Results
In order to qualitatively test the network as it developed, we decided to test it periodically against a hand programmed AI which picked at random from its legal moves. The random player turns out to not be as bad as it may sound since the branching factor for a given move can never be more than 8 (unless a card is being given away instead of played) and it is often much less. Among the possible moves, there are generally several equally good ones so a random choice is likely to make sensible moves fairly often. It is quite easy for a human player to consistently beat this random player, however.
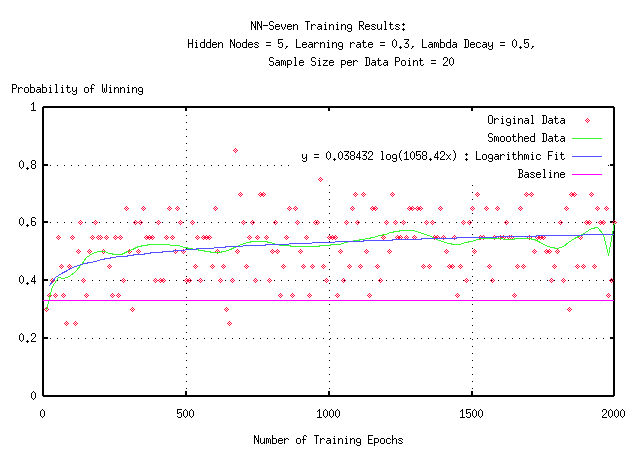
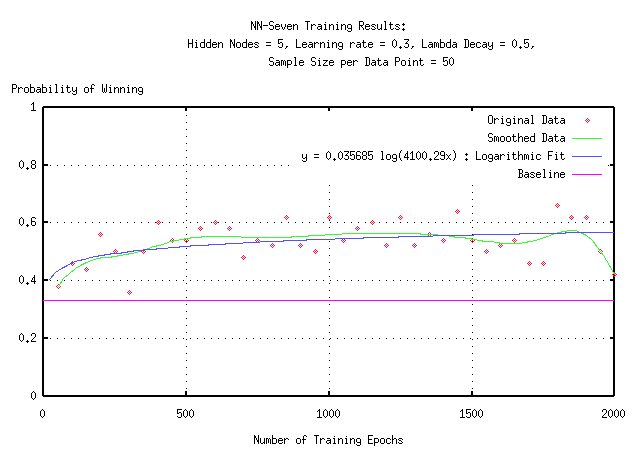
After a certain number of training epochs for the network, it was tested in a series of games against two random opponents. If the network were no better than the random players, it would be expected to win about 33% of the test games. Anything above this can be seen as clear evidence that the network has learned something about the strategy and tactics of the game. The figures below show such an improvement. The first graph shows a run where the network was tested every 10 epochs with a series of 20 games. As you can see, this turned out the be too few games to account for the variations that random deals introduce. The smoothed fit and logarithmic fits both seem to illustrate a general upward trend consistently above the 33% baseline, but the data is unclear due to the high variance. The second graph is much more clear. It was generated by testing the network every 50 epochs with a series of 50 games. The variance is much lower here and it is clearer that the fitted lines really do match the data.
Discussion
We can see from the data that the network is winning about 58% of the games after 2,000 training epochs. If we extrapolate out to 20,000 epochs (the number of training epochs used for the JavaScript interface network) the network should be winning about 61% of games against random players. If we wanted to train until the network was winning about two thirds of the games, we would have to continue to around one million epochs (provided the trend continues that long.)
A more qualitative measure of the network's performance can be obtained by playing a few games against it. The network clearly plays better than a random AI player, but is still fairly easy to beat. It is evident that it has developed some strategy, however, and seems to be able to effectively block the player in some cases, allowing it to win. As a rough estimate, the network seems to play at a beginner's level with a general idea of the strategy in the game, but still making mistakes here and there that prevent it from dominating.
Future Work
The network, while a dramatic improvement over a random AI player, still leaves something to be desired of an AI opponent for a human. There are several possible causes for this performance deficit as well as possible solutions.
The most obvious possibility for improvement might be to increase the number of hidden nodes. We only used 5 throughout the course of our tests. While we would have liked to try more to see how this would affect the network's performance, we simply did not have enough computer time to complete these tests. Besides this, there are many ways that the input representation could be changed to provide additional information to the network. It is likely that this additional information would also benefit from additional hidden nodes, although the number of training epochs may also increase as a result.
One problem with the current input encoding is that the same network was used to evaluate moves which played a card as well as moves where a card was being given to an opponent. Two completely different strategies apply to these types of moves and the network doesn't have a good way of differentiating between the two since it is only evaluating the final position resulting from the moves. It may be easier for the network to learn these orthogonal strategies if separate networks are used for the two types of evaluations. This approach, however, makes it more difficult to perform network updates since it is now much harder to keep a move history and perform the learning updates in a meaningful manner.
An alternate approach would be to use the same network for both, but provide additional information about the nature of the move being evaluated since the network has no idea, at evaluation time, what move was actually made. It is just given a board position in isolation and asked to evaluate it. Other information that could be added to the input is some sort of representation of which opponents have played which cards and who specific cards have been passed to. These sorts of information, while difficult even for a human to keep track of, may prove useful in enabling the network to beat even the best humans a significant portion of the time.
Finally, the network has no concept of the rules of the game, or any idea that players take turns, etc. If this information could be effectively encoded, it might allow the network to develop more complex strategy, but these are very difficult concepts to represent so it would be quite difficult to implement these ideas.
Conclusion
Overall, the network seems to have done quite well given the limited information and training time it was given. There are obviously many additional tests and improvements which could be made, but the current results are quite promising.