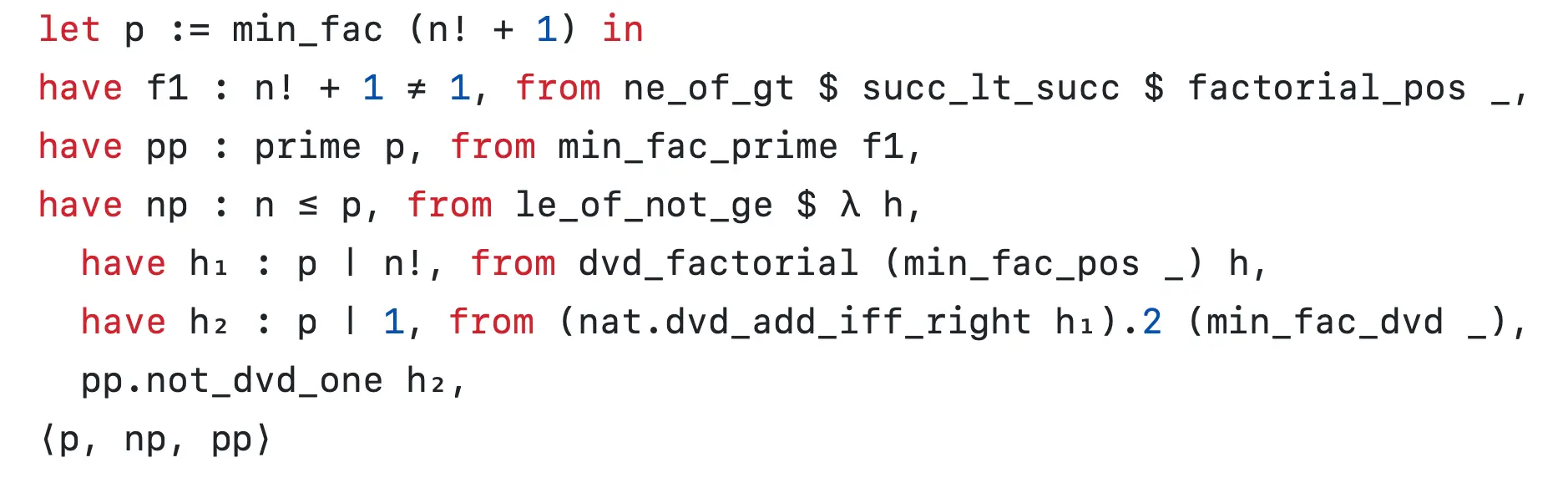
It's fine to construct “write only” proofs when we only care that the final
conclusion is true. If we just want to confirm our algorithm sorts all inputs correctly,
or that our cryptographical protocol is secure, or that our programming language is
type-safe, then any correct proof will do.
But in traditional mathematics, proofs are intended to be read and understood by humans;
they give the reader broader insights into the topic by explaining
why the result is true.
The disconnect is unfortunate. For example, the authors of the book
Homotopy Type Theory
verified all their claims using Coq before releasing
the book in 2013. Yet to this day, the authors continue receiving
reports of errors
in the theorems and proofs in their book! The problem is that the theorems and proofs in the
book were (re)written in the “traditional” fashion so readers could understand
them. These English-language proofs were not formally verified, and typos and more serious
errors slipped through.