Dynamic Filter requires fewer tasks to process queries than a baseline
algorithm that randomly chooses a predicate for each task, as well as algorithms that
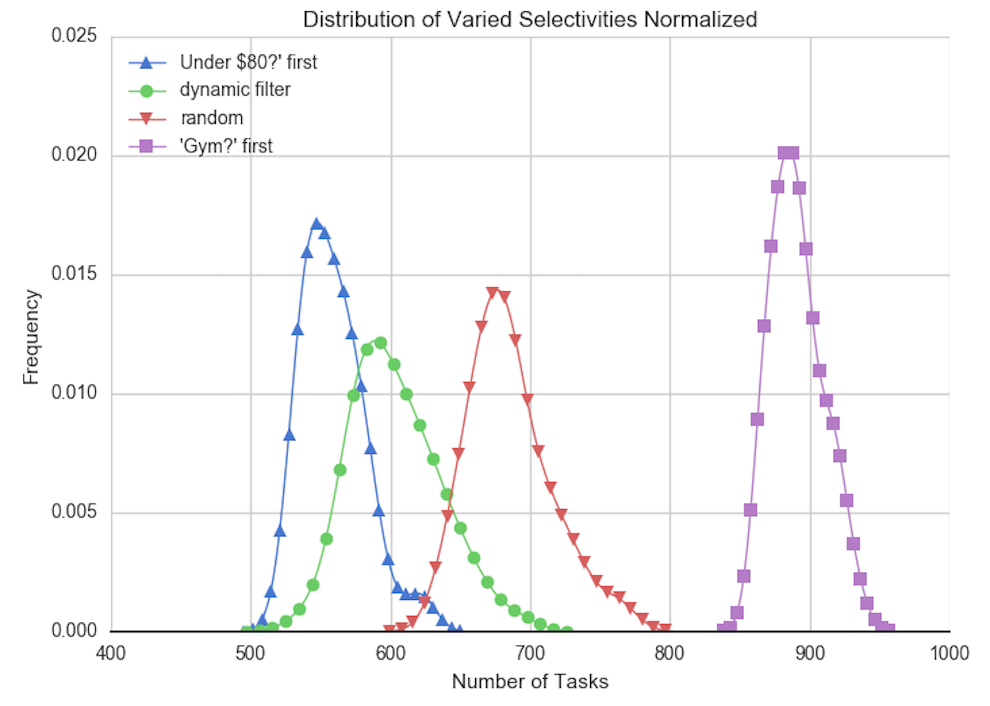
use a fixed predicate ordering for the duration of the query. For example, the figure
below shows the distribution of total tasks required for Dynamic Filter and the
baseline algorithms for a two-predicate query on hotel data. The baselines are:
random, fixed order of predicate 1 then predicate 2, and fixed order of
predicate 2 then predicate 1.
In this query, the two predicates have similar cost but different selectivities.
See the paper for more!
Our simulations use a data set of real worker responses for predicates about hotels and restaurants that we previously collected using Amazon's Mechanical Turk.
We also extended this project to consider filtering predicates that have a particular form: when the filtering predicate refers to a secondary list of items that in turn has its own filtering criterion. A filter with this form can be transformed into a join with the secondary list, with the aim of reducing overall query cost. The challenges are to determine the query plan space that now includes a join and a secondary filter and characterize the costs of these possible plans. We refer to the untransformed version of such a filtering predicate a "joinable filter".
We devise two alternative query plans for a joinable filter: the item-wise join and the pre-filter join. See these query plans (and their variants) and cost expressions in our poster abstract "Crowdsourced Joins for Filter Queries". With deeper exploration of variants of the item-wise join, we find that that a query plan that first enumerates the secondary list, evaluates the secondary predicate, and then finds matches in the primary list can outperform the joinable filter when the secondary predicate is selective. More details of this result appear in our abstract "Adaptive Query Processing with the Crowd: Joins and the Joinable Filter".
The code for this project is available at github.com/trush/dynamicfilter
Presentations and Publications
Students have shared their progress on this project at a variety of venues. On campus at Harvey Mudd, they have given research talks during the summer as well as participating in the campus-wide poster session each fall semester. They have also presented their work at an academic conference, Human Computation 2017, describing the following publication:
Doren Lan, Katherine Reed, Austin Shin, Beth Trushkowsky. Dynamic Filter: Adaptive Query Processing with the Crowd. In Fifth AAAI Conference on Human Computation, pp.118-127, 2017.
Students also presented their work at two poster sessions at academic conferences:
- "Crowdsourced Joins for Filter Queries" at the 2019 Richard Tapia Celebration for Diversity in Computing, and
- "Adaptive Query Processing with the Crowd: Joins and the Joinable Filter" at the 2019 AAAI Conference on Human Computation and Crowdsourcing.
Photo gallery:

|
|
| Ashley, Jake, Flora, and Mahlet present their work to other computer science undergraduate researchers, July 2017. | Ashley and Flora explain their work to an engineering professor during the Harvey Mudd summer research poster session, Sept. 2017. |

|

|
| Doren presents during the conference on Human Computation 2017 in Quebec, October 2017. | Anna (sitting), Cienn (green shirt, background), and Izzy (smiling) describe the project at the lab open house, summer 2018. |

|

|
| Amber and Harry present their poster during the conference on Human Computation 2019 at Skamania Lodge, WA in October 2019. | Cienn and Rebecca present their poster during the conference on Human Computation 2019 at Skamania Lodge, WA in October 2019. |
Project Funding and Personnel
This material is based upon work supported by the National Science Foundation under Grant No. 1657259, CRII: III: RUI: Adaptive Query Processing for Crowd-Powered Database Systems.
Principal Investigator: (Katherine) Beth Trushkowsky
Duration: June 2017-May 2020
A number of undergraduate students have been involved:
- Harry Aung
- Flora Gallina-Jones
- Cienn Givens
- Israel Jones
- Amber Kampen
- Doren Lan1,2
- Mahlet Melaku
- Jake Palanker
- Rebecca Qin
- Katherine Reed2
- Ashley Schmit
- Jasmine Seo
- Anna Serbent
- Austin Shin2
- Matthew Simon
1. Previously supported by an REU, grant no. 1359170
2. Also worked on project before current grant began